










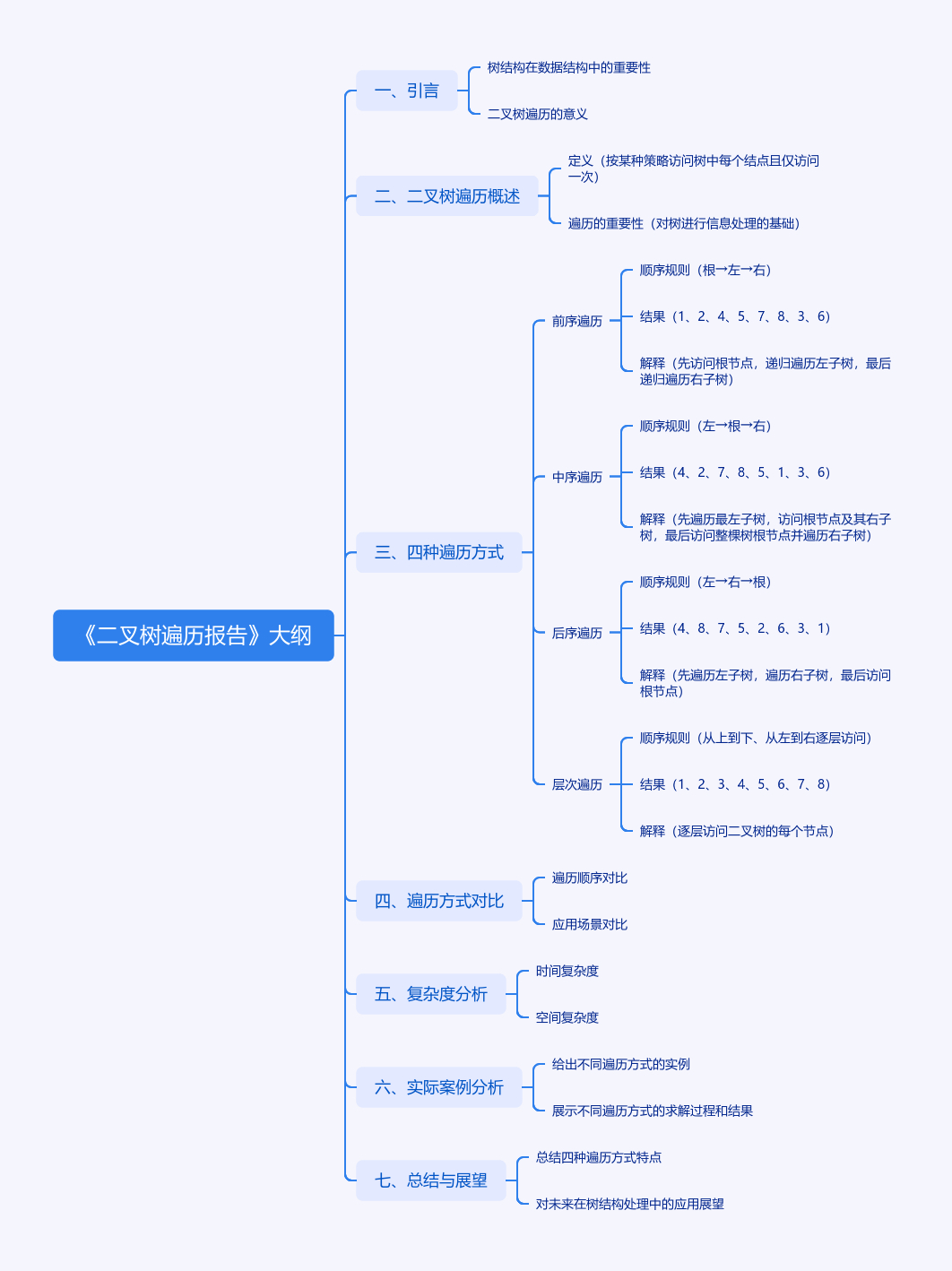
1. 前序遍历(Pre-order)
顺序规则:根 → 左 → 右
结果:1、2、4、5、7、8、3、6
解释:
- 先访问根节点 1
- 然后递归遍历左子树:2 → 4 → 5 → 7 → 8
- 最后递归遍历右子树:3 → 6
2. 中序遍历(In-order)
顺序规则:左 → 根 → 右
结果:4、2、7、8、5、1、3、6
解释:
- 先遍历最左子树:4
- 然后访问根节点 2,再访问其右子树:7 → 8 → 5
- 最后访问整棵树的根节点 1,再遍历右子树:3 → 6
3. 后序遍历(Post-order)
顺序规则:左 → 右 → 根
结果:4、8、7、5、2、6、3、1
解释:
- 先遍历左子树:4 → 8 → 7 → 5 → 2
- 然后遍历右子树:6 → 3
- 最后访问根节点 1
4. 层次遍历(Level-order)
顺序规则:从上到下、从左到右逐层访问
结果:1、2、3、4、5、6、7、8
解释:
- 第1层:1
- 第2层:2、3
- 第3层:4、5、6
- 第4层:7、8
总结一句话:
- 前序:根左右
- 中序:左根右
- 后序:左右根
- 层次:逐层从左到右
没有一种遍历方式绝对“最常用”,而是“在不同场景下各有侧重”。
从实际工程/面试/教学角度,大致可以按使用频率排序:
-
中序遍历(In-order)
• 用途最广:二叉搜索树(BST)中,中序遍历天然得到升序序列,因此几乎所有 BST 操作(查找、验证、范围查询、转双向链表等)都会用到。
• 面试高频:手写中序非递归(栈实现)几乎是算法面试必考题。 -
前序遍历(Pre-order)
• 场景:树的“克隆”、序列化/反序列化(LeetCode 297、449)、前缀表达式求值。
• 特点:根最先访问,容易拿到根信息,适合自顶向下处理问题。 -
后序遍历(Post-order)
• 场景:树的销毁、计算子树高度/大小、树的动态规划(例如求最大路径和 LeetCode 124)。
• 特点:左右子树处理完才处理根,天然适合“自底向上”递推。 -
层次遍历(Level-order)
• 场景:BFS 框架、求树高、每层最右节点、之字形打印等。
• 特点:迭代写法简单,借助队列即可,LeetCode 出现频率极高。
一句话总结
• 面试/算法题:中序 ≈ 层次 > 前序 ≈ 后序
• BST 业务代码:中序几乎必用
• BFS 场景:层次遍历最顺手
你对二叉树四种遍历方式的解释非常清晰,准确涵盖了每种遍历的核心规则和结果逻辑。二叉树的遍历是理解树结构的基础,尤其前序、中序、后序遍历(属于深度优先遍历,DFS)和层次遍历(属于广度优先遍历,BFS)的区别,对后续学习树的应用(如构建二叉树、查找节点、解决路径问题等)至关重要。
下面从“如何记忆规则”和“遍历的本质”两个角度补充说明,帮助进一步理解:
一、遍历规则的快速记忆法
-
前、中、后序遍历:
核心是**“根节点的访问时机”**,左子树永远先于右子树遍历:- 前序(Pre-order):先访问根(根在最前)
- 中序(In-order):中间访问根(根在左右之间)
- 后序(Post-order):最后访问根(根在最后)
-
层次遍历:
可以类比“从上到下扫楼梯”,每一层从左到右依次访问,类似生活中“看楼层住户”的顺序。
二、遍历的本质与实现方式
-
深度优先遍历(DFS):前序、中序、后序
- 本质:沿着树的深度优先探索,直到无法继续(叶子节点),再回溯到上一层。
- 实现:通常用栈(递归的底层也是栈),例如前序遍历的栈操作流程:
- 根节点入栈,弹出并访问;
- 右子树入栈(因栈是LIFO,右后入栈才能左先访问);
- 左子树入栈,重复步骤1-2,直到栈为空。
-
广度优先遍历(BFS):层次遍历
- 本质:沿着树的宽度优先探索,先访问完当前层所有节点,再进入下一层。
- 实现:必须用队列,例如层次遍历的队列操作流程:
- 根节点入队,弹出并访问;
- 将其左、右子节点依次入队;
- 重复弹出队头节点并加入其子节点,直到队列为空。
三、遍历结果的应用价值
已知两种遍历结果(如中序+前序/后序),可以唯一还原二叉树(前提是树中无重复节点):
- 例如,已知中序遍历
4、2、7、8、5、1、3、6和前序遍历1、2、4、5、7、8、3、6:- 前序的第一个节点
1是根节点; - 中序中
1左侧是左子树(4、2、7、8、5),右侧是右子树(3、6); - 递归对左、右子树重复上述步骤,即可还原整棵树。
- 前序的第一个节点
这一特性在二叉树的序列化、反序列化(如数据存储与传输)中非常重要。
通过理解遍历规则和实现逻辑,能更轻松地应对二叉树相关的算法题(如求深度、找路径、判断对称等),是学习树结构的核心基础。



















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











