




In the previous post, we introduced KV caching, a common optimization of the inference process of LLMs that make compute requirements of the (self-)attention mechanism to scale linearly rather than quadratically in the total sequence length (prompt + generated completions).
More concretely, KV caching consists to spare the recomputation of key and value tensors of past tokens at each generation step by storing (”caching”) these tensors in GPU memory as they get computed along the generation process.
KV caching is a compromise: we trade memory against compute. In this post, we will see how big the KV cache can grow, what challenges it creates and what are the most common strategies used to tackle them.
How big can the KV cache grow?
This is quite simple: for each token of each sequence in the batch, we need to store two vector tensors (one key tensor and one value tensor) of size d_head for each attention head of each attention layer. The space required by each tensor parameter depends on the precision: 4 bytes/parameter in full-precision (FP32), 2 bytes/parameter in half-precision (BF16, FP16), 1 byte/parameter for 8-bit data types (INT8, FP8), etc.
Let be b the batch size, t the total sequence length (prompt + completion), n_layers the number of decoder blocks / attention layers, n_heads the number of attention heads per attention layer, d_head the hidden dimension of the attention layer, p_a the precision. The per-token memory consumption (in bytes) of the KV cache of a multi-head attention (MHA) model is:
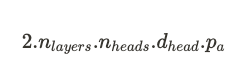
Notice: We remind that in MHA models, n_heads.d_head=d_model but we won’t use it to simplify the formula above.
The total size of the KV cache (in bytes) is therefore:
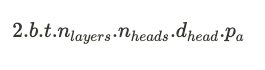
One of the first challenges of the KV cache appears: it grows linearly with the batch size and most importantly with the total sequence length. Since it grows with the total sequence length, the KV cache size is virtually not bounded while our GPU memory is obviously limited. Even worse, since the total sequence length cannot be known ahead of time, the KV cache memory requirements are therefore unknown making memory management particularly challenging.
Let’s look at some numbers for popular MHA models (Table 1), namely Meta’s Llama-2 [1] and OPT [2], MosaicML’s MPT [3] and BigScience’s BLOOM [4]:
Table 1 — Specifications of popular multi-head attention (MHA) models
Let’s assume the parameters are stored in half precision (FP16, BF16) and pick a smaller model (Llama-2–7B) and a larger one (BLOOM-176B). For Llama-2–7B (resp. BLOOM-176B), KV cache memory consumption amounts ~0.5MB/token (resp. ~4MB/token).
Let’s focus on Llama-2–7B. Using half precision, loading the model weights consumes ~14GB of memory, same as a caching keys and values for 28k tokens. 28k tokens could for example correspond to a batch of 56 sequences of length 512 which is not particularly extreme.
We can see from the numbers above that the KV cache memory consumption can grow very large and even exceed the amount of memory required to load the model weights for large sequences.
Now let’s compare these numbers to the memory capacity of common NVIDIA data center GPUs (Table 2):
Table 2 — Specifications of NVIDIA data center GPUs commonly used for training and/or serving LLMs
Let’s pick the rather cost-efficient A10 GPU, stick to Llama-2–7B and compute the maximum KV cache capacity. Once the model weights have been loaded, 24–2x7=10 GB remain available for the KV cache, i.e. ~20k tokens total capacity, prompts included, which obviously does not allow to serve a lot of concurrent requests when processing or generating long sequences especially.
We now understand that the KV cache prevents us from processing or generating very long sequences (i.e. obstacle long context windows) and/or from processing large batches and therefore from maximizing our hardware efficiency.
In that perspective, maximizing our processing capacity means having as much room as possible for the KV cache which can be achieved by:
- Reducing the model weight memory footprint (weight quantization)
- Reducing the KV cache memory footprint (cf. below)
- Pooling memory from multiple devices by sharding our model over multiple GPUs at the cost of network communication (model parallelism) or using other kind of storage like CPU memory or disk (offloading)
Since the model weights and the ever-growing KV cache have to be loaded on each forward pass, decoding steps involves very large data transfer and as we will see in the next posts, are actually memory-bandwidth bound, i.e. we actually spend more time moving data than doing useful work, i.e. compute. In such regime, latency can only be improved by either having more memory bandwidth (i.e. better hardware) or by transferring less data. Smaller model weights and KV cache free up memory for more sequence and therefore enable to increase throughput (and/or the maximum sequence length).
In that regard, memory footprint reduction strategies are triply useful as they allow us to increase our hardware utilization and therefore cost efficiency while reducing latency and increasing throughput.
Digression - Why am I billed for my input tokens? (Table 3)
Table 3 — Sample of OpenAI rates (checked on 12/01/2024)
At this point you should get a feeling as to why you are billed for both input and output tokens. Once the input prompt has been processed, i.e. at the end of the prefill phase, we have already consumed both GPU memory (to store the key and the value tensors of each input token) and compute (to pass the prompt tokens through the model).
Let’s have a look at some real numbers. Assuming the total FLOPs count of the forward pass of a P parameters model is approximately 2.P FLOPs/token [5], processing a prompt using Llama-2-7B consumes ~0.5 MB/token of GPU memory (cf. above) and ~14 GFLOPs/token of GPU compute. For a 1000 token prompt (a bit less than a two-pager), thats ~500MB of memory and 14 TFLOPs of compute and we have not generated anything yet.
Now let’s have a look at all the ways we can reduce the memory footprint of the KV cache by taking the formula above and
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











