




大家好,我是爱酱。继前两篇介绍了层次聚类和K均值聚类之后,本期我们聚焦于密度聚类(DBSCAN, Density-Based Spatial Clustering of Applications with Noise)。DBSCAN是一种强大的无监督聚类算法,能够识别任意形状的簇并自动检测异常点。本文将系统介绍DBSCAN的原理、数学表达、实际案例流程和Python代码实现,方便你直接用于技术文档和学习。
注:本文章含大量数学算式、详细例子说明及代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、DBSCAN聚类的基本思想
DBSCAN通过密度的概念定义“簇”,无需提前指定簇数,能有效处理噪声和异常点。其核心思想是:密度高的区域形成簇,密度低的区域被视为噪声。
关键概念
-
核心点(Core Point):以该点为中心、半径为
的邻域内,包含至少MinPts个点。
-
边界点(Border Point):在核心点邻域内,但自身邻域内点数不足MinPts。
-
噪声点(Noise Point):既不是核心点,也不是任何核心点邻域内的点。
-
最小邻域点数(MinPts(Minimum Points)):一个点的

二、数学定义与公式
1. 邻域
表示点
的
邻域。
2. 核心点判定
如果点 的
邻域内点数不少于MinPts,则
为核心点。
3. 密度可达与密度连接
-
密度可达:若
在
的
-
密度连接:若存在点
,使得
三、DBSCAN算法流程
-
参数选择:设定
-
遍历所有点,对每个未访问点:
-
计算其
-
若邻域内点数
MinPts,标记为核心点,创建新簇。
-
将所有密度可达的点递归加入该簇。
-
若邻域内点数
MinPts,暂时标记为噪声。
-
-
重复,直到所有点被访问。
-
输出所有簇,未归属任何簇的点为噪声点。
四、实际案例与流程
示例数据
上面笼统的定义看完了,实际派的爱酱当然会给示例大家去更好理解DBSCAN。
假设有如下二维数据点:
| 点 | ||
|---|---|---|
| A | 1 | 2 |
| B | 2 | 2 |
| C | 2 | 3 |
| D | 8 | 7 |
| E | 8 | 8 |
| F | 25 | 80 |
我们设定参数,MinPts=2。
Step 1:计算邻域
-
的
(距离1),
(距离
,不在邻域),只有
-
-
-
的
(1),只有
-
-
的
Step 2:判定核心点
-
-
-
-
Step 3:扩展簇
-
以
。
-
-
Step 4:最终聚类结果
-
簇1:
-
可合并为小簇,取决于MinPts设定)
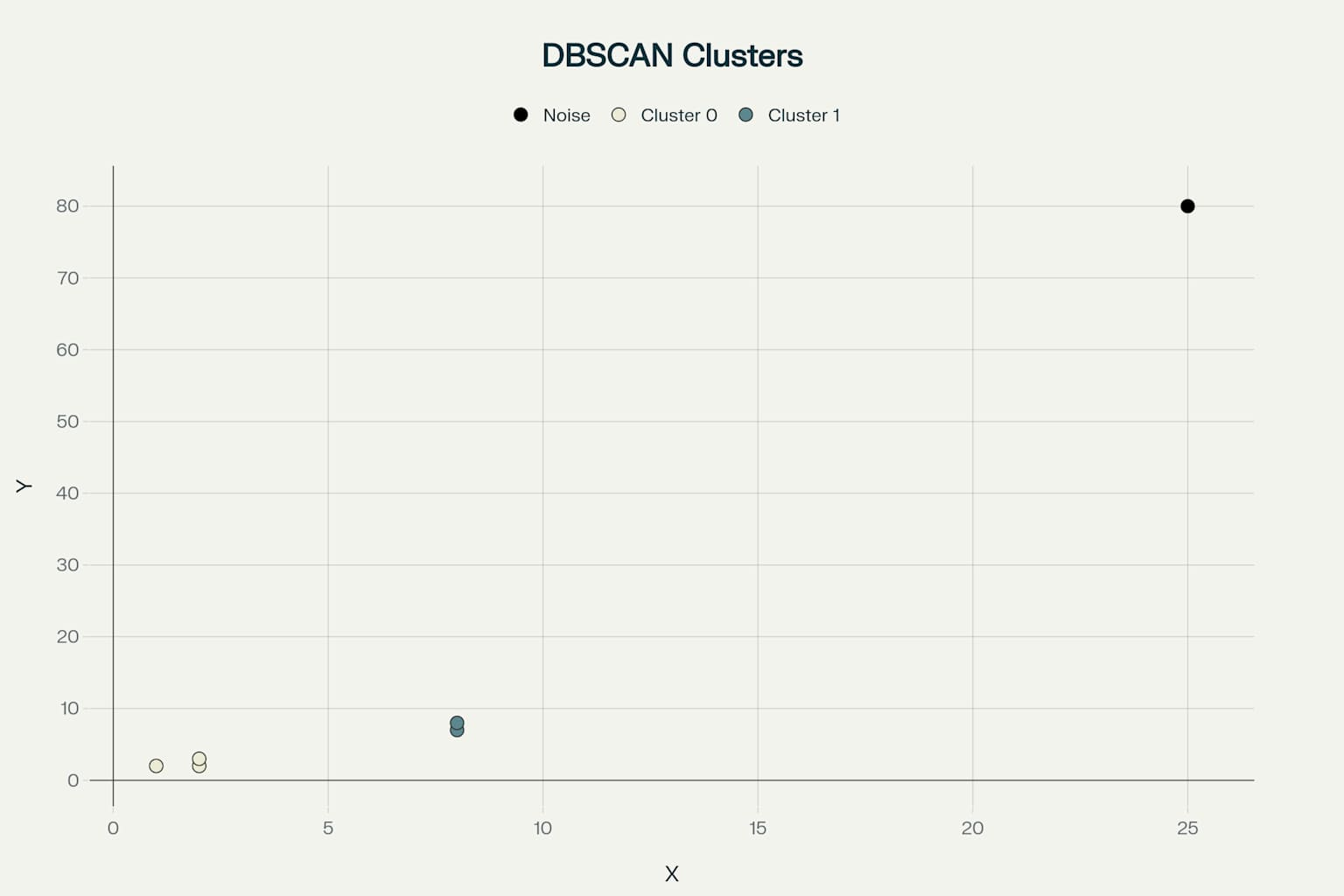
五、Python代码实现
注:记得要先 pip install scikit-learn Library喔~
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
# 示例数据
X = np.array([[1,2],[2,2],[2,3],[8,7],[8,8],[25,80]])
# DBSCAN聚类
db = DBSCAN(eps=1.5, min_samples=2).fit(X)
labels = db.labels_
plt.figure(figsize=(8,6))
unique_labels = set(labels)
# 定义颜色映射
color_map = {0: 'red', 1: 'green', -1: 'black'}
for k in unique_labels:
col = color_map.get(k, 'blue') # 其他未知簇为蓝色
class_member_mask = (labels == k)
xy = X[class_member_mask]
plt.scatter(xy[:, 0], xy[:, 1], c=col, s=100, label=f'Cluster {k}' if k != -1 else 'Noise')
plt.title('DBSCAN Clustering Result')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 代码已完成,运行后将显示DBSCAN聚类结果的散点图
六、DBSCAN的优缺点
优点
-
不需预先指定簇数
-
能发现任意形状的簇
-
能自动检测异常点(噪声)
-
对异常值鲁棒(Robust)
缺点
-
参数
-
高维(High-dimension)数据效果不佳
-
不适合密度变化很大的数据集
七、总结
DBSCAN是一种强大且实用的聚类算法,特别适合发现复杂形状的簇和异常点。实际应用中,合理选择$\varepsilon$和MinPts参数非常关键。建议结合可视化和k距离图等方法辅助参数选择。希望本篇内容能帮助你深入理解DBSCAN的原理与实操。
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

















 7499
7499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









