







 本文介绍了划分聚类、密度聚类和模型聚类三种聚类思路,重点讲解了密度聚类中的DBSCAN和OPTICS算法。DBSCAN通过核心点、边界点和噪声点的概念进行聚类,而OPTICS则引入可达距离解决确定eps参数值的问题。内容包括两种算法的原理、参数敏感性及实例展示,展示了不同参数下聚类结果的变化。
本文介绍了划分聚类、密度聚类和模型聚类三种聚类思路,重点讲解了密度聚类中的DBSCAN和OPTICS算法。DBSCAN通过核心点、边界点和噪声点的概念进行聚类,而OPTICS则引入可达距离解决确定eps参数值的问题。内容包括两种算法的原理、参数敏感性及实例展示,展示了不同参数下聚类结果的变化。
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
划分聚类、密度聚类和模型聚类是比较有代表性的三种聚类思路
1:划分聚类
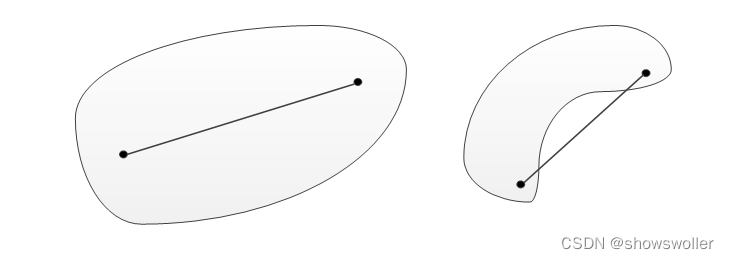
划分(Partitioning)聚类是基于距离的,它的基本思想是使簇内的点距离尽量近、簇间的点距离尽量远。k-means算法就属于划分聚类。划分聚类适合凸样本点集合的分簇。
2:密度聚类
密度(Density)聚类是基于所谓的密度进行分簇
密度聚类的思想是当邻域的密度达到指定阈值时,就将邻域内的样本点合并到本簇内,如果本簇内所有样本点的邻域密度都达不到指定阈值,则本簇划分完毕,进行下一个簇的划分。
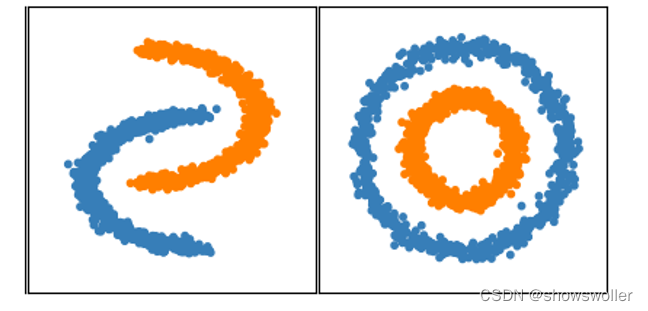
DBSCAN
DBSCAN算法将所有样本点分为核心点、边界点和噪声点,如灰色点、白色点和黑色点所示
核心点:在指定大小的邻域内有不少于指定数量的点。指定大小的邻域,一般用邻域半径eps来确定。指定数量用min_samples来表示。
边界点:处于核心点的邻域内的非核心点。
噪声点:邻域内没有核心点的点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











