






根据b站电路,自制简单汇编器
由隔壁操作系统意外发现,看到OUT %AL, %BX 指令, 怀疑寄存器直连地址线,意外追出新显示器内存,实现字符输出,并在视频最后改数字实现左右滚动跑马_哔哩哔哩_bilibili
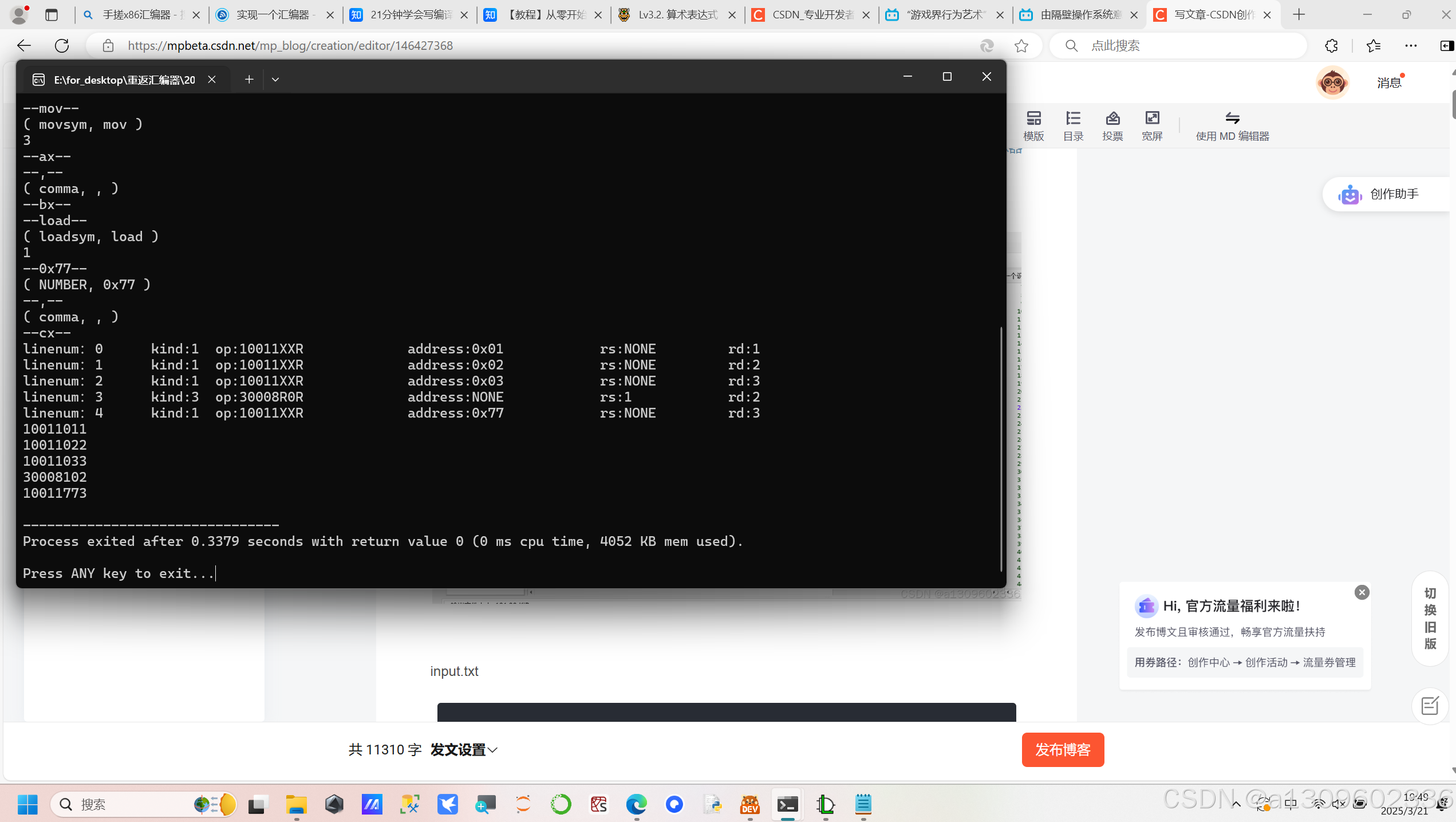
input.txt
;第一个指令测试
_start:
load 0x01,ax
load 0x02,bx
load 0x03,cx
mov ax,bx ;第一个支持注释的汇编指令
load 0x77,cx
load 0x22 ax2
;测试标签
#include <stdio.h>
#include <string.h>
//#include <ctype.h>
#define END 6 // 状态机回退检测
#define CHECK 7
#define ERROR 8
// 符号表,查标签用
typedef struct lablelist {
int linenum;
char name[20];
} lablelist;
typedef struct order {
char cmd[10];
char op[10]; // 指令填充标记
char rs[9]; // 源寄存器
char rd[9]; // 目的寄存器
char address[10];
int ident; // 记录汇编指令序号,用于覆盖字符
int lable; // 记录所属标签,用于查表
int org; // 为后续偏移准备
} order;
// 状态机设计
// 0 行不用
// 0 列不用
//列查找按代号查询
// 代号是经过合并如123456789是数字合并为1 就是第一列
//延续状态机,改终止状态,当没有字符输入时,当前状态就是要进行判断的状态
//提示,可使用如下二维数组存储DFA。
//一个状态对应一行;一个输入符号(digit/other)对应一列。
//每看到输入字符串中一个符号,就以当且状态为行号,
//看到的符号为列号查询下个状态作为当前状态。
// 以下状态机画了一周画了三次图,写了三种状态数组
int integerDFA[][7] = {
// 符号,下个状态
// space letter digit calculate border other
{0, 0, 0, 0, 0, 0, 0},
{0, 1, 2, 3, 4, 5, ERROR}, // 状态1 就绪
{0, END, 2, 2, CHECK, END, ERROR}, // 状态2 标识符
{0, END, 3, 3, END, END, ERROR}, // 状态3 数字,0b带,0x之流,后续检测字符,因只一个字母接数字后。
{0, END, END, END, 4, END, ERROR}, // 状态4 运算符,由于有+,<= 这种一个两个,所以后续还得检测<<<这样是否合法的代码
{0, ERROR, ERROR, ERROR, ERROR, ERROR, ERROR}, // 状态5 边界,;.直接结束
{0, 0, 0, 0, 0, 0, 0}, // 状态6 最先于字母结束还要再次判断最后是什么字符导致的变动,用于合规检测当前字符
{0, 0, 0, 0, 0, 0, 0}, // 状态7 同状态6,但是发现void+ 这样会有BUG,用于标识符识别为保留字再次检测符号合法否。
{0, 0, 0, 0, 0, 0, 0}, // 状态8 想新BUG,发现有¥这样字符,直接报错
};
// 12 个保留字
// 17 个汇编指令
// 改12个汇编指令
// 每个指令对应汇编,直接加一
// R:要替换的寄存器
// X:十六进制立即数
char ident[100][100] = {
"load", "10011XXR",
"mov", "30008R0R",
"nop", "00000000",
"add", "200000RR",
"jmp", "1711800R",
"cmp1", "300001RR",
"cmp2", "300a1RR",
"jmpyes", "000600XX",
"jmpram", "000200xx",
"put", "1221800r",
"send", "001100xx",
"get", "001200xx",
"pick", "100x000r", // x=2,3,4,5
"movsp", "1608800r",
"push", "00130000",
"pop", "00140000",
"call", "xxxxxxxx", // 未指定电路
"ret", "xxxxxxxx",
};
//几个伪指令
// 1个伪指令
char identv2[100][100] = {
"_start:",
};
// 11个运算符
char calculate[100][100] = {
"+",
"-",
"*",
"/",
"=",
"<>",
"<",
"<=",
">",
">=",
":=",
};
// 对应运算符序号,用于查表
char calcu[100][100] = {
"plus", "minus", "times", "slash", "eql", "neq", "lss", "leq", "gtr", "gep", "becomes",
};
// 五个界符
char board[100][100] = {
"(",
")",
",",
";",
".",
};
// 界符对应名字
char boardname[100][100] = {
"lparen",
"rparen",
"comma",
"semicolon",
"period",
};
int have = 12;
//int
int statu; // 当前状态
int old_sta; // 上一个状态
FILE* fp;
FILE* fa2;
int lenth = 1000;
char* str = new char[600]; // 循环读取文件,分200字节读取
char** cmd = new char*[lenth]; // 词元存储
int* sign = new int[lenth]; // 对应词元的标识
int cnt = 0; // 分割词元个数
int num = 0; // 当前字符填充位置
int ordercnt = 0;
int need_rigister_sour = 0; // 需要源寄存器个数
int need_rigister_dest = 0; // 需要目标寄存器
int need_address = 0; // 需要立即数个数
order *orderline = new order[5000]; // 存指令
// 是空白符
// 汇编追加tab制表符号
int isspace(char* p) {
if (*p == ' ' || *p == '\t' || *p == '\n' || *p == '\0') {
return 1;
}
return 0;
}
//是字母
// 追加'.'英文句号作为伪指令
// 追加下划线 _作为伪指令
// 追加':'作为伪指令一部分,或可加入空白符进行忽略只提取字符。
int isletter(char* p) {
if ((*p >= 'a' && *p <= 'z') || (*p >= 'A' && *p <= 'Z' || *p == '.' || *p == '_' || *p == ':')) {
return 1;
}
return 0;
// return isalpha(*p);
}
// 是数字
// 追加$作为常数符号
// 考虑到linus和x86 $符号有情况,决定回滚到原始情况,直接数字,没有别的功能
int isnum(char* p) {
if (*p >= '0' && *p <= '9') {
return 1;
}
return 0;
}
// 是calculate 是运算符
int iscalculate(char* p) {
if (*p == ':' || *p == '+' || *p == '-' || *p == '*' || *p == '/' || *p == '<' || *p == '=' || *p == '>') {
return 1;
}
return 0;
}
// 是界符号
// 汇编取消界符号'.'用于伪指令
int isborder(char* p) {
if (*p == ';' || *p == ',' || *p == '(' || *p == ')') {
return 1;
}
return 0;
}
// 查空白符号,字符,数字,运算符号,界符号,乱码字符
int transchar(char* p) {
int a = 0;
int b = 0;
int c = 0;
int d = 0;
int e = 0;
a = isspace(p);
b = isletter(p);
c = isnum(p);
d = iscalculate(p);
e = isborder(p);
if (a != 0) {
// printf("isspace\n");
return 1;
} else if (b != 0) {
return 2; // 不是return b,c,d,e,因为都是1
} else if (c != 0) {
return 3;
} else if (d != 0) {
return 4;
} else if (e != 0) {
return 5;
} else {
return 6;
}
}
//int check(char* str) {
void check(char* str) {
int checknum;
checknum = 10;
char*p = str;
// 进入字符探测,允许跳转状态
// statu = 1; // 初始化设置,全局变量
// old_sta = statu;
// 字符 '\0'也是比较对象,对应于状态机的非字符直接到结束状态。只有一个非字符就是结束符才能输出正确
do {
// 切除注释
// 地位等同于界符号,且注释后本行没有指令
if (*p == ';') {
if (num != 0) {
cmd[cnt][num] = '\0';
cnt++;
}
while (*p != '\0') {
p++;
}
break;
}
// 选状态
checknum = transchar(p);
// printf("%c\n", *p);
// printf("%d\n", checknum);
old_sta = statu;
statu = integerDFA[statu][checknum];
// printf("%d\n", statu);
// printf("%d\n",cnt);
// 字符写入
cmd[cnt][num] = *p;
num++; // 用于最后循环结束判断是否分词
if (statu == 1) {
num = 0;
}
if (statu == 5) { // 边界
// num--;
// num++;
cmd[cnt][num] = '\0'; // 填充
// printf("--%s--\n",cmd[cnt]);
sign[cnt] = 5; // 字符存储记录为边界符号
cnt++; // 下一个字符
num = 0;
statu = 1;
old_sta = 1;
} else if (statu == 6) { // 要复位
num--;
cmd[cnt][num] = '\0';
// printf("--%s--\n", cmd[cnt]);
num = 0;
if (old_sta == 2) { // 字母
sign[cnt] = 2;
} else if (old_sta == 3) { // 数字
sign[cnt] = 3;
} else if (old_sta == 4) { // 运算符号
sign[cnt] = 4;
}
cnt++;
statu = 1;
old_sta = 1;
statu = integerDFA[statu][checknum];
cmd[cnt][num] = *p;
num++;
if (statu == 1) {
num = 0;
}
if (statu == 5) { // 边界
num++;
cmd[cnt][num] = '\0'; // 填充
// printf("--%s--\n",cmd[cnt]);
sign[cnt] = 5; // 字符存储记录为边界符号
cnt++; // 下一个字符
num = 0;
statu = 1;
old_sta = 1;
}
} else if (statu == 7) {
num--;
cmd[cnt][num] = '\0';
// printf("--%s--\n", cmd[cnt]);
num = 0;
if (old_sta == 2) { // 字母
sign[cnt] = 2;
} else if (old_sta == 3) { // 数字
sign[cnt] = 3;
} else if (old_sta == 4) { // 运算符号
sign[cnt] = 4;
}
cnt++;
// statu = 0;
statu = 1;
old_sta = statu;
statu = integerDFA[statu][checknum];
cmd[cnt][num] = *p;
num++;
if (statu == 1) {
num = 0;
}
// 因为7是calculate 在标识符而来,所以*p一定是标识符,就一定不是边界
// printf("检测保留字与运算符\n");
// 发现利用状态机分词后可以根据保留字判断后续词语。
} else if (statu == 8) {
printf("ERROR 有非法字符 %c\n", *p);
}
if (*p == '\0') {
break;
}
p++;
// } while (*p != '\0');
} while (1);
statu = 1;
num = 0;
//
选状态
// checknum = transchar(p);
//
// printf("%c\n", *p);
printf("%d\n", checknum);
// old_sta = statu;
// statu = integerDFA[statu][checknum];
printf("%d\n", statu);
// // 字符写入
// cmd[cnt][num] = *p;
// num++; // 用于最后循环结束判断是否分词
//
//
// if (statu == 5) { // 边界
// cmd[cnt][num] = '\0'; // 填充
// printf("--%s--\n", cmd[cnt]);
// sign[cnt] = 5; // 字符存储记录为边界符号
// cnt++; // 下一个字符
// num = 0;
// statu = 1;
// old_sta = 1;
// } else if (statu == 6) { // 要复位
// num--;
// cmd[cnt][num] = '\0';
// printf("%d\n", old_sta);
// printf("--%s--\n", cmd[cnt]);
//
// num = 0;
// if (old_sta == 2) { // 字母
// sign[cnt] = 2;
// } else if (old_sta == 3) { // 数字
// sign[cnt] = 3;
// } else if (old_sta == 4) { // 运算符号
// sign[cnt] = 4;
// } else if (old_sta == 1) {
// sign[cnt] = 99;
// } else if (old_sta == 5) {
// sign[cnt] = 100;
// }
//
// cnt++;
// statu = 1;
// old_sta = 1;
//
// } else if (statu == 7) {
// num--;
// cmd[cnt][num] = '\0';
// printf("--%s--\n", cmd[cnt]);
//
// num = 0;
// if (old_sta == 2) { // 字母
// sign[cnt] = 2;
// } else if (old_sta == 3) { // 数字
// sign[cnt] = 3;
// } else if (old_sta == 4) { // 运算符号
// sign[cnt] = 4;
// }
// cnt++;
// statu = 1;
// old_sta = 1;
//
// } else if (statu == 8) {
// printf("ERROR 有非法字符\n");
// num = 0;
//
// } else if (statu == 1) {
// printf("回复原样\n");
// num = 0;
// }
// num=0;
}
void init_cmd() {
for (int i = 0; i < lenth; i++) {
cmd[i] = new char[200];
}
// 分词存储先清空杂乱数据
for (int i = 0; i < lenth; i++) {
for (int j = 0; j < 200; j++) {
cmd[i][j] = '\0';
}
}
cnt = 0;
num = 0;
}
void init_statu() {
statu = 1;
old_sta = 1;
}
void init_orderline() {
for (int i = 0; i < 5000; i++) {
strcpy(orderline[i].address, "NONE");
strcpy(orderline[i].cmd, "NONE");
strcpy(orderline[i].op, "NONE");
strcpy(orderline[i].rd, "NONE");
strcpy(orderline[i].rs, "NONE");
orderline[i].org = 0;
orderline[i].lable = 0;
orderline[i].ident = 0;
}
}
// 注意每次+2,由于机器码在其中
int find_reserve(char* str) {
for (int i = 0; i < have; i += 2) {
if (strcmp(str, ident[i]) == 0) {
return i + 1;
}
}
return -1;
}
// 查运算符号
int find_calculate(char* str) {
for (int i = 0; i < 11; i++) {
if (strcmp(str, calculate[i]) == 0) {
return i;
}
}
return -1;
}
// 查边界符号
int find_borad(char* str) {
for (int i = 0; i < 5; i++) {
if (strcmp(str, board[i]) == 0) {
return i;
}
}
return -1;
}
// 查伪指令
int find_identv2(char* str) {
for (int i = 0; i < 1; i++) {
if (strcmp(str, identv2[i]) == 0) {
return i;
}
}
return -1;
}
// 根据寄存器翻译成机器指令参数
char* find_rigister(char* chose) {
char* p = new char[5];
if (strcmp(chose, "ax") == 0) { // 寄存器
strcpy(p, "1");
} else if (strcmp(chose, "bx") == 0) {
strcpy(p, "2");
} else if (strcmp(chose, "cx") == 0) {
strcpy(p, "3");
} else if (strcmp(chose, "dx") == 0) {
strcpy(p, "4");
} else if (strcmp(chose, "ex") == 0) {
strcpy(p, "5");
} else if (strcmp(chose, "fx") == 0) {
strcpy(p, "6");
} else if (strcmp(chose, "gx") == 0) {
strcpy(p, "7");
} else if (strcmp(chose, "ax2") == 0) { // 寄存器
strcpy(p, "9");
} else if (strcmp(chose, "bx2") == 0) {
strcpy(p, "a");
} else if (strcmp(chose, "cx2") == 0) {
strcpy(p, "b");
} else if (strcmp(chose, "dx2") == 0) {
strcpy(p, "c");
} else if (strcmp(chose, "ex2") == 0) {
strcpy(p, "d");
} else if (strcmp(chose, "fx2") == 0) {
strcpy(p, "e");
} else if (strcmp(chose, "gx2") == 0) {
strcpy(p, "f");
} else {
strcpy(p, ""); // 发现错误字符则提示标记
}
return p;
}
// 根据指令查所需寄存器
void checkneed(int a) {
switch (a) {
case 1:
need_rigister_sour = 0;
need_rigister_dest = 1;
need_address = 1;
break;
case 3:
need_rigister_sour = 1;
need_rigister_dest = 1;
need_address = 0;
break;
default:
//TODO
break;
}
}
//
//void combine(order* orderline){
//
// if(orderline->ident==3){
// strcpy(orderline->cmd,orderline->op);
// (orderline->cmd)[7]=orderline->rd[0];
// (orderline->cmd)[5]=orderline->rs[0];
// }else{
//
// }
//}
void combine(order* orderline) {
switch (orderline->ident) {
case 1:
strcpy(orderline->cmd, orderline->op);
(orderline->cmd)[5] = orderline->address[2];
(orderline->cmd)[6] = orderline->address[3];
(orderline->cmd)[7] = orderline->rd[0];
break;
case 3:
strcpy(orderline->cmd, orderline->op);
(orderline->cmd)[7] = orderline->rd[0];
(orderline->cmd)[5] = orderline->rs[0];
break;
}
}
int main() {
fp = fopen("input.txt", "r");
fa2 = fopen("output.txt", "w");
init_cmd();
init_statu();
init_orderline();
// 分割词语
while (fgets(str, 200, fp) != NULL) {
// 利用scanf 读取吸收回车,而希冀里不能执行 '\n'的比较
// while (fscanf(fp, "%s", str) != EOF) {
// 处理回车,有些回车读取会影响代码结果
if (str[0] == '\n' && strlen(str) == 1) {
continue;
} else if (str[strlen(str) - 1 ] == '\n') { // 发现文末回车
str[strlen(str) - 1 ] = '\0';
}
// 剥离成函数使用
check(str);
// printf("%s\n",str);
}
// 对每个单词进行检查
// 这样解决不知道什么时候根据状态进行结束的问题。字符连续,没有字符了就根据状态给结论。
for (int i = 0; i < cnt; i++) {
// printf("%d\n", i);
printf("--%s--\n", cmd[i]);
// printf("%d\n", sign[i]);
if (sign[i] == 2) { // 如果是字母打头的
if (cmd[i][0] == '_') {
int a = find_identv2(cmd[i]); // 查伪指令
if (a != -1) {
printf("( IDENT, %s )\n", cmd[i]);
sign[cnt] = 2 * 100 + a;
} else {
printf("非法的伪指令 **%s**\n", cmd[i]);
}
} else {
int a = find_reserve(cmd[i]) ; // 查汇编指令
if ( a != -1) {
printf("( %ssym, %s )\n", cmd[i], cmd[i]);
sign[cnt] = 2 * 10 + a;
strcpy(orderline[ordercnt].op, ident[a]);
orderline[ordercnt].ident = a;
printf("%d\n", a);
checkneed(a); // 发现汇编指令读取数据
} else {
char p[5] = "";
strcpy(p, find_rigister(cmd[i])); // 查寄存器
if (strcmp(p, "") != 0) {
if (need_rigister_sour) {
strcpy(orderline[ordercnt].rs, p);
need_rigister_sour = 0;
} else if (need_rigister_dest) {
strcpy(orderline[ordercnt].rd, p);
need_rigister_dest = 0;
}
} else {
printf("非法的汇编指令 **%s**\n", cmd[i]);
}
}
}
} else if (sign[i] == 3) { // 如果是数字打头的
printf("( NUMBER, %s )\n", cmd[i]);
if (need_address) {
strcpy(orderline[ordercnt].address, cmd[i]);
need_address--;
} else {
printf("发现神秘数字\n");
}
} else if (sign[i] == 4) {
int a = 0;
a = find_calculate(cmd[i]);
if (a != -1) {
// printf("%d", a);
printf("( %s, %s )\n", calcu[a], cmd[i]);
} else {
printf("非法的运算符 --%s--\n", cmd[i]);
}
} else if (sign[i] == 5) {
int a = 0;
a = find_borad(cmd[i]);
if (a != -1) {
printf("( %s, %s )\n", boardname[a], cmd[i]);
} else {
printf("非法的边界符号 --%s--\n", cmd[i]);
}
}
// printf("%d\n",ordercnt);
if (orderline[ordercnt].ident != 0 && need_rigister_sour == 0 && need_rigister_dest == 0 && need_address == 0) {
ordercnt++;
}
// if (sign[i] == 2) { // 如果是字母打头的
// if (find_reserve(cmd[i]) != -1) {
// fprintf(fa2,"( %ssym, %s )\n", cmd[i], cmd[i]);
//
// } else {
// fprintf(fa2,"( IDENT, %s )\n", cmd[i]);
// sign[i]=22; // 标记为自定义的标识符号
// }
// } else if (sign[i] == 3) { // 如果是数字打头的
// fprintf(fa2,"( NUMBER, %s )\n", cmd[i]);
// } else if (sign[i] == 4) {
// int a = 0;
// a = find_calculate(cmd[i]);
// if (a != -1) {
printf("%d", a);
// fprintf(fa2,"( %s, %s )\n", calcu[a], cmd[i]);
// } else {
// fprintf(fa2,"非法的运算符 --%s--\n", cmd[i]);
// }
// } else if (sign[i] == 5) {
// int a = 0;
// a = find_borad(cmd[i]);
// if (a != -1) {
// fprintf(fa2,"( %s, %s )\n", boardname[a], cmd[i]);
// } else {
// fprintf(fa2,"非法的边界符号 --%s--\n", cmd[i]);
// }
// }
// fprintf(fa2, "(%d,%s)\n", cmd[i], sign[i]);
}
for (int i = 0; i < ordercnt; i++) {
printf("linenum:%d\tkind:%d\top:%-8s\t\taddress:%s\t\trs:%s\t\trd:%s\n", i, orderline[i].ident, orderline[i].op, orderline[i].address, orderline[i].rs, orderline[i].rd);
combine(&orderline[i]);
}
// fprintf(fa2,"第一行是文件头, 也是文件索引,用于后续监控小程序读取加载到RAM用四个参数:地址,长度,加载位置,未知。\n");
fprintf(fa2,"00000000\n");
printf("0000000\n");
for (int i = 0; i < ordercnt; i++) {
printf("%s\n", orderline[i].cmd);
fprintf(fa2,"%s\n",orderline[i].cmd);
}
fclose(fa2);
fclose(fp);
return 0;
}

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









