OpenCV C++ 图像处理实战 ——《缺陷检测》







于 2023-10-28 11:06:47 首次发布

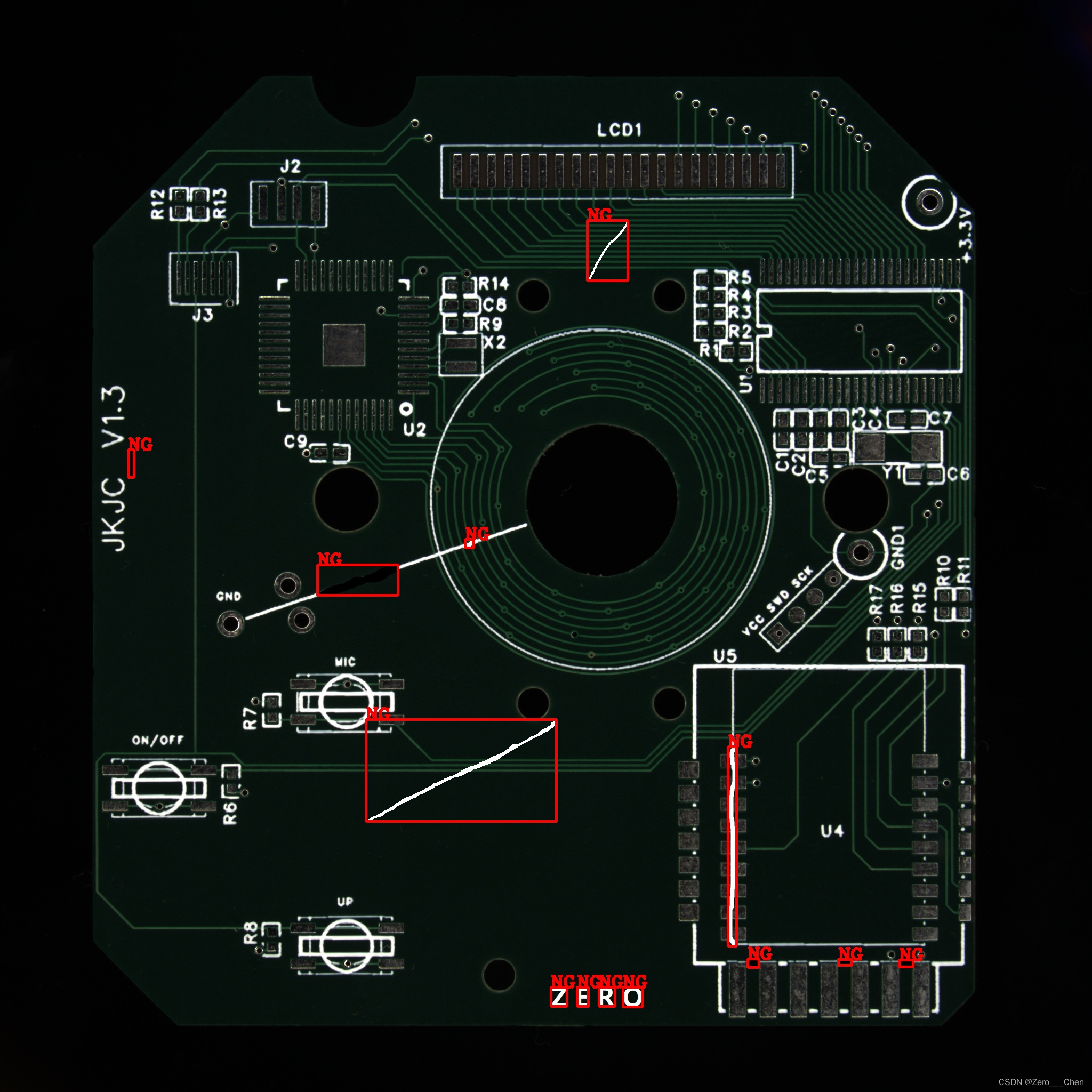
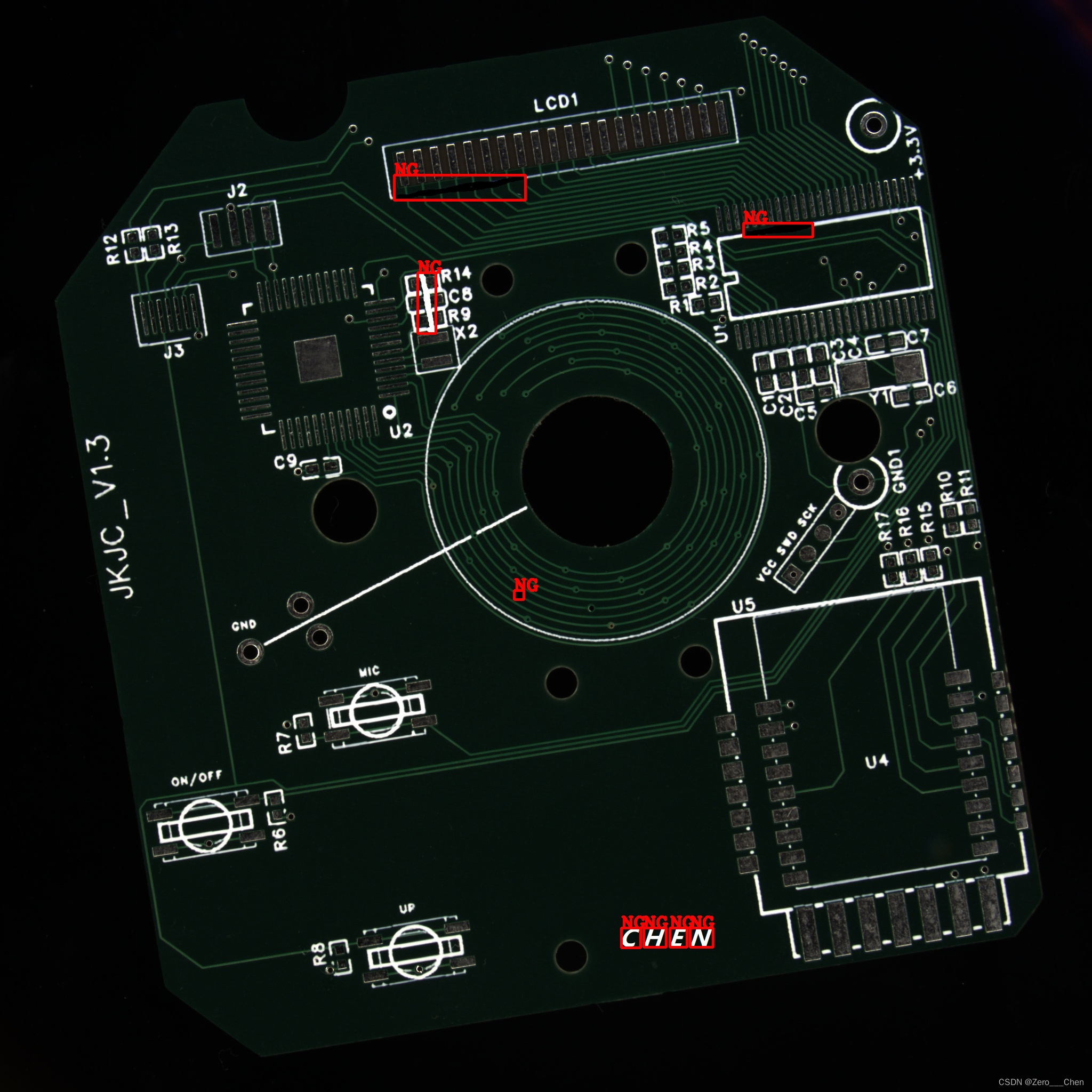
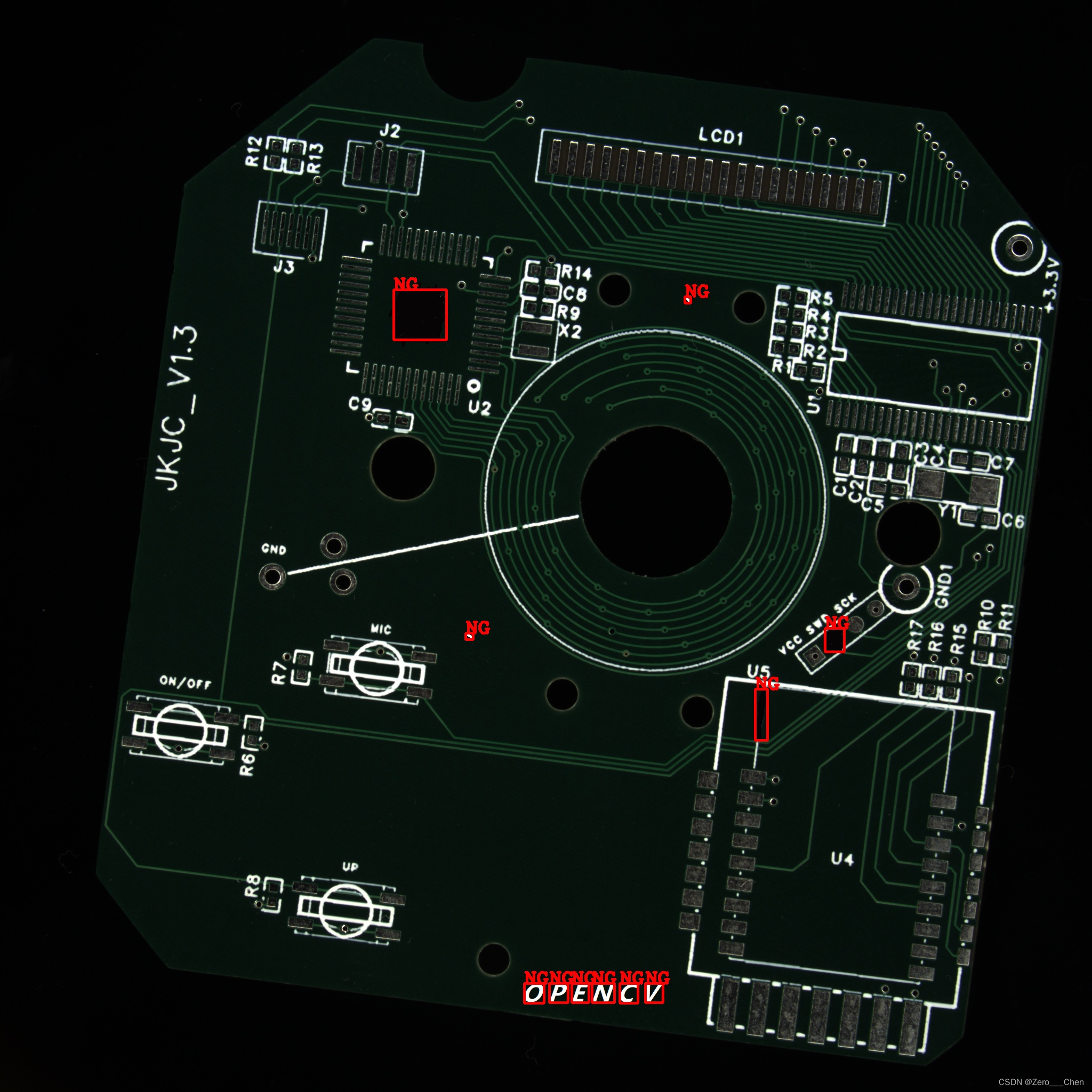
 本文介绍了使用OpenCV C++ 实现基于模板匹配的印刷缺陷检测算法,涉及图像配准、多元模板图像处理、差异模型训练及阈值图像对比,通过源码展示了缺陷检测的完整流程。
本文介绍了使用OpenCV C++ 实现基于模板匹配的印刷缺陷检测算法,涉及图像配准、多元模板图像处理、差异模型训练及阈值图像对比,通过源码展示了缺陷检测的完整流程。
本文介绍了使用OpenCV C++ 实现基于模板匹配的印刷缺陷检测算法,涉及图像配准、多元模板图像处理、差异模型训练及阈值图像对比,通过源码展示了缺陷检测的完整流程。
本文介绍了使用OpenCV C++ 实现基于模板匹配的印刷缺陷检测算法,涉及图像配准、多元模板图像处理、差异模型训练及阈值图像对比,通过源码展示了缺陷检测的完整流程。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1690
1690







