




 本文介绍了PyTorch中L1、L2正则化和Dropout的实现。Dropout是一种防止过拟合的策略,通过在训练过程中随机关闭一些神经元来提高模型泛化能力。L1正则化倾向于产生稀疏权重,而L2正则化则避免权重过大,两者都是降低模型复杂度以防止过拟合的方法。
本文介绍了PyTorch中L1、L2正则化和Dropout的实现。Dropout是一种防止过拟合的策略,通过在训练过程中随机关闭一些神经元来提高模型泛化能力。L1正则化倾向于产生稀疏权重,而L2正则化则避免权重过大,两者都是降低模型复杂度以防止过拟合的方法。
PyTorch实现L1,L2正则化以及Dropout
- 了解知道Dropout原理
- 用代码实现正则化(L1、L2、Dropout)
- Dropout的numpy实现
- PyTorch中实现dropout
1.Dropout原理
Dropout是防止过拟合的一种方法(过拟合overfitting指:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。)
训练神经网络模型时,如果训练样本较少,为了防止模型过拟合,Dropout可以作为一种优化方法。Dropout是Hintion提出的。Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来。
dropout强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
即:在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图1所示。
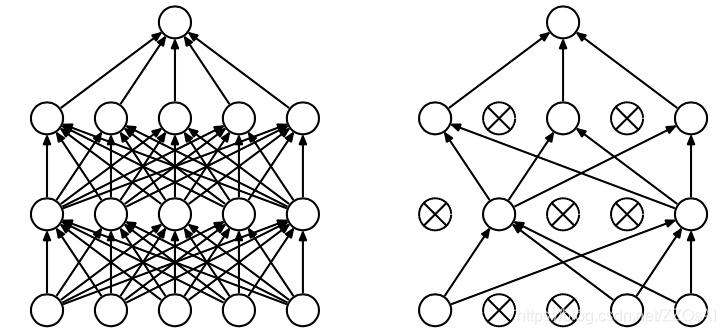
dropout噪声迫使网络在有限的数据里学习到有用的信息。
2.正则化
防止过拟合的另外一种方式就是降低模型的复杂度,一种方式就是在cost函数中加入正则化项,正则化项可以理解为复杂度,cost越小越好,但cost加上正则项之后,为了使cost小,就不能让正则项变大,也就是不能让模型更复杂,这样就降低了模型复杂度,也就降低了过拟合。这就是正则化。正则化也有很多种,常见为两种L2和L1。
2.1 L1正则化
L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
L2正则化是指权值向量w中各个元素的平方和再求平方根,通常表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1810
1810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









