




机器学习的根本问题是优化和泛化之间的对立
- 优化(optimization)是指调节模型以在训练数据上得到最佳性能(即机器学习中的学习)
- 泛化(generalization)是指训练好的模型在前所未见的数据上的性能好坏
深度学习模型通常都很擅长拟合训练数据,但真正的挑战在于泛化,而不是拟合
机器学习的目的当然是得到良好的泛化,但你无法控制泛化,只能基于训练数据调节模型
- 训练开始时,优化和泛化是相关的:训练数据上的损失越小,测试数据上的损失也越小。这时的模型是欠拟合(underfit)的,即仍有改进的空间,网络还没有对训练数据中所有相关模式建模
- 但在训练数据上迭代一定次数之后,泛化不再提高,验证指标先是不变,然后开始变差,即模型开始过拟合。这时模型开始学习仅和训练数据有关的模式,但这种模式对新数据来说是错误的或无关紧要的
Overfit过拟合,效果如最右图所示

常见应对方案如下:- 增大数据集入手:
More dataordata argumentation(用 ImageDataGenerator 可快速部署) - 简化模型参数入手:Constraint model complexity (
shallowmodel,regularization) ordropout- dropout:
torch.nn.Dropout(0.1)加一层 dropout 层, 设 dropout_prob = 0.1 - 注意 1) 区别和 tensorflow 中
tf.nn.dropout(keep_prob)设置的相反; 2) 只在 train 的时候 dropout,测试的时候要 model.eval() 切换评估模式无 dropout
- dropout:
- 减少训练时间入手:
early stopping(用 validation set 做提前的训练终止),是一个 trick
- 增大数据集入手:
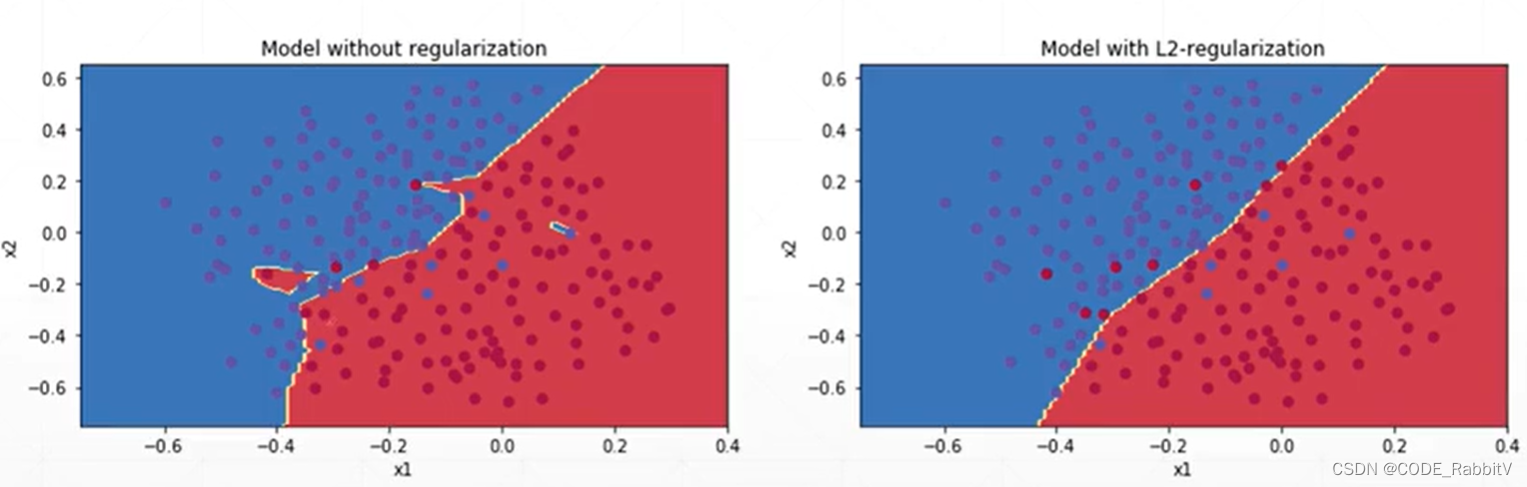
- Regularization / weight decay : 使得在保持很好的 performance 的情况下用尽可能小的 weights
- L1-regularization: Loss + = λ ∑ ∣ θ i ∣ \text{Loss} += \lambda\sum|\theta_i| Loss+=λ∑∣θi∣
- L2-regularization:
Loss
+
=
1
2
λ
∑
θ
i
2
\text{Loss} +=\frac{1}{2}\lambda\sum\theta_i^2
Loss+=21λ∑θi2,最常用,代码具体实现:给优化器
optimizer设置weight decay= λ \lambda λ: 如optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01) - 注:如果没有 overfitting 但是设置了
weight decay可能会导致性能下降,要先判断清楚是否要使用


















 7811
7811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









