 DeepSeek-R1 671B 低成本部署与效果评测
DeepSeek-R1 671B 低成本部署与效果评测




前言
在《深入理解 DeepSeek 与企业实践(一):蒸馏、部署与评测》、《深入理解DeepSeek与企业实践(二):32B多卡推理的原理、硬件散热与性能实测》的系列文章中,我们分别介绍了 DeepSeek R1 不同模型的关系、核心指标,并在 ZStack AIOS 智塔上完成了几种蒸馏模型的部署和评测。根据我们的评测,蒸馏后的版本在数学、代码等能力方面往往较原模型有提升,但如果涉及较复杂的任务(例如完整编写上百行的代码)其效果可能不尽如人意。此时我们需要考虑使用 DeepSeek-R1 671B 模型,也就是网上常说的“满血版”。
但是 671B 参数量太大,如果设备不支持 FP8 的话,仅是模型权重就有 1.3TB,成本非常高昂,因此本文将聚焦于如何以最低成本部署DeepSeek-R1 671B 这一近万亿参数级大模型、量化版本的实际表现如何、量化版本相比未量化版本损失有多少、不同硬件配置的综合性价比和适合场景。
本文目录
一、DeepSeek-R1 671B 量化版本解析
二、极限压缩方案:DeepSeek-R1 671B 1.58-bit 部署实践
三、多机扩展方案:3090 集群部署 671B-1.58b 评测
四、高性能方案:H20×8 + AWQ 量化部署
五、实战案例:Flappy Bird 代码生成
六、成本效益分析和结论
七、展望:全精度未量化模型的部署策略
一、DeepSeek-R1 671B
量化版本解析
当前,针对 DeepSeek R1 671B 的量化方案有很多,这里不再详细介绍 IQ_1_S、AWQ 等量化方法是什么具体含义,直接选取几种典型方案和显存需求对比如下:

(注:显存需求包含了最小的 KV 缓存与系统开销,且为最低需求,实际需要根据上下文窗口大小、KV 缓存精度等准确估算。GGUF 格式与 safetensor 格式由于推理引擎和并行方法不同,因此显存占用不能直接比较)
二、极限压缩方案:
DeepSeek-R1 671B 1.58-bit 部署实践
根据前面的表格,我们不难发现一台 3090 8 卡服务器正好就可以满足 671B-1.58b 的最低要求!而且可以将全部权重放到 GPU 里,推理速度是比较有保障的,不过要注意的是因为格式为 GGUF 格式,因此需要使用 llama.cpp 推理框架,在 ZStack AIOS 智塔里,支持多种推理框架,方便用户根据实际需求使用。
环境配置

部署过程
-
环境准备:安装 ZStack AIOS,确保系统满足运行要求
-
一键部署:
-
使用 ZStack AIOS 选择模型并关联合适的推理模板(llama.cpp)和镜像
-
指定运行该模型的GPU规格和计算规格后即可部署
-
-
测试运行:在体验对话框中可以尝试对话体验或者通过 API 接入到其他应用
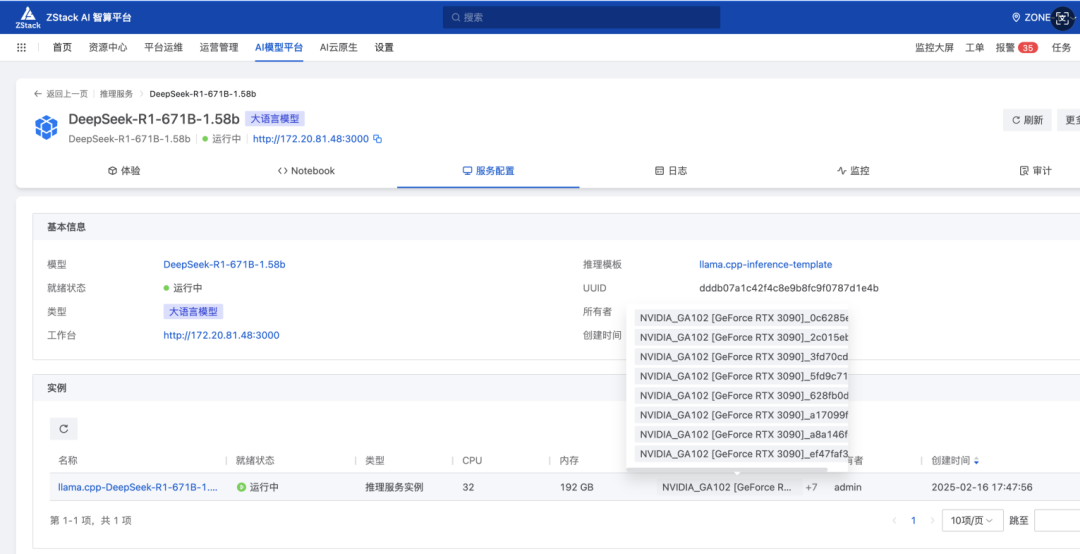
性能评测

我们很顺利地将 671B-1.58b 运行起来了!但是很遗憾的是我们只有 4K 上下文,这是因为 llama.cpp 采用了将模型分层加载到 GPU 中,因此每一层需要有完整的上下文大小以确保模型运行。此外,受限于 llama.cpp 的推理原理,增加并发基本不会增加整个服务的总吞吐还会减少单个会话的上下文大小,所以我们没有继续增加并发。
然而 4K 上下文对于 DeepSeek-R1 来说是远远不够的,非常容易在回答时被截断,无法完成我们常用的 MMLU、C-EVAL 等评测,为了增加上下文大小,我们需要用多机部署 DeepSeek-R1-671B-1.58b 来测试。
三、多机扩展方案:
3090 集群部署 671B-1.58b 评测
由于单机 3090 上的上下文太小,我们尝试通过集群来扩展 671B-1.58b 模型服务的上下文,通过将模型权重分散到 16 张卡上,理论上我们可以获得接近 14GB 的空间用于运行 KV Cache,也就是接近 14K 的上下文空间(注意 llama.cpp 的多机并行推理并不是生产推荐用法,这里仅作测试用)。
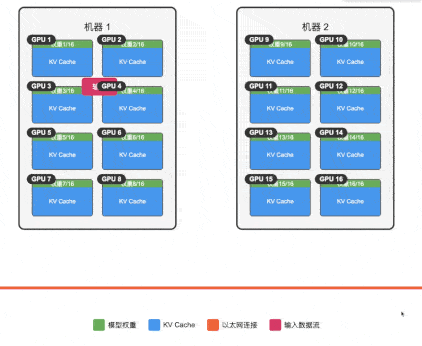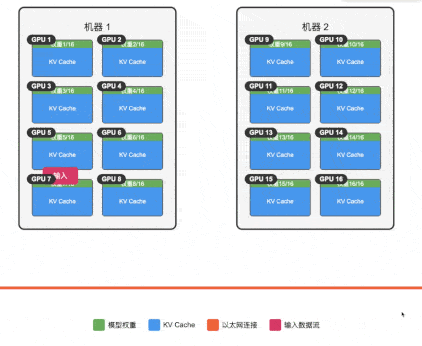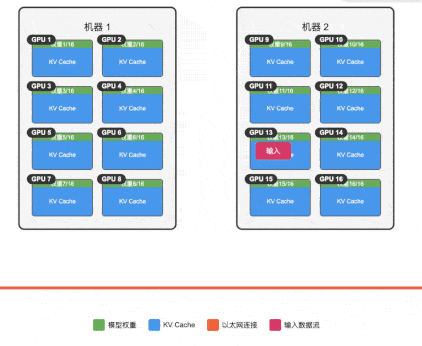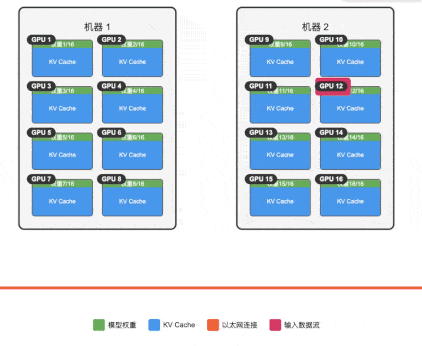
环境配置

性能表现
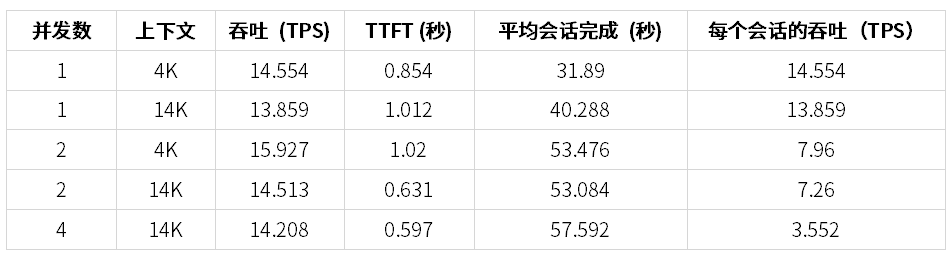
瓶颈分析
-
可以看到在长上下文时,模型吞吐略有增加
-
由于 llama.cpp 的架构和 3090 显卡的带宽所限,更高的并发无法有效提升 GPU 利用率
模型能力评测
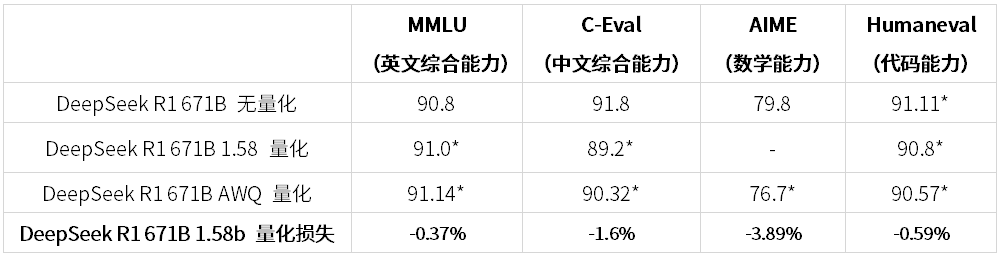
通过 ZStack AIOS 的服务评测功能,我们对 DeepSeek-R1-671B-1.58b 进行了 MMLU、C-Eval、HumanEval 等评测,从不同维度比较 671B 量化之后的能力表现,以及和蒸馏版的对比。
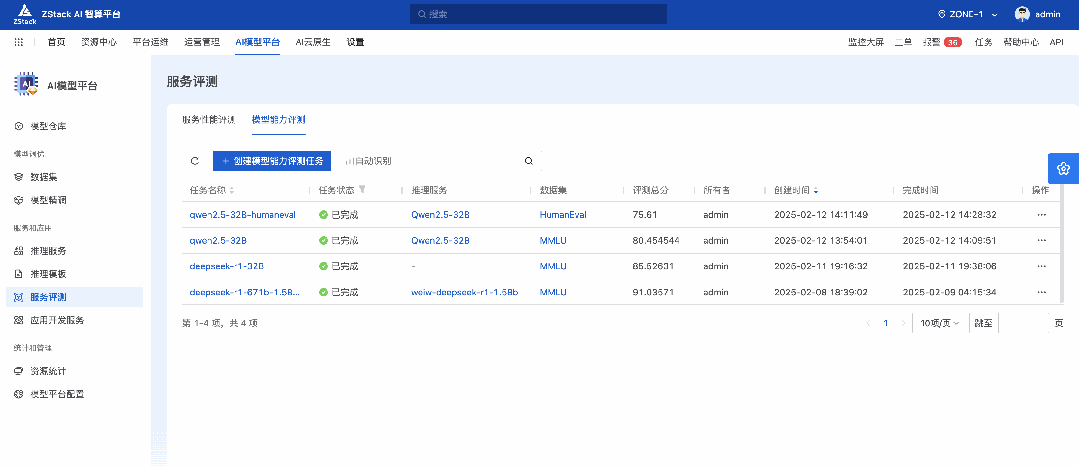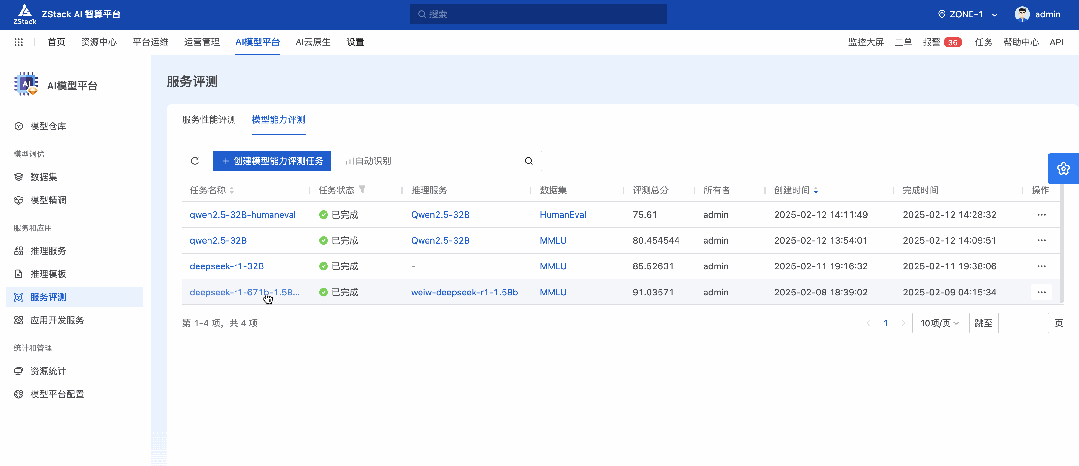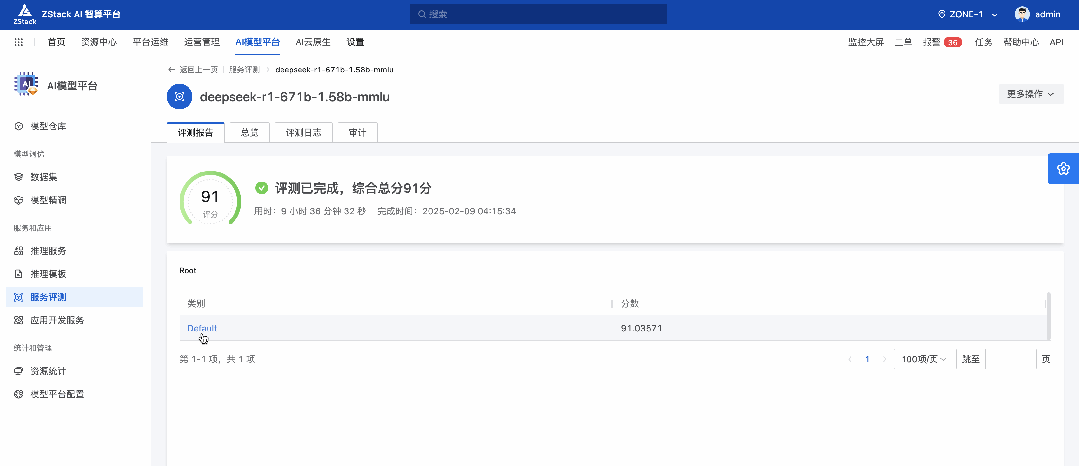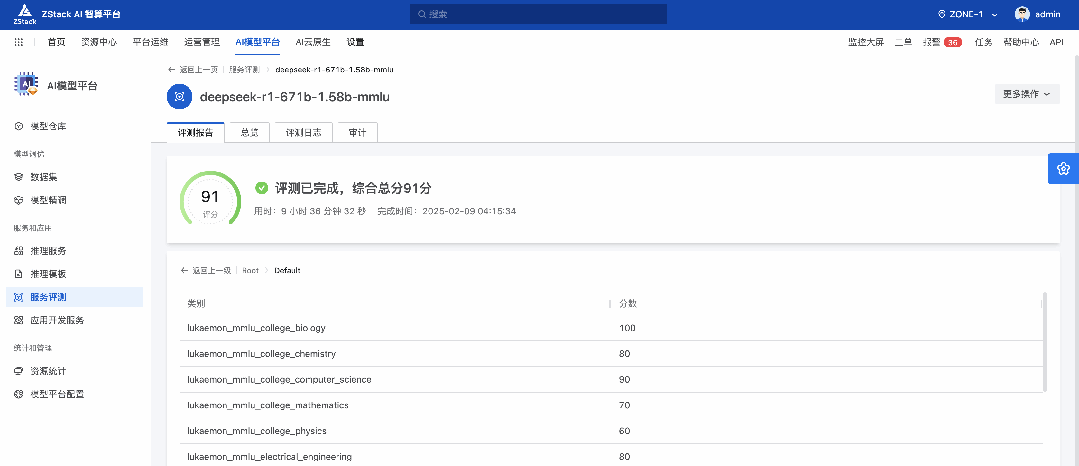
由于运行时间过于漫长,所以对部分评测进行了采样,汇总如下:
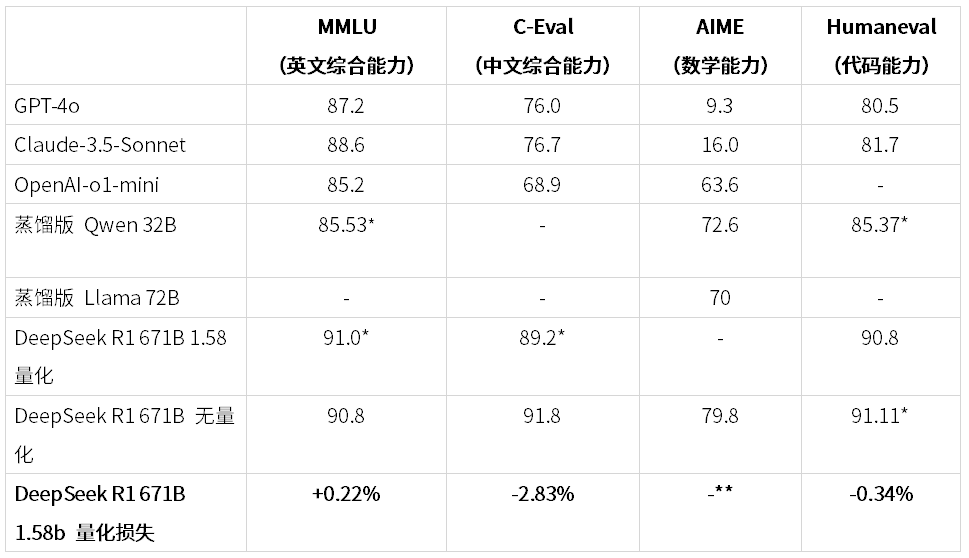
*标注表明数据为 ZStack 实验环境测试,非官方论文数据
**由于上下文只有 14K,无法正常完成 AIME24 的测试
根据上面数据,我们可以看到经过 1.58 量化后,能力有一定影响,但是影响并没有想象中的大,且在英文综合、中文综合、代码能力上对比 GPT-4o、Claude-3.5 仍有显著优势。
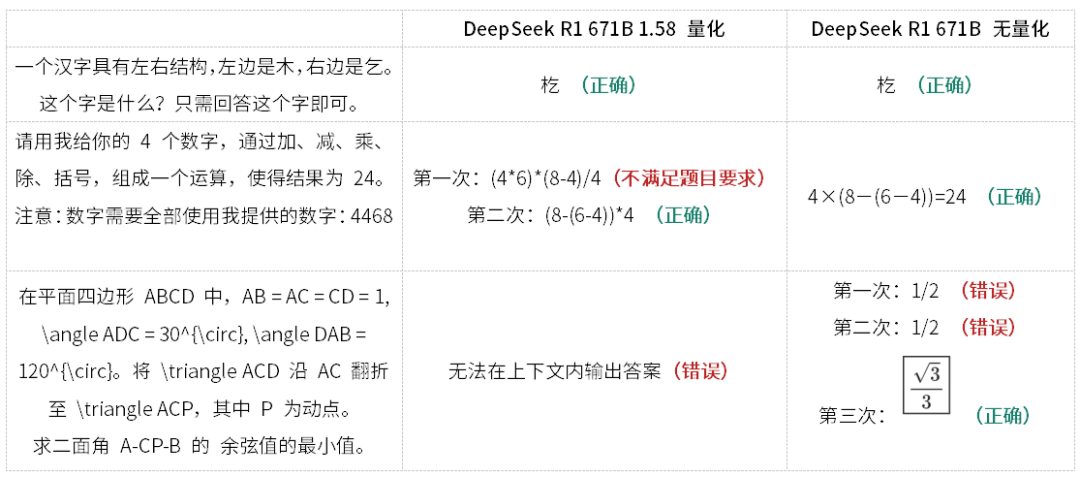
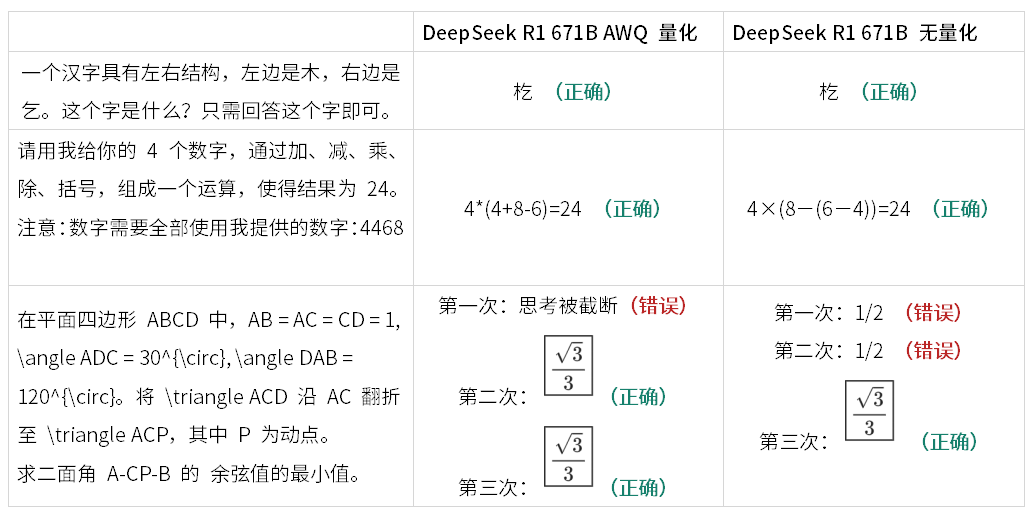
网上有一些“识别模型是否为满血版的技巧”,我们摘取几个也进行了测试,发现这些题目确实有一定辨识度:
四、高性能方案:
H20×8 + AWQ 量化部署
受限于 llama.cpp 的架构设计以及 1.58 量化的数据结构,进一步提升性能是比较困难的,但对于企业来说,单台或两台 3090 固然成本低,但是其上下文窗口能力、并发能力都会受到比较大的掣肘。
因此,我们再继续考虑另一种量化手段——AWQ,理论上 AWQ 量化后只需要 8 张 64GB 以上显存的显卡即可运行,但由于条件原因,我们采用 H20 96GB 来测试 AWQ 量化后模型的表现。
环境配置

性能表现
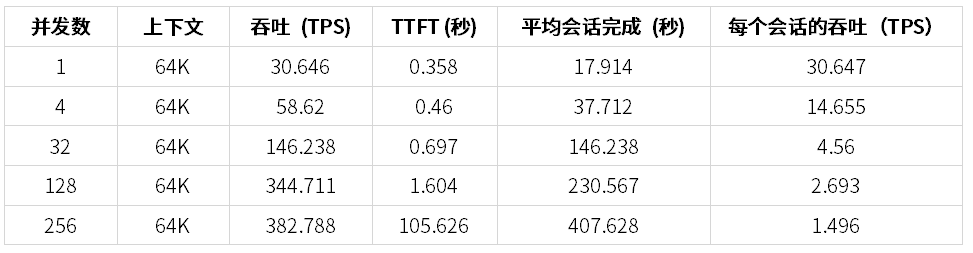
下图为在 ZStack AIOS 智塔上通过 DeepSeek-R1-AWQ 对话的性能表现
性能分析
1. AWQ 量化后无法使用 MLA 加速、FP8 加速等方法,导致在多并发场景下性能可能还不能充分发挥;
2. 随着并发数增长,吞吐可以持续增加到接近 400 Token/s,但是此时每个会话的吞吐已经极低,只适合于离线场景;
3. 由于测试方法较为严格,测试过程中 KV Cache 命中率较低,如果我们采用接近的 Prompt 以提升 KV Cache 命中反,最多可以提升到 910 TPS 左右。
能力评测对比:
与 1.58 类似,我们也运行了网上流行的“满血版测试”:
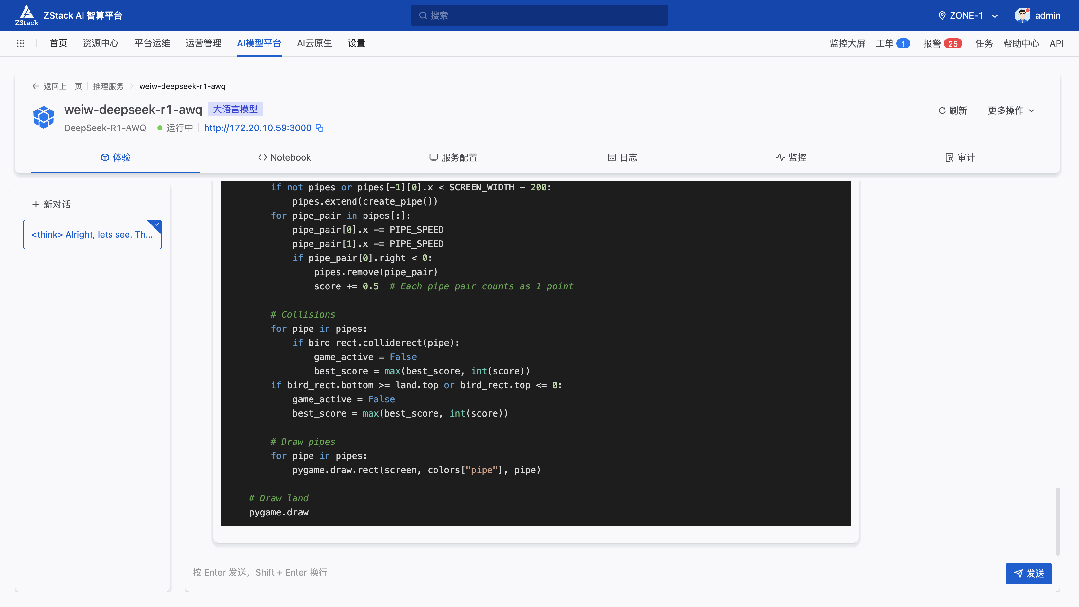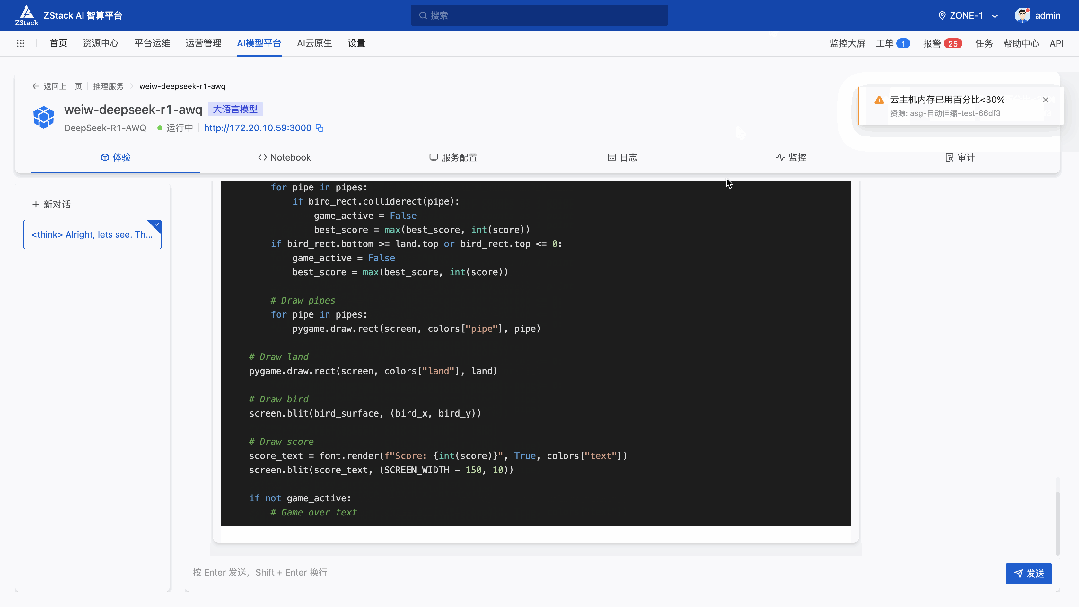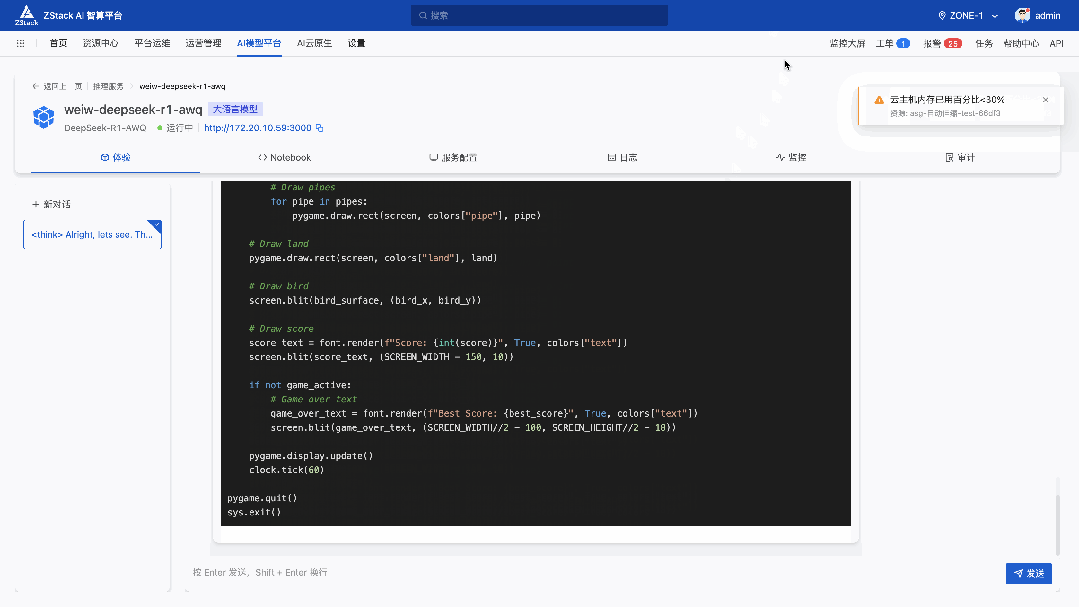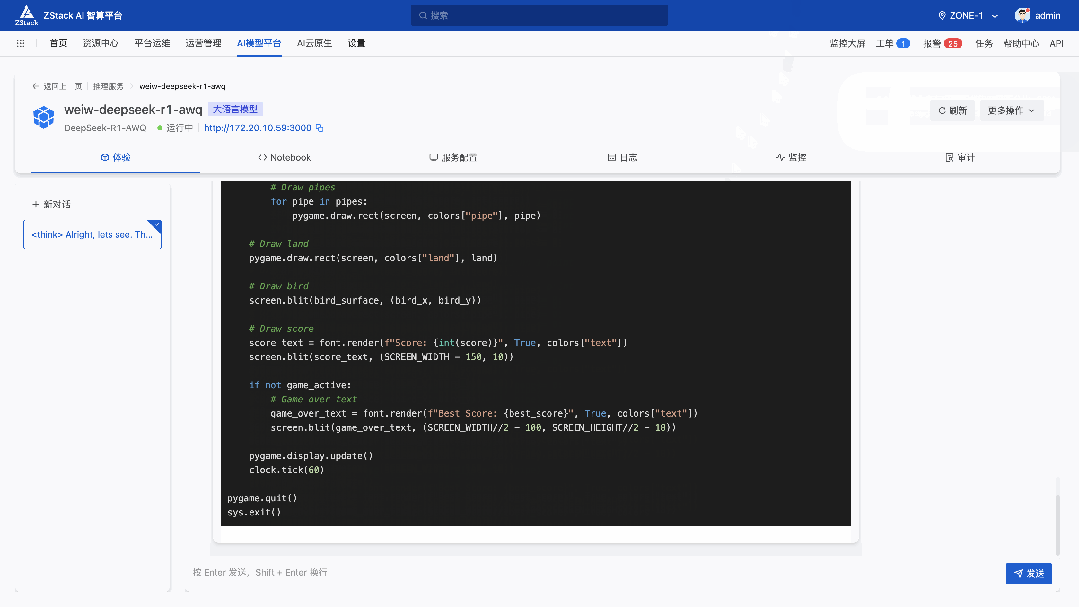
五、实战案例:Flappy Bird 代码生成
前面我们看到了 DeepSeek-R1-671B 量化对于代码生成的能力影响不大,但是 HumaneEval 90 分对于读者来说可能并不直观,我们参考了 Unsloth 的测试方法——我们要求模型创建 3 次 Flappy Bird 游戏(pass@3),我们按10个标准(例如使用随机颜色,随机形状, 是否可以成功运行等) 评分,最后取三次测试取平均分。测试中使用的 Temperature 为 0.6。
下面是使用的 Prompt:
1 Create a Flappy Bird game in Python. You must include these things:
2 You must use pygame.
3 The background color should be randomly chosen and is a light shade. Start with a light blue color.
4 Pressing SPACE multiple times will accelerate the bird.
5 The bird's shape should be randomly chosen as a square, circle or triangle. The color should be randomly chosen as a dark color.
6 Place on the bottom some land colored as dark brown or yellow chosen randomly.
7 Make a score shown on the top right side. Increment if you pass pipes and don't hit them.
8 Make randomly spaced pipes with enough space. Color them randomly as dark green or light brown or a dark gray shade.
9 When you lose, show the best score. Make the text inside the screen. Pressing q or Esc 9 will quit the game. Restarting is pressing SPACE again.
10 The final game should be inside a markdown section in Python. Check your code for errors and fix them before the final markdown section.下面的运行效果是我们运行 3 次选取效果最好的情况,得分为平均分:
可以看到在较长的代码生成中,AWQ 量化后略有下降,但是整体表现与 DeepSeek-R1 区别并不大。
| _ | 运行效果 | 得分 |
| DeepSeek-R1-671B-1.58b 量化 |
| 78.5% |
| DeepSeek-R1-671B-AWQ 量化 |
| 91.0% |
| DeepSeek-R1-671B 无量化 |
| 92.5% |


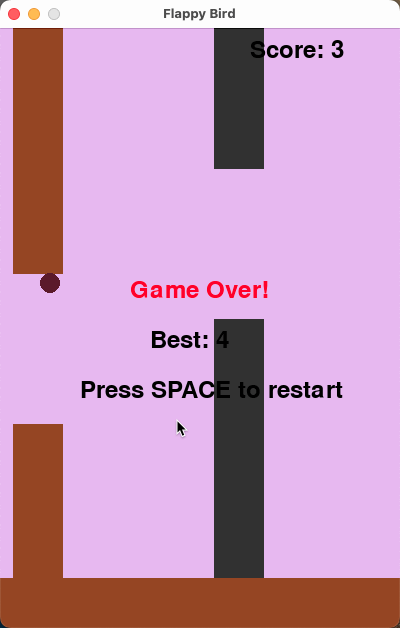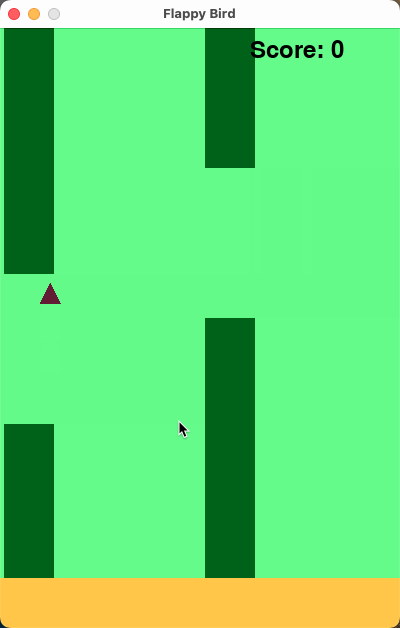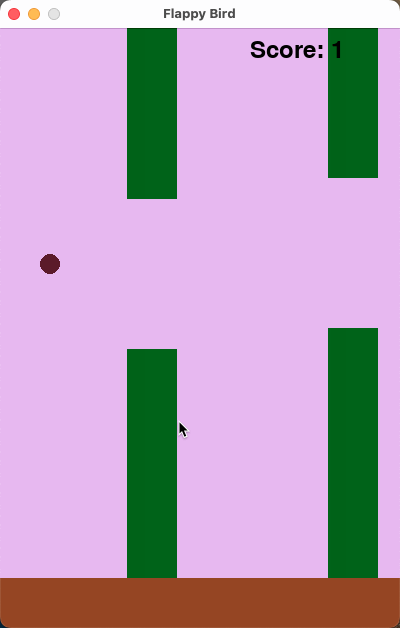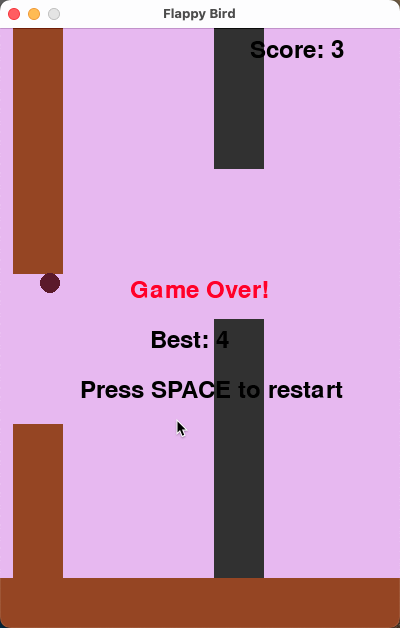
可以看到在较长的代码生成中,AWQ 量化后略有下降,但是整体表现与 DeepSeek-R1 区别并不大。
六、成本效益分析和结论
考虑到 GPU 机型价格受硬件配置、市场供给情况影响较大,这里基于较为流行的在线算力平台
基于 AutoDL 实例价格估算:
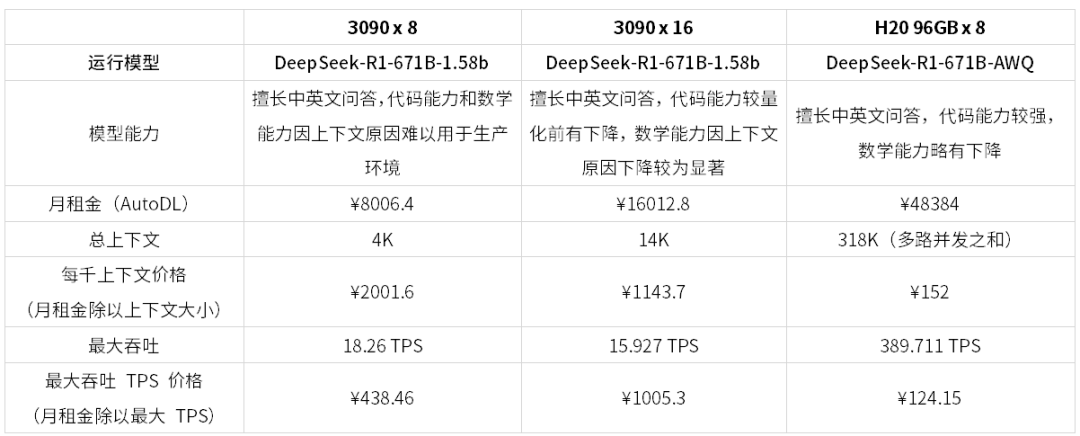
需要注意的是,月租金和购买成本并不一定成正比,例如在这里 H20 8 卡服务器月租金是 3090 八卡服务器的 6 倍,但是其购买成本不一定是 6 倍;
结论:
-
3090 单机适合于简单体验,不涉及数学、代码(均需要较长的上下文)等任务的测试;
-
3090 多机比较适合于个人或超小规模场景下生成代码,14K 上下文在代码生成时一般足够够用,但不适合复杂的数学推理场景;
-
虽然 3090 单机成本低,但是在批量运行场景下优势不明显,所以如果追求较大的上下文窗口、较高的并行能力的话,更高的配置其综合性价比反而会更高;
-
受限于模型的参数量所带来的超大计算量,单用户很难获得超过 30~50 TPS 的推理速度。
不过,由于 DeepSeek 模型发布时间还较短,因此推理引擎还会有一些优化空间,未来可能还会发生变化。
七、展望:更大参数模型的部署策略
通过本文的探讨,我们深入了解了 DeepSeek-R1-671B 模型如何通过 1.58 量化来降低体验成本和通过 AWQ 量化来降低超长上下文的成本,测试了对应的模型运行性能和能力,可以看到复杂数学推理能力是最容易在量化中损失的,此外在部署中,需要密切关注上下文的大小,这将对模型的表现影响很大。
在后续的文章中,我们将继续探讨:
-
全精度部署策略: 在高性能计算环境下,如何正确部署模型,充分发挥大型模型的能力和硬件资源。
通过对比不同规模和精度的模型,我们希望为企业级应用提供更加全面和细致的部署方案,帮助更多行业快速落地大语言模型技术,实现商业价值。
注:本文中的部分数据为示例,实际情况可能有所不同,建议在具体实施过程中进行详细测试和验证。

















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









