




在我们前几篇文章中,我们深入探讨了 DeepSeek-R1 系列模型(蒸馏版7B、32B,以及671B 量化版和非量化版)的部署和推理原理。
然而,面对如此多样的模型选择,企业在实际应用中常常困惑:哪种模型适合特定场景?该使用推理模型还是通用模型?不同模型的投入成本与性能表现如何平衡?本文将针对这些问题,先对目前最常见也火爆的知识库、代码辅助和智能体(Manus)场景进行分析,最后结合当前硬件成本和实际企业应用场景,提供系统的分析和建议。
本文目录
一、场景 1:知识库
二、场景 2:代码辅助
三、场景 3:智能体(Manus)
四、企业 AI Infra 建设方案建议
五、总结与展望
场景 1:知识库
企业知识库应用是大模型落地最常见的场景,对于简单的、对幻觉容忍度较高的场景,例如旅游景点问答或内部辅助等场景,业界已经形成了非常标准的 RAG 三件套——embedding + LLM + rerank(文档切片、向量化、检索内容重排、大模型总结答案),在上述简单场景中已经可以运用到实践中。
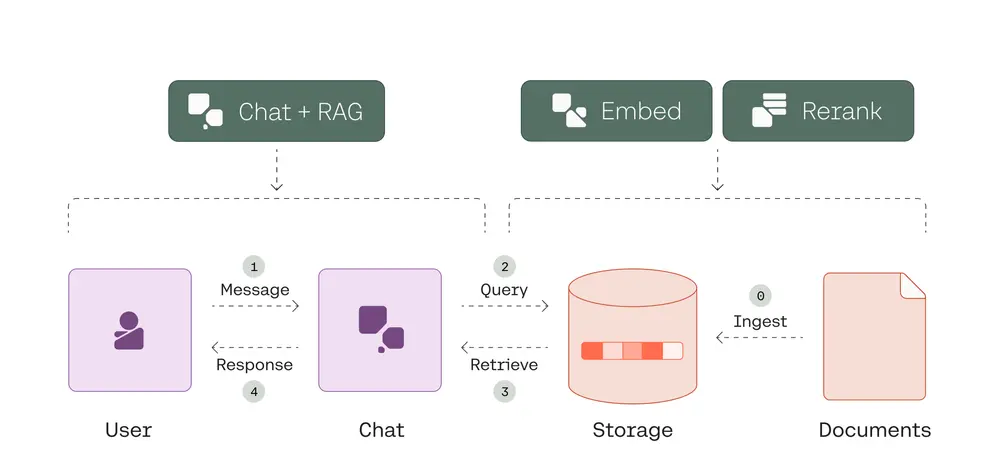
但在要求更高的企业场景中,知识库常常是“Demo 三天、优化半年”,这是因为在企业实际应用中,知识库的核心技术 RAG 往往会面临诸多挑战。根据业内实践,知识库部署主要存在以下难点:
-
多跳问题处理
多跳问题常见于企业报告数据整理环节、大量同义近义用语乃至指代等场景,如"从多份报表中找出企业近三年的复合增长率并与竞对比较"。这类问题需要模型具备理解意图、拆分实体和进行多步推理的能力。 -
上下文内容丢失问题
企业文档中的关键信息如时间、区域标记往往分散在文档不同位置,传统 chunking 方法容易造成信息丢失。例如,财报中年份信息可能只在文件名和大标题出现,导致分割后的文本片段失去时间背景。
-
结构化数据处理
企业需要同时处理结构化数据(如数据库、Excel 表格)和非结构化数据。大模型原生处理的是非结构化数据,但企业场景中结构化数据同样重要。 -
计算与逻辑推理问题
在一些场景里,需要对输入信息进行综合计算和推理,例如已知某些配件的价格,需要计算总体的成本等。
-
多模态内容解析
企业文档中包含大量图表、思维导图等复杂视觉内容,需要布局识别和理解能力,而非简单的 OCR。
对此,业界也提出了诸如问题分类(Routing)、问题优化(Rewriting)、知识图谱(GraphRAG)、复杂文档提取等方法,但这些方法往往涉及不同模型的配合,那么如何选择模型、如何让模型快速配合、确保每个步骤的落地就变成了关键问题。
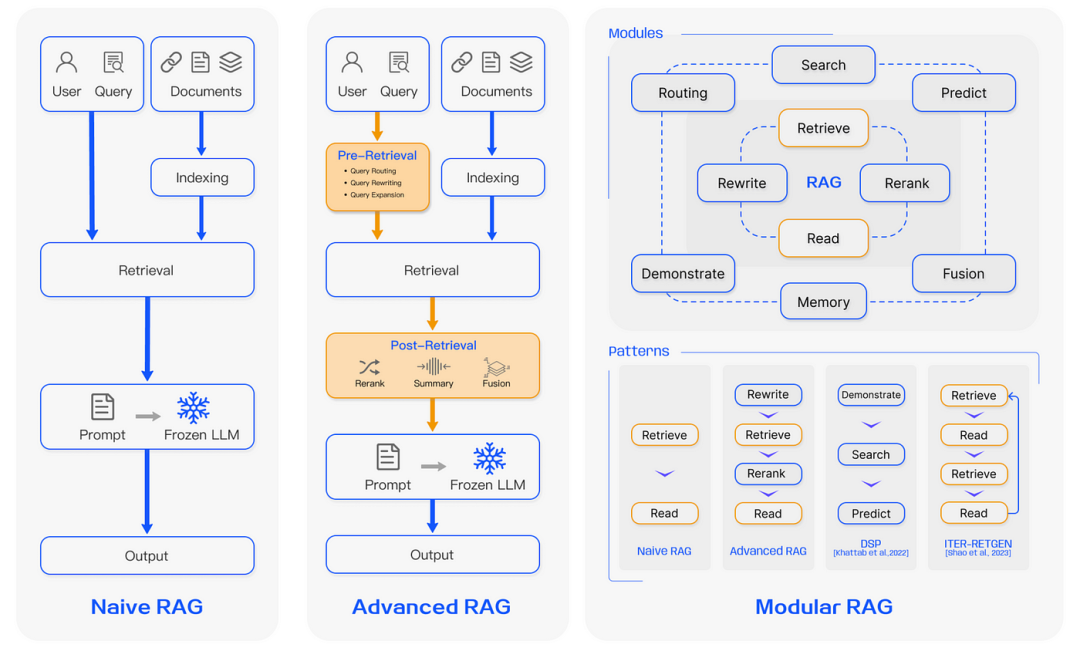
(图片来自网络)
接下来,我们将这些业界方案分为“知识构建”、“知识检索”和“答案生成”三个阶段来看。
阶段 1:知识构建
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









