




前言
在前几天的系列文章中,我们已经深入探讨了 DeepSeek 模型的蒸馏技术、量化策略,以及 7B、32B 和 671B 量化版本模型的部署要点与性能评估,帮助大家在不同的资源条件下选择合适的模型部署方案。
随着企业对 AI 应用探索的深入,DeepSeek 系列的 671B 满血版模型凭借强大的超复杂任务推理能力,成为企业提升竞争力的关键。但因其参数量巨大,单卡或单机部署无法发挥全部性能。多机多卡部署结合 ZStack AIOS 平台,是释放其潜力的关键。本文将详细介绍在 AIOS 平台多机多卡部署 671B 满血版模型的实践过程,分析其性能表现,为企业 AI 技术落地提供有力支撑和指导。
本文目录
一、DeepSeek 模型推理性能的理论分析
二、DeepSeek 模型推理性能的优化手段
三、企业级部署与实践:成本与性能的权衡
四、生产应用中的后续优化思路
五、结语
六、展望
一、 DeepSeek 模型推理性能的理论分析
对于现在的这些大模型来说,其GPU运行过程可以简化为下面几步:
1、对输入文本进行转换,从汉字或者单词转换成大模型能理解的数字(向量和位置编码);
2、基于模型的参数进行计算,此时需要将模型的参数(以 Qwen2.5-72B 为例就是 145GB 数据)加载到计算单元进行计算;
3、生成回答,本质上是生成候选词和概率分布。
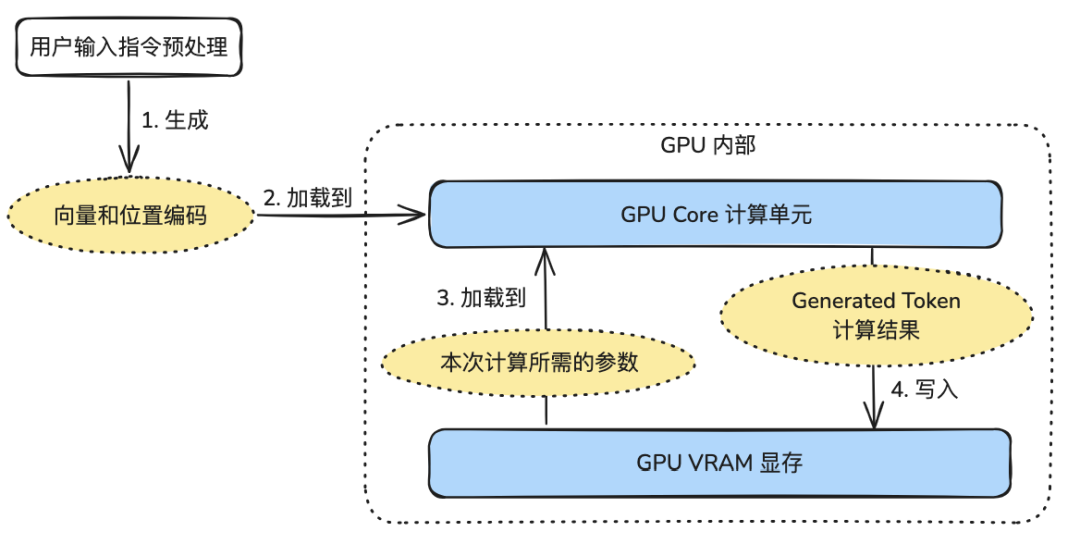
在这个过程中,对于 GPU 硬件有两个参数最为重要:
1.矩阵乘法的性能,也就是我们常说的 GPU 的 TFlops;
2.GPU 显存带宽,因为要从显存把模型参数读取过来,这个与显存采用 GDDR 还是 HBM 有关。
对于现代 GPU 来说,后者的“瓶颈效应”往往大于前者,我们可以将一些常见 GPU 的算力和显存带宽列出来:

可以看到以 RTX 4090 为例,以 FP8 来计算每秒可以处理 82TB 的数据,但是显存带宽每秒只可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









