






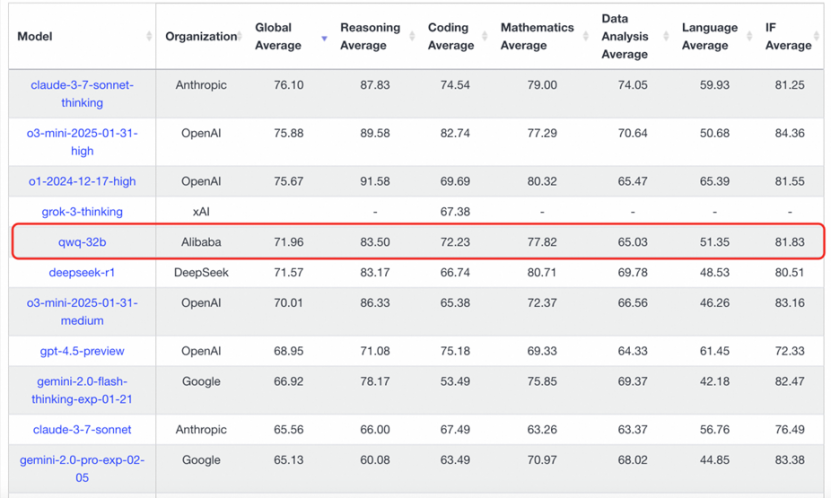
3月初,阿里开源发布了新推理模型 QwQ-32B,其参数量为 320 亿,但性能已能够比肩6710亿参数的DeepSeek-R1满血版。在最新一期的 LiveBench 国际权威榜单中,阿里通义千问 QwQ-32B 一举冲进全球前五,并且直接坐稳最强开源模型的宝座!
在线体验
VERYCLOUD睿鸿股份已接入QwQ-32B,并提供在线体验窗口。您可以通过试用,快速了解和体验QwQ-32B,感受到其强大的功能和便捷的使用体验。
QwQ-32B模型简介
QwQ-32B是由阿里巴巴通义千问团队发布并开源的一款大语言模型。其以较小的参数量实现高性能,适合在消费级显卡上部署,并且能够一次性处理多达32,000个Token的输入信息,适用于复杂任务和长篇内容分析。适用场景广泛涵盖推理任务、编程辅助、数学问题解决以及通用对话等多个领域。
性能比肩全球最强开源推理模型
基准测试数据显示,千问QwQ-32B 模型几乎完全超越了OpenAI-o1-mini,比肩6710 亿参数的 DeepSeek-R1 满血版:在测试数学能力的AIME24评测集上,以及评估代码能力的LiveCodeBench中,千问QwQ-32B与DeepSeek-R1表现相当,远胜于o1-mini及相同尺寸的R1蒸馏模型。
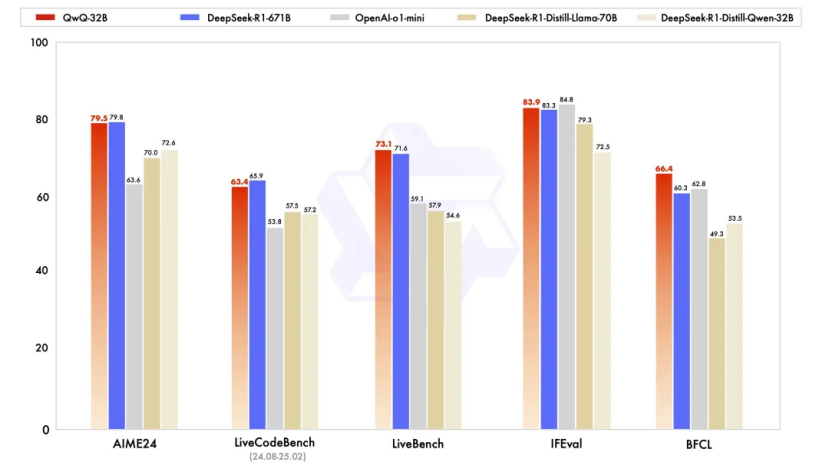
QwQ-32B与原始 DeepSeek-R1、DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 的基准测试结果比较。

将持续优化AI产品服务,积极响应业界动态潮流,助力AI赋能业务创新与智能化升级。

















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









