




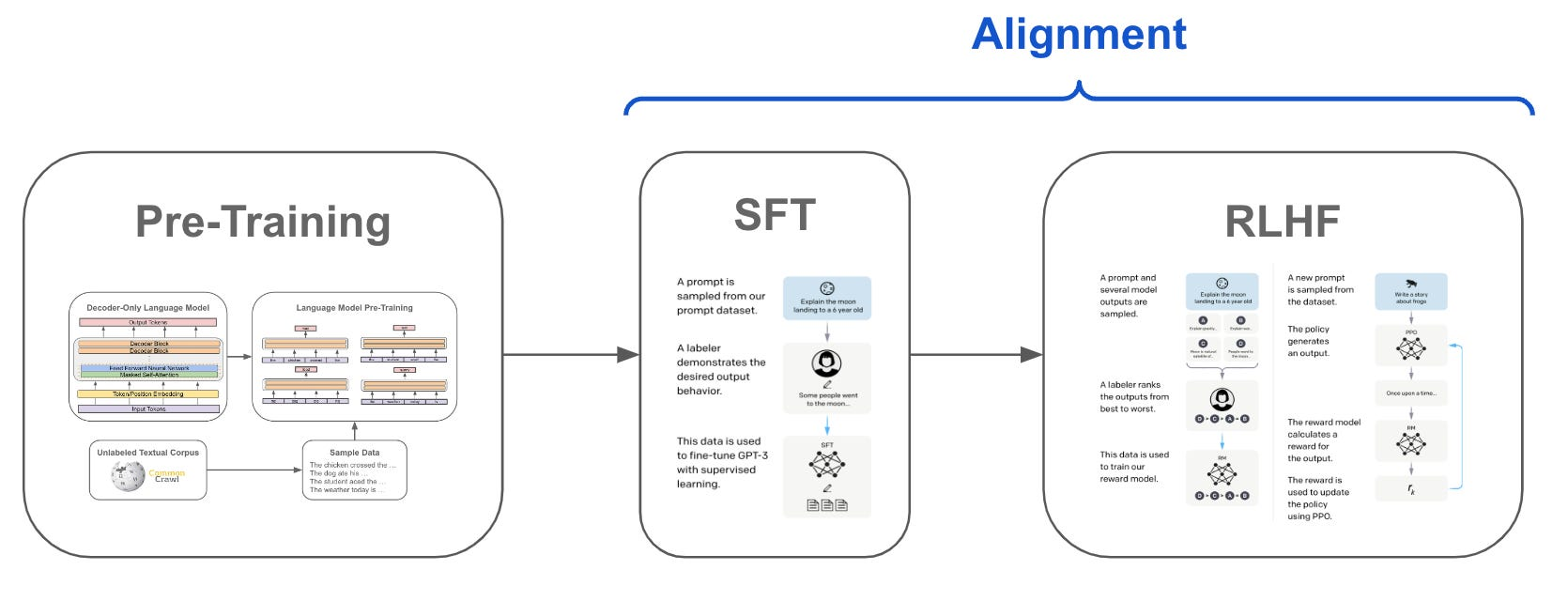
监督微调(Supervised Fine-Tuning,SFT)是当前自然语言处理(NLP)领域中一种重要的模型优化技术。它通过在预训练模型的基础上,利用标注数据进行针对性训练,以提升模型在特定任务上的表现。本文将深入探讨SFT的技术细节、优化方法、应用场景、面临的挑战以及未来发展趋势。
一、SFT的技术细节
(一)数据准备与处理
• 数据多样性:SFT需要的数据应涵盖多种任务类型、不同难度级别以及多样化的指令结构和表达方式。这有助于模型在微调后应对多种复杂情境。
• 数据质量:标注数据的准确性至关重要。高质量的数据标注能够显著提升模型性能,避免因数据错误导致的训练偏差。
• 数据扩充:通过合成、变换、拼接等手段丰富数据多样性,模拟真实场景中的变体,提升模型的抗干扰能力。
• 特殊Token的利用:SFT阶段会引入预训练阶段未见过的特殊Token,如用于标注对话角色或构造知识的Token,帮助模型理解不同角色之间的关系。
• 数据组成形式:与预训练阶段不同,SFT数据通常根据原始长度处理,并引入EOS(End Of Sentence)token,使模型能够知道何时停止生成。
(二)微调方式
SFT的微调方式主要有以下几种:
• 全参数微调:适用于拥有大量与任务高度相关的高质量训练数据的情况。这种方式会更新模型的所有参数,以更好地适应特定任务。
• 部分参数微调:在需要保留大部分预训练知识的情况下更为高效。例如,LoRA(Low-Rank Adaptation)通过添加低秩矩阵进行微调,减少了计算资源需求,同时提高了模型性能。
• 冻结监督微调:冻结部分或全部预训练模型的权重,仅对模型的部分层或新增的附加组件进行训练。这种方式可以减少计算资源的消耗,同时保持预训练模型的大部分知识。
(三)训练技巧与策略
• 优化Prompt设计:避免在Prompt中写入冗余信息,以提高模型生成速度和效率。
• 损失函数设计:根据任务需求选择合适的损失函数,并优化其参数以提升模型性能。
• 利用Special Token:通过引入特殊Token来引导模型学习新的语义结构和指令。
二、SFT的优化算法与正则化方法
(一)优化算法
• 低秩适应(LoRA):通过在模型中引入低秩矩阵,减少微调过程中的计算资源需求,同时提高模型性能。
• 动态学习率调整:在微调过程中,采用动态学习率调整策略,如学习率从较高值逐渐降低,以优化训练效果。
(二)正则化方法
• Dropout:在训练过程中随机丢弃部分神经元,防止模型对训练数据过度拟合。
• 权重衰减:通过在损失函数中加入权重衰减项,限制模型参数的大小,降低过拟合风险。
三、SFT的应用场景
(一)自然语言处理
SFT在NLP领域被广泛应用于文本分类、机器翻译、情感分析等任务。例如,通过引入标注数据,可以对预训练的语言模型进行微调,以提升其在特定领域(如金融、医疗)的文本分类准确性。
(二)智能客服
在智能客服领域,SFT可以用于构建更加智能、高效的客服系统。通过引入标注数据对预训练的对话模型进行微调,可以提升其在理解用户意图、生成准确回复等方面的能力,从而提升用户满意度。
(三)计算机视觉
在计算机视觉领域,SFT同样具有广泛的应用前景。通过引入标注数据,可以对预训练的图像识别模型进行微调,以提升其在特定场景(如智能交通、安防监控)中的目标检测准确性。
四、SFT面临的挑战
(一)数据集质量
SFT的效果严重依赖于数据集的质量。如果数据集不够全面或存在标注错误,可能会影响模型的性能。因此,在选择和预处理数据集时需要格外注意。
(二)计算资源
虽然SFT相对于从头训练模型来说更加高效,但仍然需要一定的计算资源来支持微调过程。对于大型语言模型来说,这可能需要高性能计算机或云计算平台来支持。
(三)过拟合风险
由于微调过程中使用的标注数据通常较少,因此存在过拟合的风险。为了降低过拟合风险,可以采取一些正则化方法,如Dropout、权重衰减等。
(四)模型幻觉问题
在微调过程中,模型可能会产生幻觉问题,即生成与事实不符的错误信息。为了解决这一问题,可以采用知识蒸馏、模型融合等方法来增强模型的稳定性和准确性。
五、SFT的未来发展趋势
(一)跨领域应用
未来,SFT将更多地应用于跨领域任务中,通过引入多领域标注数据,实现模型在不同领域之间的迁移和泛化。
(二)高效训练算法
随着计算能力的提升和算法的优化,SFT的训练速度将进一步提升,使得模型能够在更短的时间内完成微调并达到更好的性能。
(三)智能化应用
SFT将更多地与智能化应用相结合,如智能医疗、智能教育等,通过引入标注数据对模型进行微调,实现更加智能化、个性化的服务。
(四)模型轻量化
未来,SFT模型将朝着轻量化的方向发展。通过模型压缩、剪枝等技术降低模型复杂度和计算量,使其能够在更多设备上运行。
(五)多模态融合
目前,SFT模型主要处理文本数据。未来,该模型将与其他模态(如图像、音频等)的数据进行融合处理,实现跨模态的信息交互与理解。
(六)知识增强
为了更好地满足复杂场景下的需求,SFT模型将引入外部知识库进行知识增强。通过融合领域知识和常识信息,提高模型在特定任务上的表现。
六、总结
监督微调(SFT)作为一种重要的技术手段,在自然语言处理和人工智能领域发挥着关键作用。通过在预训练模型的基础上进行特定任务的微调,SFT能够显著提升模型的性能,使其更好地适应特定场景的需求。尽管SFT在数据隐私、模型偏见和可解释性等方面面临一些挑战,但随着技术的不断进步,这些问题有望得到解决。未来,SFT将继续在多个领域发挥重要作用,为人工智能的发展提供有力支持。

















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









