







 超级会员免费看
超级会员免费看
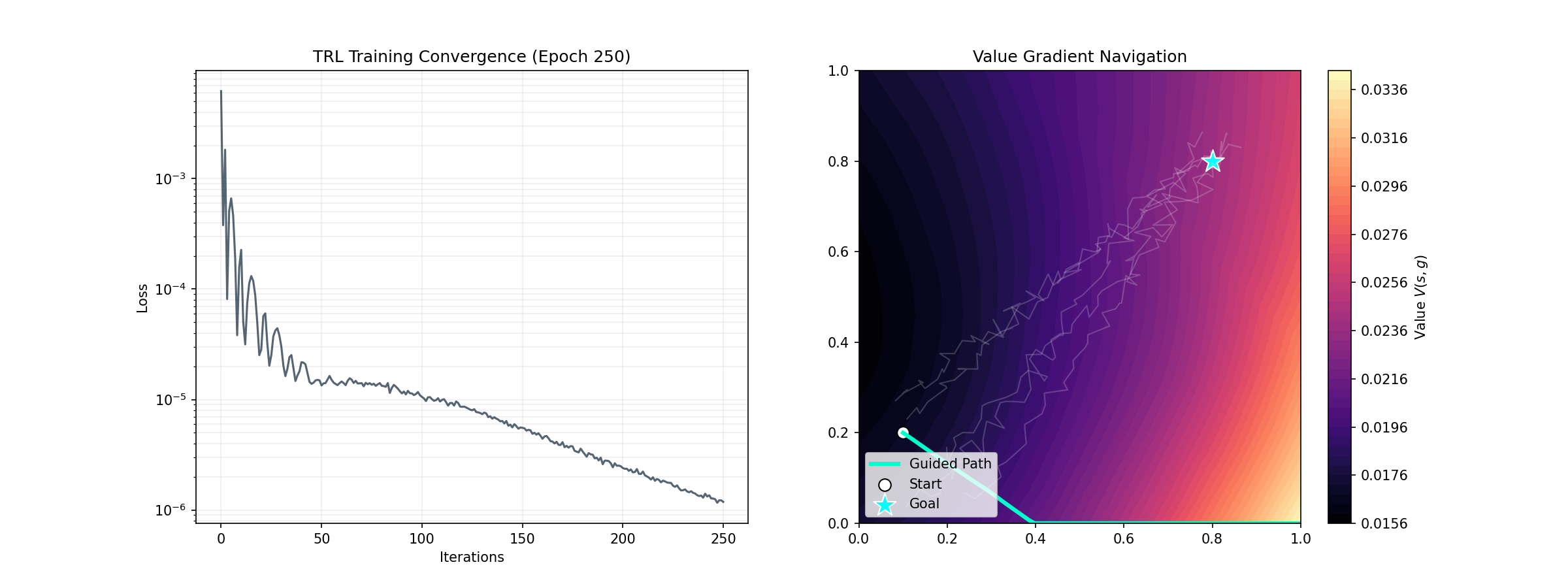
1. 引言:非策略强化学习的困境
在强化学习(RL)领域,长期以来存在两种主要的数据利用范式:策略级(On-Policy)和非策略级(Off-Policy)。
虽然PPO等On-Policy算法在扩展性上已表现出色,但它们效率低下——每次更新都必须丢弃旧数据。在机器人、医疗或对话系统等数据昂贵的领域,我们需要Off-Policy算法(如Q-Learning),利用所有历史数据。然而,传统的Off-Policy算法在**长视界(Long-horizon)**任务中面临严峻挑战。
传统的两大范式及其缺陷
-
时间差分 (TD) 学习:

-
蒙特卡洛 (MC) 学习:
-
公式: 直接使用整条轨迹的回报。
-
问题: 方差极大,且数据利用率低。
-
虽然 $

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









