




【已更新完整word论文与代码!】
我是Tina表姐,毕业于中国人民大学,对数学建模的热爱让我在这一领域深耕多年。我的建模思路已经帮助了百余位学习者和参赛者在数学建模的道路上取得了显著的进步和成就。现在,我将这份宝贵的经验和知识凝练成一份全面的解题思路与代码论文集合,专为本次赛题设计,旨在帮助您深入理解数学建模的每一个环节。
本次妈妈杯D题可以做如下考虑 (文中代码仅有部分,完整论文格式标准,包含全部代码)
完整内容均可以在文章末尾领取!(部分代码在本帖子里格式混乱,下载后格式正常)
第一个问题是:
问题1:货量预测模型
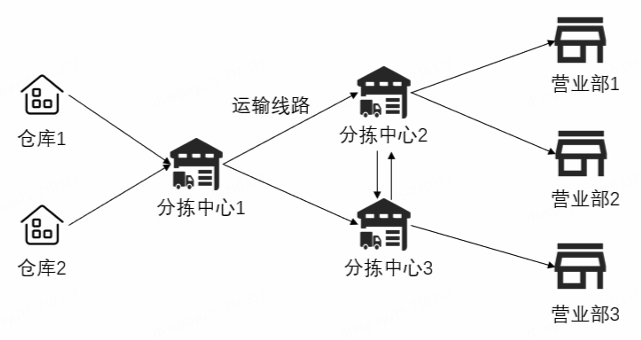
建立货量预测模型,对未来1天各条线路的货量进行预测,并将每条线路的总货量拆解到10分钟颗粒度(结果的时间范围为12月15日14:00至12月16日14:00)。请将预测结果写入结果表1和表2中,并在论文中给出线路编码为“场地3-站点83-0600”和“场地3-站点83-1400”的预测结果。
问题1:货量预测模型的数学建模
1. 问题分析
我们需要建立一个货量预测模型,预测未来1天各条线路的货量,并将每条线路的总货量拆解到10分钟颗粒度。预测的时间范围为12月15日14:00至12月16日14:00。预测结果需要写入结果表1和表2中,并在论文中给出特定线路的预测结果。
2. 数据准备
- 附件2:各线路历史15天的实际包裹量。
- 附件3:各线路近15天的每天预知货量及未来1天在21点时的预知货量。
3. 模型选择
考虑到历史数据和预知货量,我们可以选择时间序列预测模型,如ARIMA、SARIMA、Prophet或LSTM等。这里我们选择SARIMA模型,因为它能够处理季节性数据,适合短途运输的周期性特征。
4. 模型建立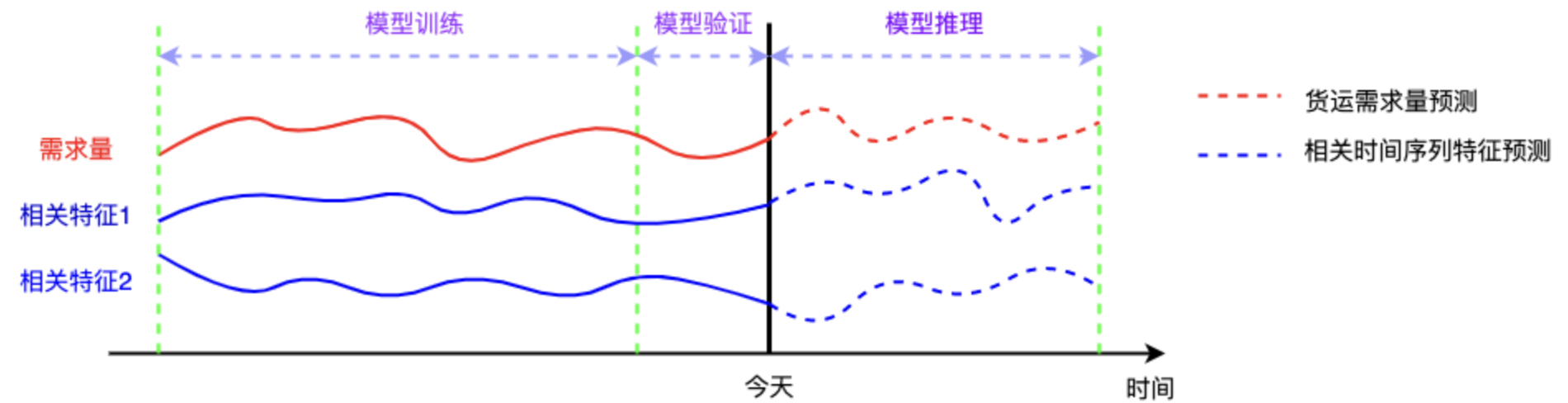
4.1 数据预处理
- 数据清洗:处理缺失值和异常值。
- 数据转换:将历史数据转换为时间序列格式,并提取特征如日期、时间、货量等。
- 数据分割:将历史数据分为训练集和测试集。
4.2 模型参数选择
- 季节性周期:假设每天有两个发运节点(6点和14点),季节性周期为12(每小时6个10分钟间隔)。
- 参数选择:通过ACF和PACF图选择合适的ARIMA参数(p, d, q)。
4.3 模型训练
- 训练SARIMA模型:使用训练集数据训练SARIMA模型。
- 模型验证:使用测试集数据验证模型的预测精度。
4.4 货量预测
- 预测未来1天货量:使用训练好的SARIMA模型预测未来1天各条线路的货量。
- 拆解到10分钟颗粒度:将预测的总货量拆解到10分钟间隔。
5. 结果输出
- 结果表1:各条线路的总货量预测结果。
- 结果表2:各条线路的10分钟颗粒度货量预测结果。
- 论文中特定线路预测结果:给出线路编码为“场地3-站点83-0600”和“场地3-站点83-1400”的预测结果。
6. 模型评估
- 评估指标:使用MAE、RMSE等指标评估模型的预测精度。
- 模型优化:根据评估结果调整模型参数,优化预测精度。
7. 数学公式
SARIMA模型的数学表达式为:
ϕp(B)ΦP(Bs)(1−B)d(1−Bs)Dyt=θq(B)ΘQ(Bs)ϵt \phi_p(B)\Phi_P(B^s)(1-B)^d(1-B^s)^D y_t = \theta_q(B)\Theta_Q(B^s)\epsilon_t ϕp(B)ΦP(Bs)(1−B)d(1−Bs)Dyt=θq(B)ΘQ(Bs)ϵt
其中:
- $ y_t $ 是时间序列数据。
- $ B $ 是滞后算子。
- $ \phi_p(B) $ 和 $ \theta_q(B) $ 分别是AR和MA的非季节性部分。
- $ \Phi_P(B^s) $ 和 $ \Theta_Q(B^s) $ 分别是AR和MA的季节性部分。
- $ \epsilon_t $ 是白噪声。
8. 结论
通过建立SARIMA模型,我们可以有效预测未来1天各条线路的货量,并将总货量拆解到10分钟颗粒度。预测结果将为后续的运输需求与车辆调度提供重要依据。
为了建立货量预测模型,我们可以采用时间序列分析方法,特别是基于历史数据的预测方法。以下是一个基于ARIMA(自回归积分滑动平均)模型的货量预测方法。
1. 数据预处理
首先,我们需要对历史货量数据进行预处理,包括缺失值处理、数据平滑等。假设我们有nnn天的历史货量数据,记为y1,y2,…,yny_1, y_2, \dots, y_ny1,y2,…,yn。
2. 模型选择
ARIMA模型是一个常用的时间序列预测模型,其公式为:
yt=c+∑i=1pϕiyt−i+∑j=1qθjϵt−j+ϵt y_t = c + \sum_{i=1}^p \phi_i y_{t-i} + \sum_{j=1}^q \theta_j \epsilon_{t-j} + \epsilon_t yt=c+i=1∑pϕiyt−i+j=1∑qθjϵt−j+ϵt
其中:
- yty_tyt是时间ttt的货量;
- ccc是常数项;
- ϕi\phi_iϕi是自回归系数;
- θj\theta_jθj是滑动平均系数;
- ϵt\epsilon_tϵt是误差项;
- ppp是自回归阶数;
- qqq是滑动平均阶数。
3. 模型参数估计
我们需要通过历史数据估计ARIMA模型的参数。通常使用最大似然估计法或最小二乘法来估计参数。
4. 模型检验
使用AIC(赤池信息准则)或BIC(贝叶斯信息准则)来选择最优的ppp和qqq值。AIC和BIC的计算公式分别为:
AIC=2k−2ln(L) AIC = 2k - 2\ln(L) AIC=2k−2ln(L)
BIC=kln(n)−2ln(L) BIC = k\ln(n) - 2\ln(L) BIC=kln(n)−2ln(L)
其中:
- kkk是模型参数的数量;
- LLL是模型的最大似然值;
- nnn是样本数量。
5. 货量预测
使用估计好的ARIMA模型对未来1天的货量进行预测。预测公式为:
y^n+1=c+∑i=1pϕiyn+1−i+∑j=1qθjϵn+1−j \hat{y}_{n+1} = c + \sum_{i=1}^p \phi_i y_{n+1-i} + \sum_{j=1}^q \theta_j \epsilon_{n+1-j} y^n+1=c+i=1∑pϕiyn+1−i+j=1∑qθjϵn+1−j
其中y^n+1\hat{y}_{n+1}y^n+1是第n+1n+1n+1天的预测货量。
6. 货量拆解到10分钟颗粒度
将预测的总货量拆解到10分钟颗粒度。假设一天有144个10分钟时间段,记为t1,t2,…,t144t_1, t_2, \dots, t_{144}t1,t2,…,t144。我们可以使用历史数据中的10分钟货量比例来拆解总货量。设第iii个10分钟时间段的货量比例为rir_iri,则第iii个时间段的预测货量为:
y^ti=y^n+1×ri \hat{y}_{t_i} = \hat{y}_{n+1} \times r_i y^ti=y^n+1×ri
7. 结果输出
将预测结果写入结果表1和表2中。对于线路编码为“场地3-站点83-0600”和“场地3-站点83-1400”的预测结果,可以在论文中展示其预测货量及拆解到10分钟颗粒度的详细数据。
示例
假设我们预测“场地3-站点83-0600”的总货量为1000个包裹,其10分钟货量比例为r1,r2,…,r144r_1, r_2, \dots, r_{144}r1,r2,…,r144,则第iii个10分钟时间段的预测货量为:
y^ti=1000×ri \hat{y}_{t_i} = 1000 \times r_i y^ti=1000×ri
通过以上步骤,我们可以建立一个货量预测模型,并对未来1天各条线路的货量进行预测,同时将总货量拆解到10分钟颗粒度。
为了建立货量预测模型,我们可以使用时间序列预测方法,如ARIMA、Prophet或LSTM等。这里我们选择使用Prophet模型,因为它对时间序列数据的处理较为简单且效果较好。我们将基于历史15天的货量数据(附件2)来预测未来1天的货量,并将结果拆解到10分钟颗粒度。
步骤1:数据预处理
首先,我们需要加载并预处理历史货量数据,将其转换为适合Prophet模型输入的格式。
步骤2:模型训练与预测
使用Prophet模型进行训练,并预测未来1天的货量。
步骤3:结果拆解
将预测的总货量拆解到10分钟颗粒度。
Python代码实现
import pandas as pd
from fbprophet import Prophet
import numpy as np
# 步骤1:数据预处理
# 假设附件2中的数据已经加载到一个DataFrame中,列名为['线路编码', '日期', '时间', '货量']
# 例如:df = pd.read_csv('附件2.csv')
# 将日期和时间合并为一个时间戳列
df['ds'] = pd.to_datetime(df[</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2676
2676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









