




-
专业术语解释实时流处理
实时流处理是指将业务系统产生的持续增长的动态数据进行实时的收集、清洗、统计、入库,并对结果进行实时的展示。在金融交易、物联网、互联网/移动互联网等应用场景中,复杂的业务需求对大数据处理的实时性提出了极高的要求。面向静态数据表的传统计算引擎无法胜任流数据领域的分析和计算任务。
-
DolphinDB的流数据框架
DolphinDB内置的流数据框架支持流数据的发布、订阅、预处理、实时内存计算、复杂指标的滚动窗口计算等,是一个运行高效,使用便捷的流数据处理框架。当前我也只是字面理解,后续清楚之后再用白话补充
-
流数据处理框架及概念准备
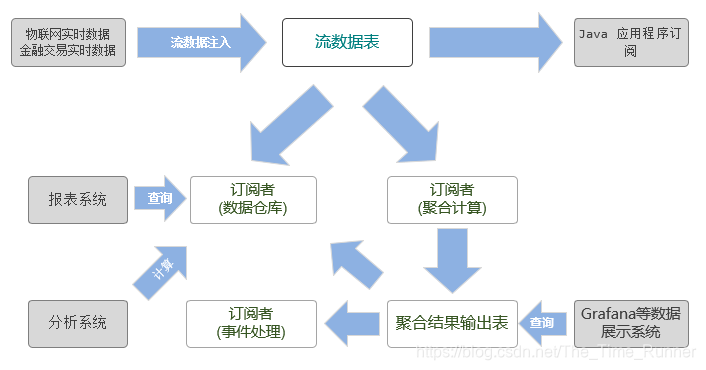
DolphinDB流数据模块采用发布-订阅-消费的模式。流数据首先注入流数据表中,通过流数据表来发布数据,数据节点或者第三方的应用可以通过DolphinDB脚本或API来订阅及消费**流数据。
-
流数据表
流数据表是用以存储流数据、支持同时读写的一种内存表。
发布一条消息等价于向流数据表插入一条记录。可使用SQL语句对流数据表进行查询和分析。
-
发布和订阅
采用经典的订阅发布模式。每当有新的流数据写入时,发布方会通知所有的订阅方处理新的流数据。数据节点使用
subscribeTable函数来订阅流数据。 -
实时聚合引擎
实时聚合引擎指的是专门用于处理流数据实时计算和分析的模块。DolphinDB提供
createTimeSeriesAggregator与createCrossSectionalAggregator函数创建聚合引擎对流数据做实时聚合计算,并且将计算结果持续输出到指定的数据表中。关于如何使用聚合引擎请参考流数据聚合引擎。
-
配置以开启流数据功能
-
配置发布节点
maxPubConnections:发布信息节点最多可连接几个节点。若maxPubConnections>0,则该节点可作为发布节点。默认值为0。 persistenceDir:保存共享的流数据表的文件夹路径。若需要保存流数据表,必须指定该参数。 persistenceWorkerNum:负责以异步模式保存流数据表的工作线程数。默认值为0。 maxPersistenceQueueDepth:以异步模式保存流数据表时消息队列的最大深度(记录数)。默认值为10,000,000。 maxMsgNumPerBlock:发布消息时,每个消息块中最多可容纳多少条记录。默认值为1024。 maxPubQueueDepthPerSite:发布节点消息队列的最大深度(记录数)。默认值为10,000,000。 -
配置订阅节点
subPort:订阅线程监听的端口号。当节点作为订阅节点时,该参数必须指定。默认值为0。 subExecutors:订阅节点中消息处理线程的数量。默认值为0,表示解析消息线程也处理消息。 maxSubConnections:服务器能够接收的最大的订阅连接数。默认值是64。 subExecutorPooling: 表示执行流计算的线程是否处于pooling模式的布尔值。默认值是false。 maxSubQueueDepth:订阅节点消息队列的最大深度(记录数)。默认值为10,000,000。 -
流数据发布
向流数据表(
streamTable函数创建)写入数据,即意味着发布数据。streamTable只是创建流数据表,并不是创建发布表,向
将流数据表共享(通过
share命令),因为流数据表需要被不同会话访问,不被共享的流数据表无法发布数据。# 定义并共享流数据表 share streamTable(10000:0, `timestamp`temperature, [TIMESTAMP, DOUBLE]) as pubTable -
流数据订阅
订阅数据(通过subscribeTable函数实现)
subscribeTable([server], tableName, [actionName], [offset=-1
DolphinDB基础概念理解:流数据处理框架
最新推荐文章于 2025-11-20 14:30:34 发布
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1338
1338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









