



OpenAI刚刚发布了迄今为止最强大的模型系列,为专业知识型工作而打造。

为什么强调“为专业知识型工作而打造”?
我们从它几天前刚刚发布的企业AI调查报告就能看出来,这一重大定位转变的原因:不用AI将被淘汰!OpenAI发布2025企业AI现状报告,揭示先锋与跟随者之间的鸿沟正在极速拉大。
ChatGPT企业版用户的反馈表明,AI每天平均节省40至60分钟的工作时间,重度用户每周节省超过10小时。
基于此,GPT-5.2旨在进一步释放经济价值,在电子表格制作、演示文稿设计、代码编写、图像识别、长文本理解及多步骤复杂项目处理上实现了质的飞跃。
而且,在各项基准测试中全面领先,又狠狠将之前最强的Gemini 3和Claude Opus 4.5按在地上摩擦。
GPT-5.2 Instant、Thinking和Pro三个版本已面向付费用户和开发者开放。
新模型在通用智能、长上下文理解、工具调用及视觉能力上的提升,使其在执行真实世界的复杂任务时表现出前所未有的可靠性。
知识型工作与经济价值的量化突破
GPT-5.2 Thinking是首个在真实场景与专业工作中达到或超过人类专家水平的模型。
在涵盖44个职业的GDPval(国内生产总值价值)评测中,该模型树立了新的技术标杆。
这项评测选取了美国GDP贡献度最高的9个行业,任务包括生成销售演示文稿、会计表格、急诊排班表、制造业图表及短视频等明确的知识型工作。
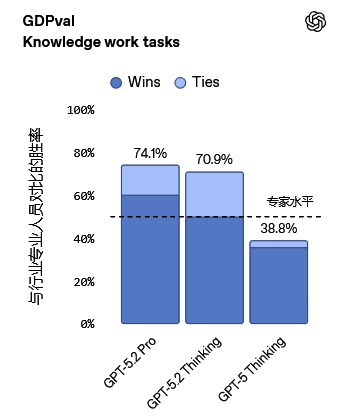
人类专家评审结果显示,GPT-5.2 Thinking在70.9%的对比项目中表现优于或持平于顶尖行业专业人士。
在效率方面,其输出速度比人类专家快11倍以上,而成本仅为人工的1%。这表明在人类监督下,该模型已具备极高的辅助专业工作能力。
在初级投资银行分析师的内部基准测试中,任务涉及为财富500强公司制作格式规范的三表模型或构建杠杆收购模型。
GPT-5.2 Thinking的平均得分从GPT-5.1的59.1%提升至68.4%。并排对比显示,新模型生成的电子表格和幻灯片在复杂度与格式呈现上均有显著进步。

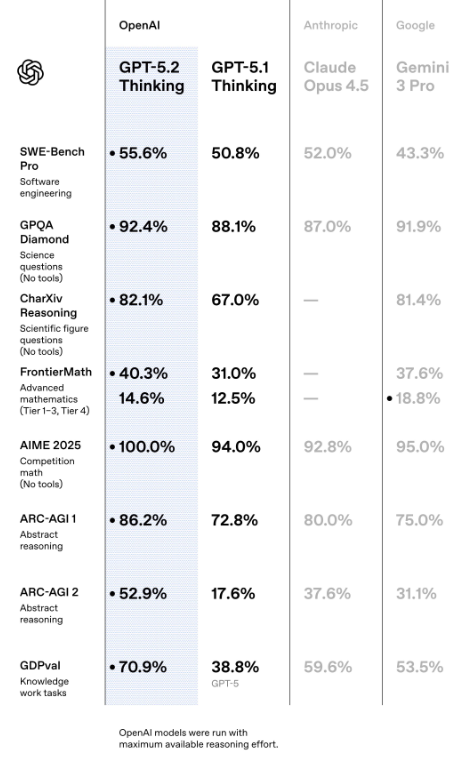
在软件工程领域,GPT-5.2 Thinking在SWE-bench Pro(软件工程基准测试专业版)中取得了55.6%的新成绩。
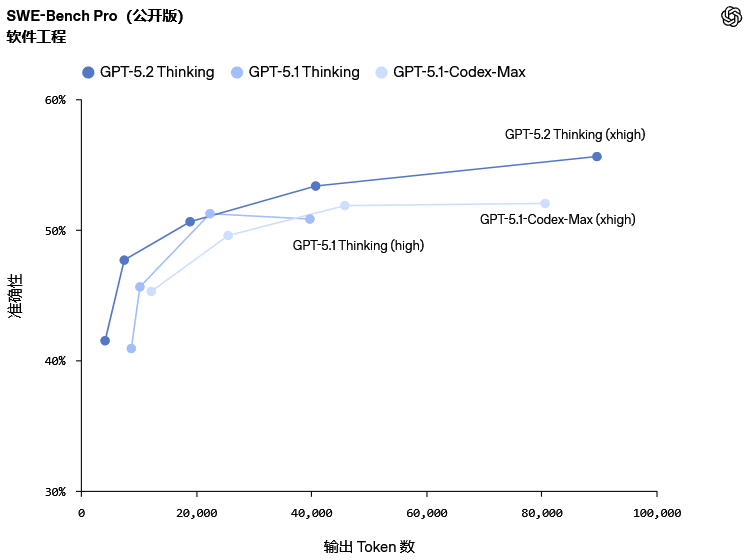
与仅测试Python(一种编程语言)的Verified版本不同,Pro版本涵盖四种语言,旨在模拟更具挑战性、多样性和抗污染性的真实工业场景。
模型需要基于给定的代码仓库生成补丁,以完成真实的软件工程任务。
在SWE-bench Verified测试中,GPT-5.2 Thinking达到了80%的通过率。
这不仅仅是分数的提升,更意味着模型在调试生产环境代码、实现功能需求、重构大型代码库以及减少人工干预的端到端修复交付方面变得更加可靠。
前端开发能力的提升尤为明显。
早期测试表明,GPT-5.2 Thinking在处理涉及3D元素的复杂非传统用户界面工作时表现出色,能够仅凭一个提示词生成高质量的前端代码,成为工程师得力的全栈合作伙伴。
处理海量信息时的准确性是专业工作的核心需求。
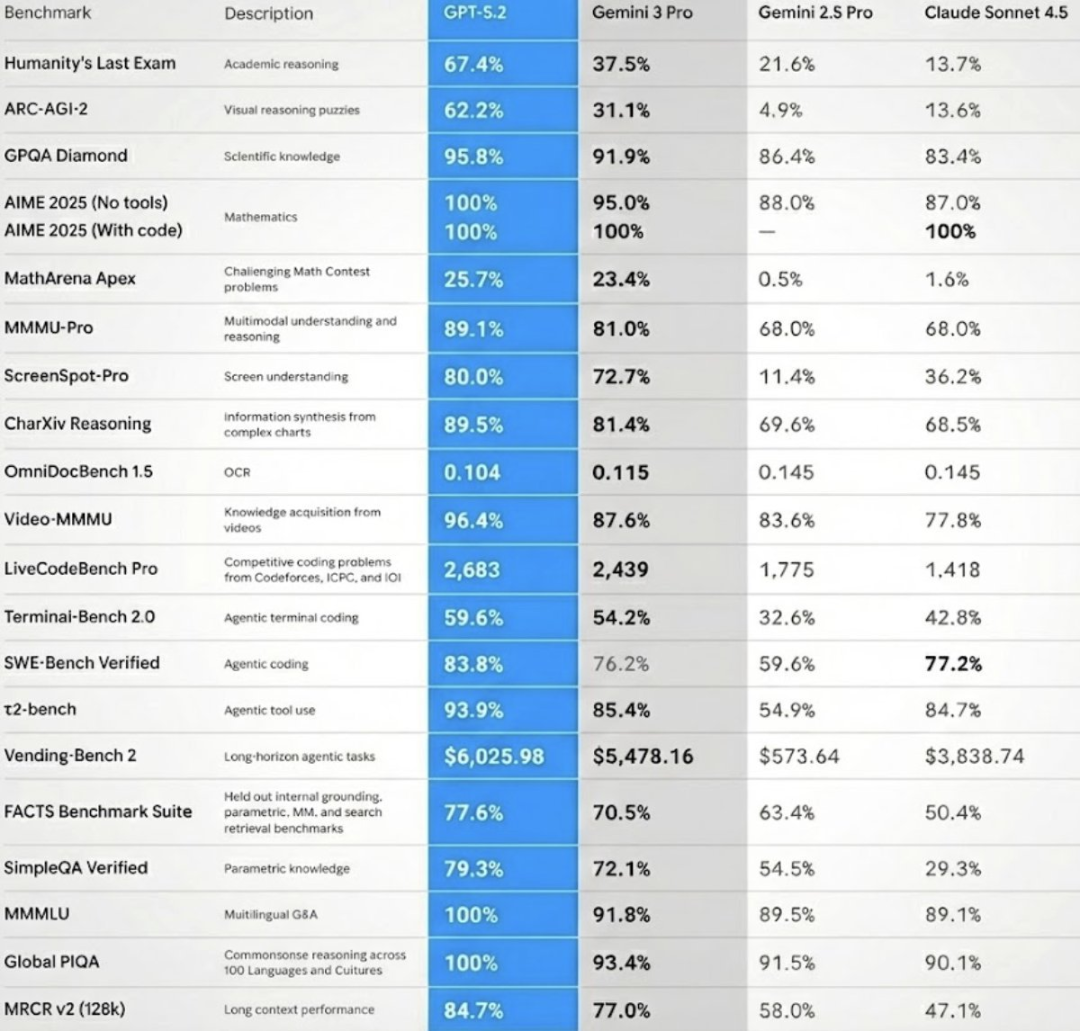
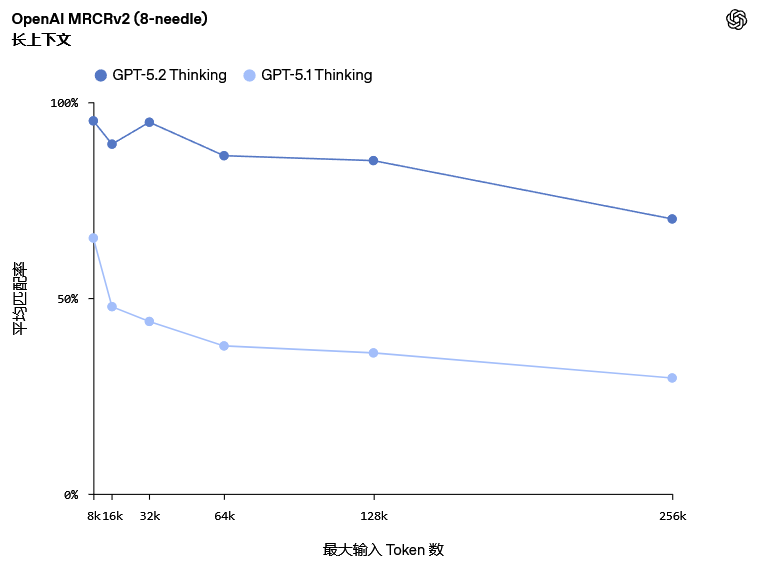
GPT-5.2 Thinking在OpenAI MRCRv2(多轮共指解析第二版)评测中展现了领先的长上下文推理能力。该测试要求模型在包含大量相似请求与回复的草堆中,精准复现特定的用户请求回复。
在深度文档分析等真实任务中,模型需要跨越数十万Token关联信息。
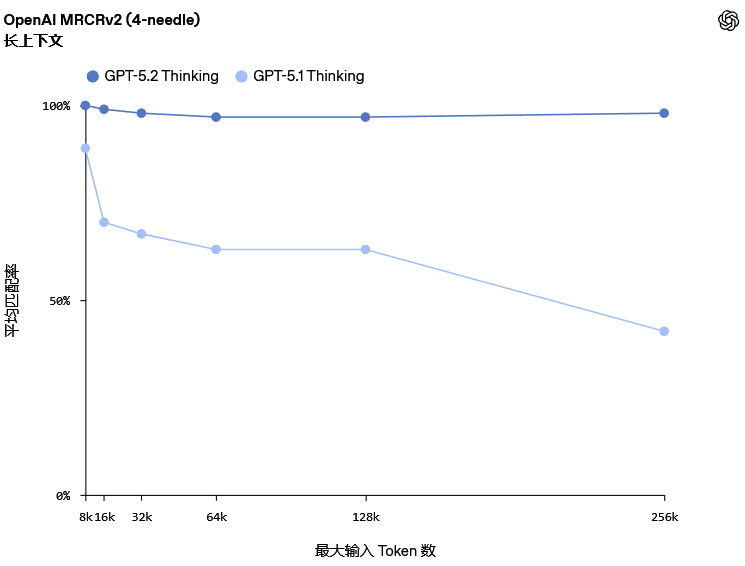
GPT-5.2 Thinking是首个在4-needle(四针)变体评测中,于256k Token长度下实现接近100%准确率的模型。
这使得专业人士能够利用该模型处理报告、合同、研究论文及会议记录等长文档,在数十万字范围内保持逻辑连贯与信息准确,非常适合深度分析与多来源信息综合。
对于超出最大上下文窗口的任务,GPT-5.2 Thinking可配合全新的Responses /compact(紧凑响应)端点使用,扩展有效上下文窗口,支持更依赖工具的长时工作流程。
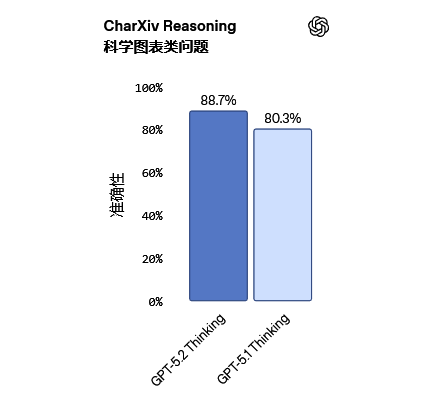
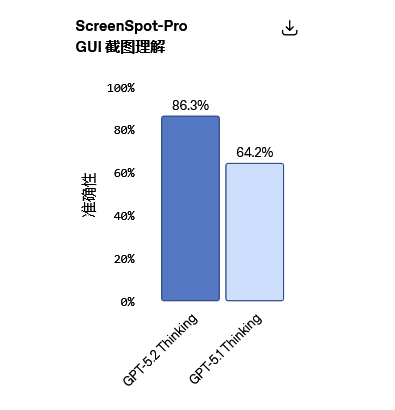
GPT-5.2 Thinking是目前视觉能力最强的模型,其在图表推理和软件界面理解方面的错误率降低了约一半。
在CharXiv Reasoning(基于图表的科学推理)测试中,配合Python工具,模型得分为88.7%。
在ScreenSpot-Pro(专业屏幕识别)测试中,模型需对金融、运营、设计等专业场景的高分辨率图形用户界面截图进行推理。测试建议启用Python工具以获得最佳效果。
相比前代模型,GPT-5.2 Thinking对图像元素的空间位置理解更深刻。
即便在低质量图像中,模型也能识别出主板上的组件并给出大致准确的边界框,而GPT-5.1在此类任务中往往只能标出少数部分且空间关系混乱。这种能力对于依赖相对布局解决问题的任务至关重要。

在Tau2 bench Telecom(电信领域工具调用基准)测试中,GPT-5.2 Thinking取得了98.7%的成绩。该测试模拟了用户与客服的多轮对话,要求模型使用工具完成任务。
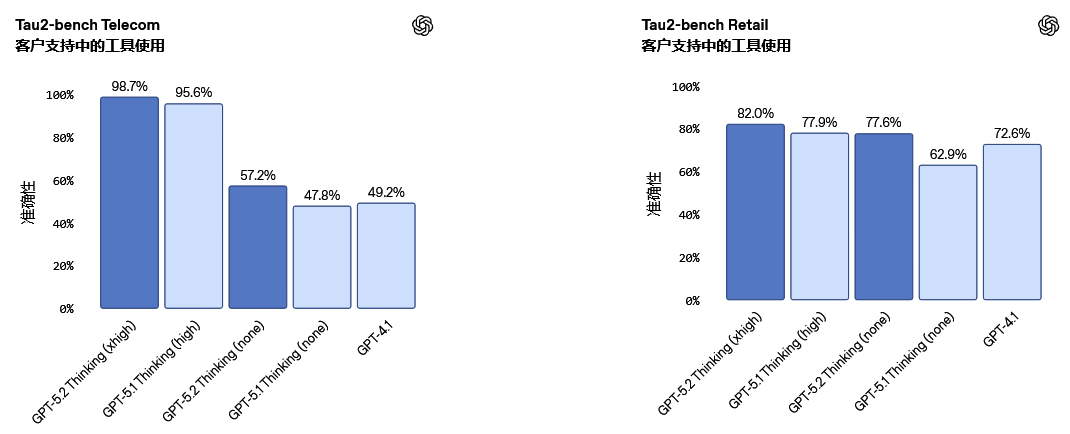
这意味着模型在处理长程、多轮任务时更加可靠。在对延迟敏感的场景下,即使在reasoning.effort='none'(无推理增强)模式下,其性能也大幅领先于旧版本。
实际应用中,当面对航班延误、改签、住宿安排及医疗协助等复杂且需要多步骤解决的客服问题时,GPT-5.2能够有效地在多个代理之间协调工作流程。
它可以处理整个任务链,从数据提取到分析并生成最终结果,显著减少了步骤间的中断,生成的方案比GPT-5.1更加完整。
科学探索与高难度数学突破
GPT-5.2 Pro和Thinking版本是目前最能支持科研进展的模型。
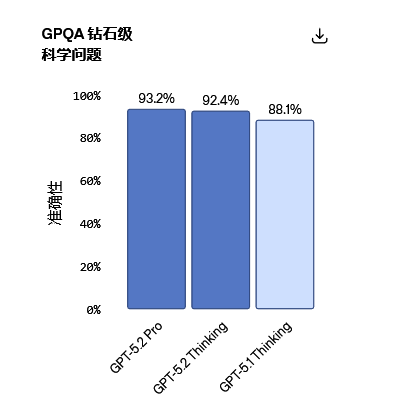
在研究生级防Google问答基准测试GPQA Diamond(钻石级通用科学问答)中,GPT-5.2 Pro得分93.2%,Thinking版本得分92.4%。
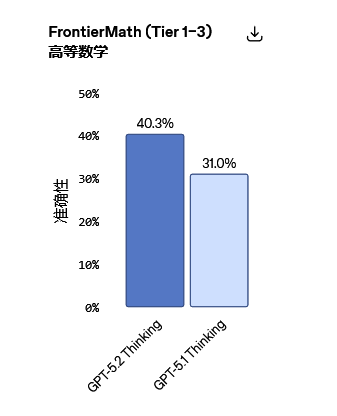
在专家级数学评测FrontierMath (Tier 1–3)中,GPT-5.2 Thinking解决了40.3%的问题,树立了新技术标杆。
在HMMT(哈佛-麻省理工数学竞赛)中,其准确率高达99.4%。
在一项关于统计学习理论开放问题的研究中,GPT-5.2 Pro在设定清晰的情境下提出了一个证明,并经由作者核实及外部专家审阅通过。

这证实了前沿模型在严密的人类监督下已能实质性地辅助数学研究。
ARC-AGI-1 (Verified)是衡量通用推理能力的重要基准。GPT-5.2成为首个突破90%阈值的模型,得分为86.2%,且达到该性能的成本比去年降低了约390倍。
在难度更高、侧重流体推理的ARC-AGI-2 (Verified)中,GPT-5.2 Thinking得分为52.9%,刷新了链式思维模型的纪录;Pro版本更是达到了54.2%。
这些数据反映了模型在多步推理、数值准确性及处理复杂技术问题稳定性上的全面增强。
事实性,安全性与定价策略
GPT-5.2 Thinking的幻觉率显著降低。
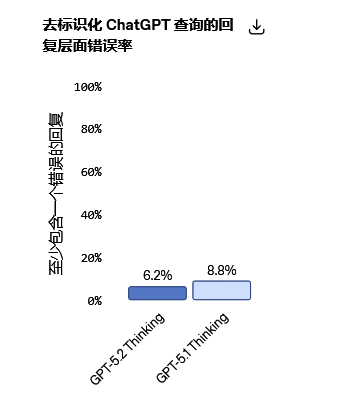
在去标识化的查询样本中,含有错误的回答频率较GPT-5.1 Thinking减少了38%。论断层面的错误率远低于回复层面的错误率,这使得模型在研究、写作和决策支持等任务中更加可信。
安全性方面,OpenAI延续了安全补全研究。针对各类敏感话题,GPT-5.2 Instant和Thinking的不理想回复显著减少。
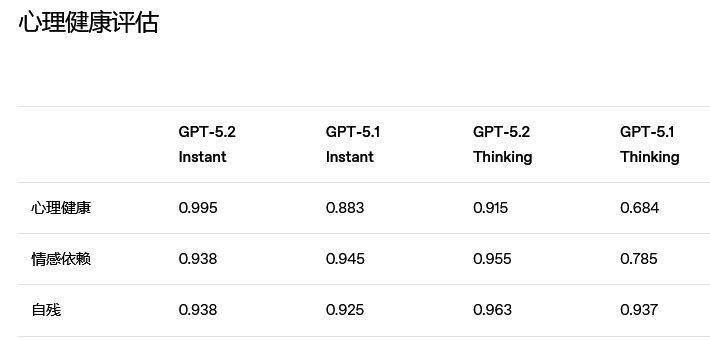
此外,年龄预测模型正在逐步上线,以自动识别未满18岁的用户并应用相应的内容保护措施。
GPT-5.2系列包含三款模型,分别针对不同需求进行了优化:
GPT-5.2 Instant:高效的日常主力模型,擅长信息查询、翻译和技术写作,解释清晰,风格自然。
GPT-5.2 Thinking:专为深度工作打造,擅长编码、长文档总结、数学推导及复杂规划,结构清晰,细节丰富。
GPT-5.2 Pro:应对高难度问题的最智能选择,错误率最低,编程和复杂领域表现最佳,支持设置推理参数及全新的xhigh(超高)推理强度。
定价方面,GPT-5.2 Token单价依然高得离谱,但官方表示,由于更高的Token效率和任务一次性成功率,达到同等质量的整体成本在多项智能体评测中反而更低。
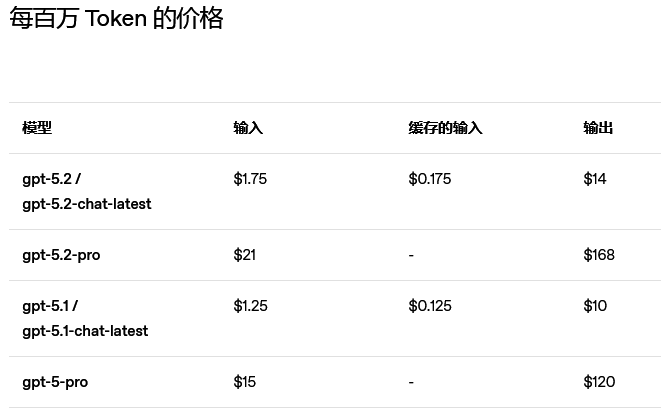
在API中,GPT-5.2 Thinking对应gpt-5.2,Instant对应gpt-5.2-chat-latest,Pro对应gpt-5.2-pro。GPT-5.1将继续保留三个月。
GPT-5.2发布,捍卫了其AI领域的王者地位。
参考资料:
https://openai.com/zh-Hans-CN/index/introducing-gpt-5-2/

















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









