




12月17日,小米人车家全生态合作伙伴大会上,MiMo大模型负责人罗福莉首次公开亮相
95 后罗福莉,四川宜宾人,本科就读于北京师范大学计算机专业,硕士毕业于北京大学计算语言学研究所计算语言学专业。
求学期间就在人工智能领域顶级国际会议 ACL 上发表了 8 篇论文,其中两篇为第一作者。
毕业就职阿里达摩院。
2022 年加入 DeepSeek 母公司幻方量化从事深度学习相关工作,后又担任 DeepSeek 的深度学习研究员,参与研发 DeepSeek-V2 等模型。
今年初传闻雷军曾希望用千万年薪挖角罗福莉,邀请她到小米带领团队从事 AI 大模型研究。
11 月本人正式官宣加入 Xiaomi MiMo。
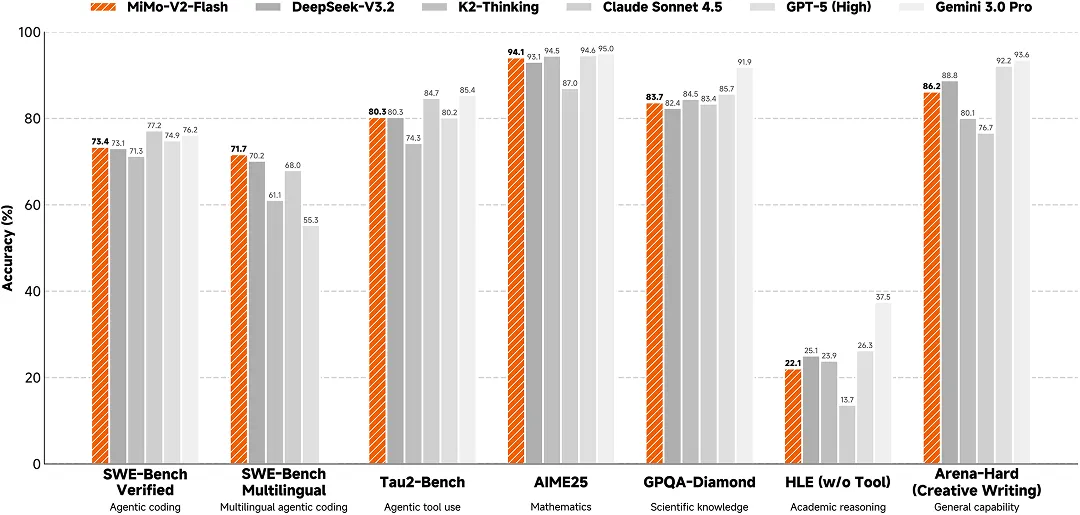
MiMo-V2-Flash 是小米首个推理大模型。也是罗福莉正式宣布加入小米后的第一个开源大模型。
MiMo-V2-Flash 是小米自研、参数量达到 309B 的混合专家(MoE)模型,激活 15B 参数,在代码能力上比肩行业标杆 Claude 4.5 Sonnet,但推理价格只有对方的 2.5%,生成速度却是对方的 2 倍。综合性能登顶全球开源 TOP 2。
架构创新突破显存与算力瓶颈
MiMo-V2-Flash 在注意力机制上采用了 5:1 的混合注意力结构。它将 Sliding Window Attention(SWA,滑动窗口注意力)与 Global Attention(GA,全局注意力)相结合。
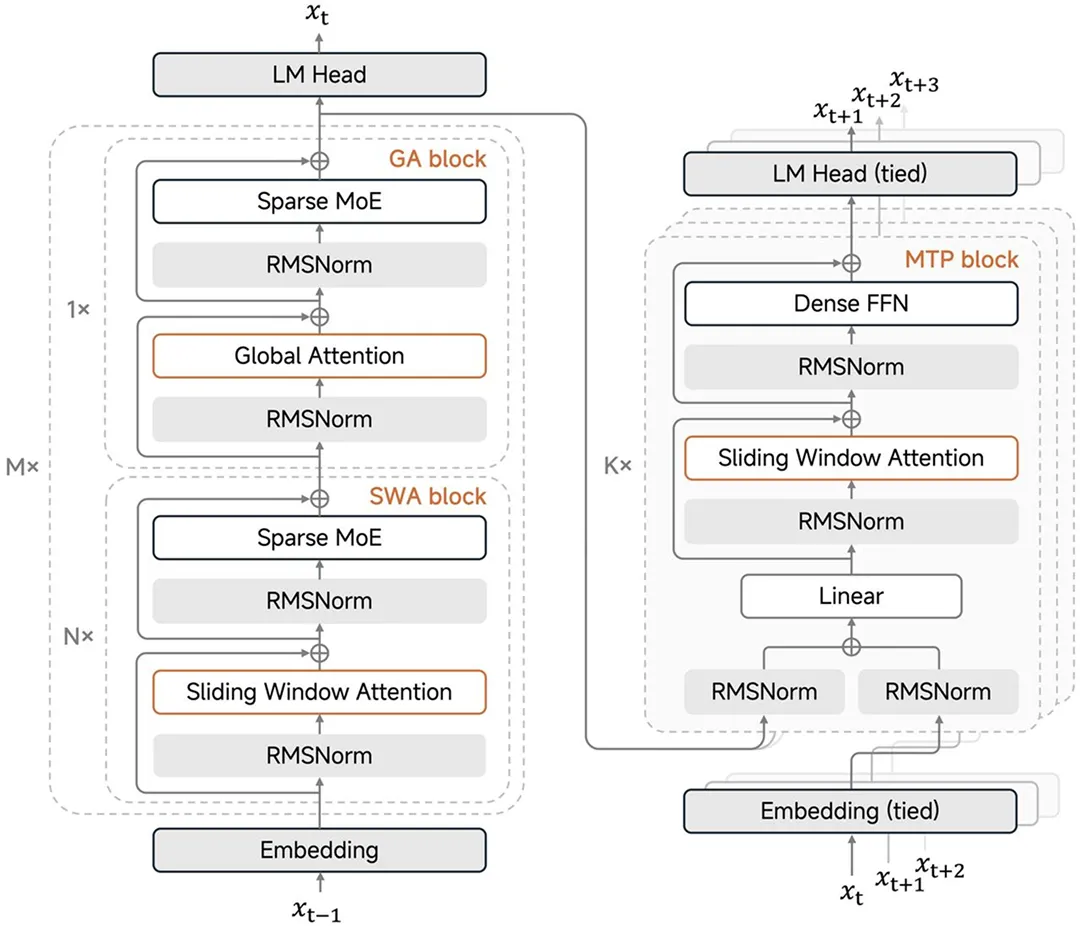
SWA 就像是一个只会关注最近 128 个 token 的聚光灯,它处理速度快,显存占用极其有限且固定;而 GA 则像是一个掌控全局的雷达,负责捕捉长距离的依赖关系。
这种 5:1 的配比经过了大量前期实验验证。相比于试图用数学技巧逼近全关注力的 Linear Attention(线性注意力),这种混合结构展现出了更佳的鲁棒性。它既保留了 Transformer 捕捉复杂逻辑的能力,又通过大量的滑动窗口层强制将 KV Cache 限制在一个极小的固定范围内。
这对于推理基础设施(Infra)来说是一个巨大的福音。
固定的 KV Cache 意味着显存占用变得可预测,工程师不再需要为长文本预留巨额的安全冗余,从而可以在同一张显卡上塞入更多的并发请求。
原生 32K 并外扩至 256K 的训练长度,让这个模型在处理长文档、代码库分析等任务时游刃有余,而不会像传统模型那样随着文本变长而不仅变慢,还可能直接显存溢出(OOM)。
在解决显存问题的同时,MiMo-V2-Flash 引入了 MTP(Multi-Token Prediction,多 token 预测)技术。
传统的大模型推理是自回归的,即每生成一个词,都需要把庞大的模型权重从显存搬运到计算核心一次。在显存带宽有限的今天,这种模式导致 GPU 的计算核心经常处于等数据的闲置状态。
MTP 的核心思想非常直观:既然都要搬运一次权重,为什么不一次性多猜几个词?
MiMo-V2-Flash 在训练阶段就引入了 MTP 任务,让模型在预测下一个 token 的同时,还对多个未来 Token 具备可预测性。在推理阶段,这种能力被转化为一种并行验证机制。
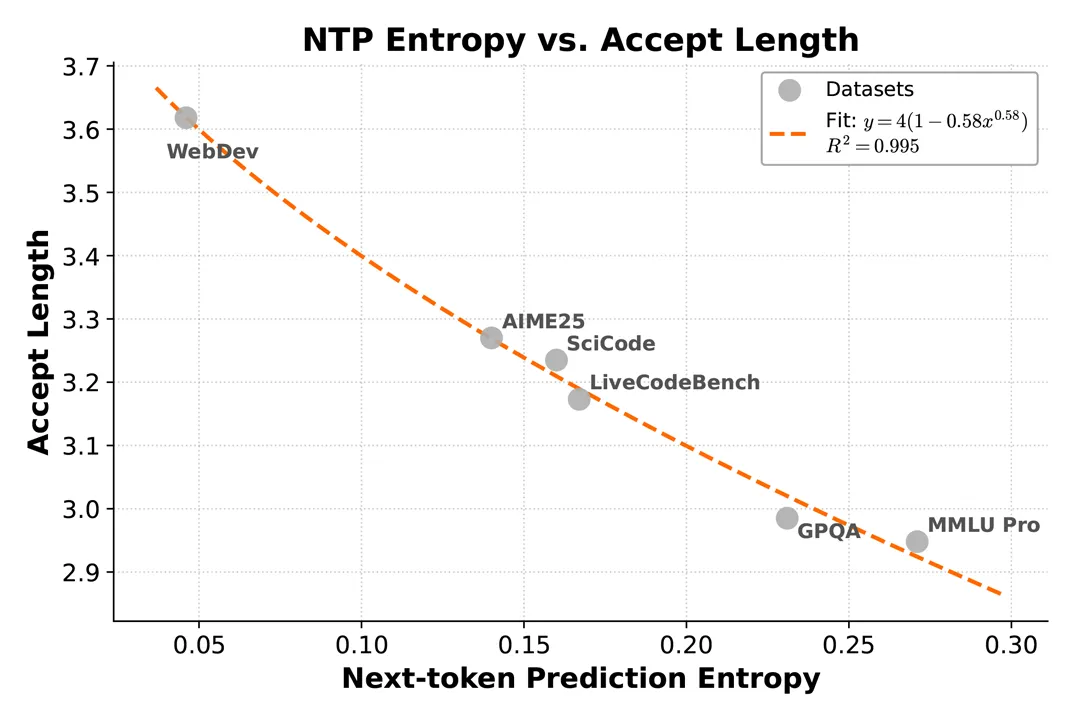
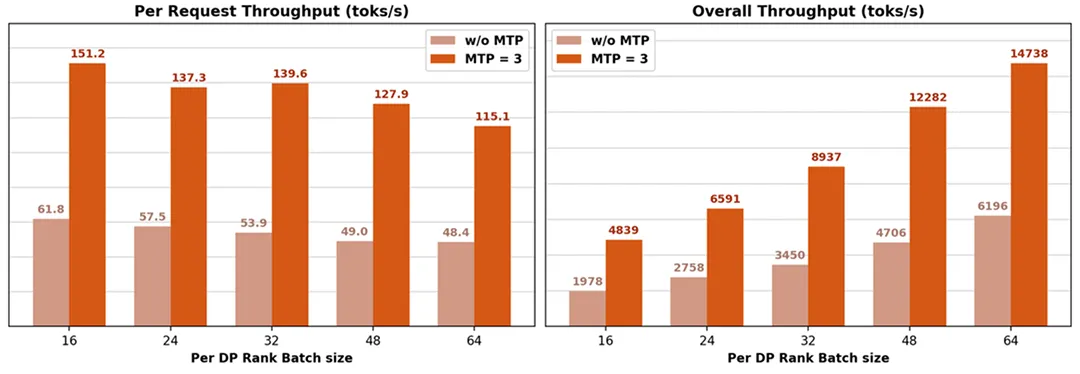
实测数据显示,在开启 3 层 MTP 的情况下,模型可以实现 2.8 到 3.6 的接收长度,带来了 2.0 到 2.6 倍的实际推理加速比。
这一技术在大 Batch(批处理)场景下尤为关键。传统解码方式在大 Batch 下会彻底卡死在显存带宽上,而 MTP 提高了单次显存读取的利用率,显著提升了吞吐量。
更有意思的是 MTP 对强化学习(RL)训练的赋能。
在强化学习中,On-Policy(在线策略)训练通常被认为更稳定,但由于它需要小 Batch 采样,往往会导致 GPU 利用率低下。而 Off-Policy(离线策略)虽然吞吐量大,但稳定性较差。
MTP 巧妙地解决了这个矛盾。
通过扩展 token 级的并行度,它让小 Batch 的 On-Policy 训练也能跑满 GPU 算力。
特别是在推理采样的后期,当某些样本生成的序列极长,导致有效 Batch Size 缩减时,MTP 能显著提升计算效率,填补算力空隙,降低整体延迟。
蒸馏范式提升强化学习训练效率
拥有了强大的基座模型和高效的推理架构,如何让模型更聪明?小米提出了一种全新的后训练范式:MOPD(Multi-Teacher On-Policy Distillation)。
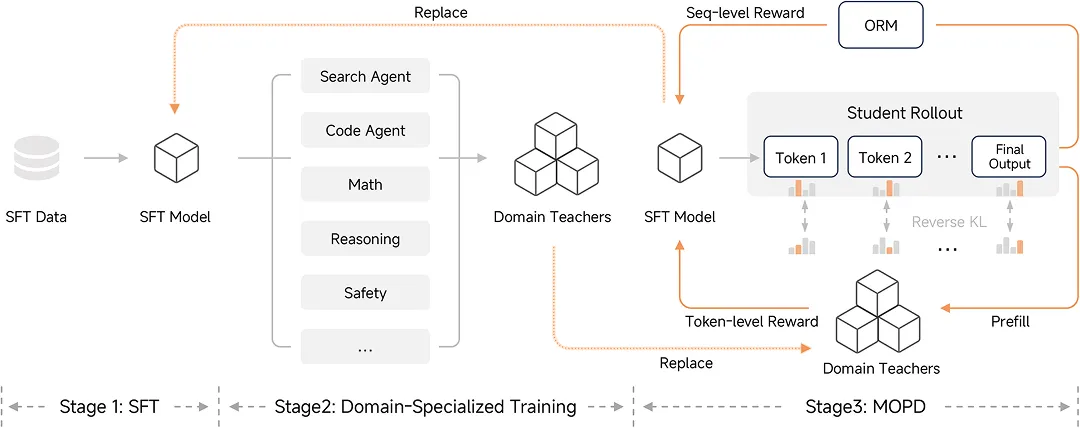
在传统的后训练流程中,SFT(监督微调)加上 RL(强化学习)是一条昂贵的路径,尤其是高质量的 Reward Model(奖励模型)和大规模的采样计算,往往需要消耗数倍于预训练的资源。
MOPD 不再依赖单一的奖励信号,而是引入了多位专家教师。
这些教师模型在各自的领域经过了 SFT 和 RL 的充分训练。学生模型(即 MiMo-V2-Flash)基于自身的策略分布进行采样(Rollout),然后由这些教师提供 Token-level(词元级)的密集奖励信号。
相比于传统 RL 只有在生成结束后才给一个稀疏的好/坏评价,MOPD 让学生在生成的每一步都能收到反馈。
数据表明,MOPD 仅需传统 SFT+RL 流程不到 1/50 的计算资源,就能让学生模型追上教师模型的峰值能力。
更重要的是,这是一个解耦的设计。
开发者可以灵活地引入新的教师模型,或者集成 ORM(Outcome Reward Model,结果奖励模型)。
这种架构天然支持教学相长的闭环迭代:经过蒸馏变强的学生模型,在下一轮迭代中可以摇身一变成为更强的教师,推动模型能力的螺旋式上升。
这种高效的后训练机制,是 MiMo-V2-Flash 能够在 Agent 测评基准上进入全球开源模型 Top 2 的核心动力之一。
开源生态与工程化落地的实测
小米这次不仅开源了模型权重,更是直接将推理代码贡献给了 SGLang 社区,真正做到了开箱即用。
MiMo-V2-Flash 的 API 定价极其激进:输入 0.7 元 / 百万 tokens,输出 2.1 元 / 百万 tokens。

结合其在代码生成和逻辑推理上的强悍表现,这个定价直接冲击了现有的市场格局。对于开发者而言,这意味着可以用极低的成本构建复杂的 Agent 应用。
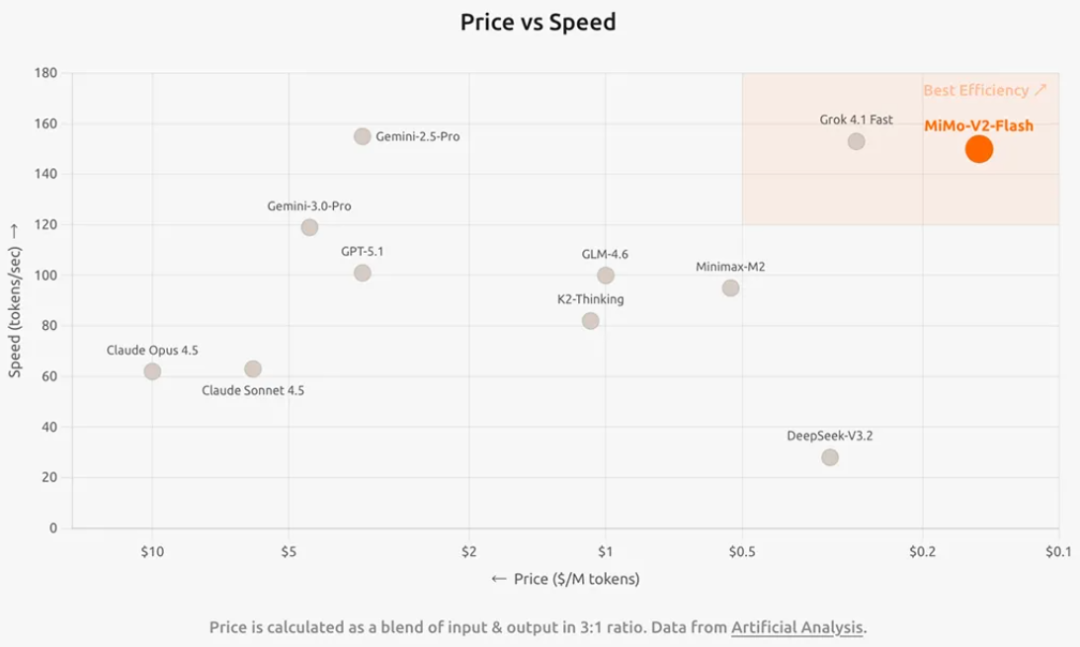
在实际工程测试中,得益于模型结构与推理框架(SGLang)的深度融合,单机性能表现优异。
在 Prefill(预填充)阶段,单机吞吐量可达 50000 tokens/s。
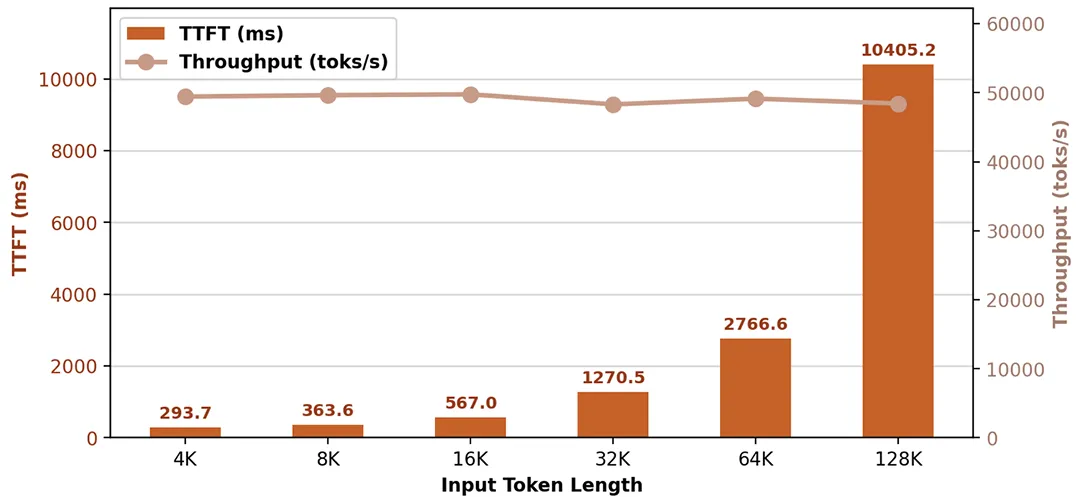
处理超长上下文的 prompt 几乎是瞬间完成。
而在 Decode(解码)阶段,即使在 16K 的长上下文背景下,通过 3 层 MTP 加速,单机吞吐依然能维持在 5000 到 15000 tokens/s,单请求吞吐达到 151 到 115 tokens/s。
用户在使用基于 MiMo-V2-Flash 的 coding 助手时,代码生成的流畅度将接近人类的阅读速度,不再有那种等字蹦出来的焦灼感。
为了验证其作为 Agent 基座的能力,团队进行了多项真实场景测试。
例如编写一个简单的操作系统,
模拟太阳系运行轨迹,

用代码画一颗圣诞树,
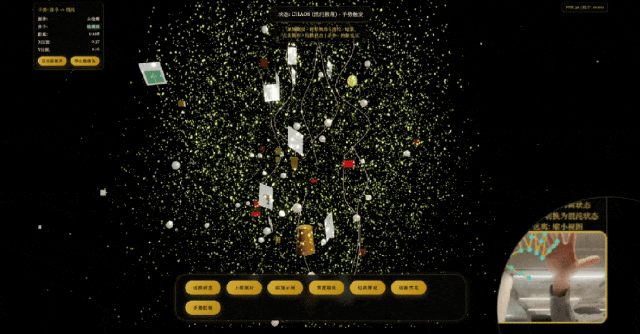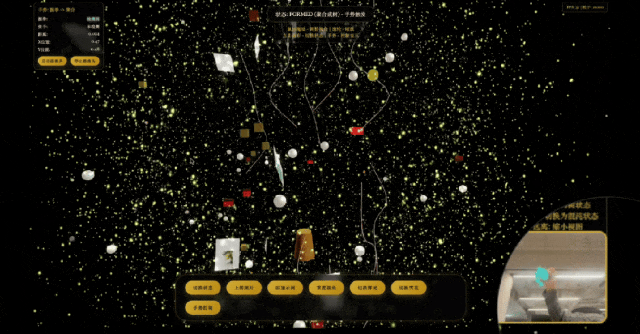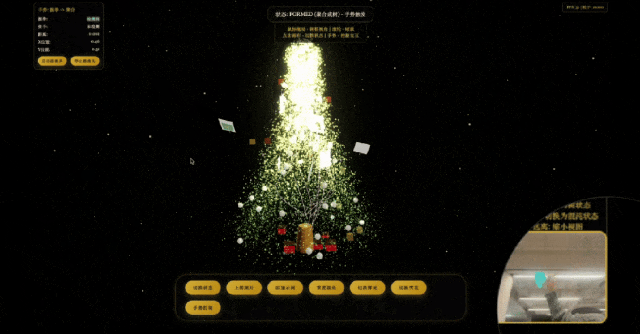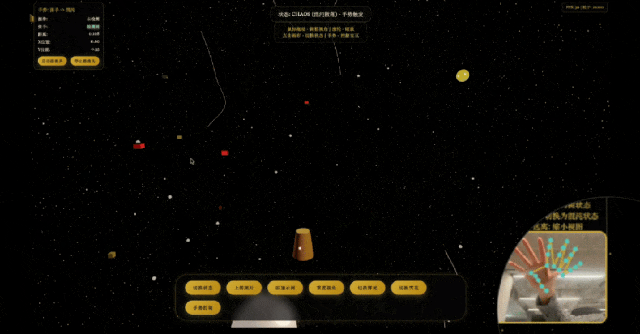
模型展现出了初具规模的描述世界的能力。它不仅能理解复杂的指令,还能生成结构严谨、逻辑自洽的代码。
目前,模型已在 HuggingFace 遵循 MIT 协议开源,技术报告同步放出。API 服务也已上线,并兼容 Claude Code、Cursor、Cline 等主流开发框架。
对于开发者和企业来说,MiMo-V2-Flash 提供了一个在性能、成本和速度之间取得极致平衡的新选择。
免费试用:
https://aistudio.xiaomimimo.com/
参考资料:
https://mimo.xiaomi.com/blog/mimo-v2-flash
https://github.com/XiaomiMiMo/MiMo-V2-Flash
https://huggingface.co/xiaomimimo/MiMo-V2-Flash
https://lmsys.org/blog/2025-12-16-mimo-v2-flash/

















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









