



智谱开源SCAIL、RealVideo、Kaleido与SSVAE四项底层技术,精准击破视频生成中可控性差、实时性弱、训练成本高三大顽疾。

视频生成技术精细化控制难、复杂时空建模慢、训练成本高昂始终是横亘在技术与应用之间的三座大山。
智谱刚刚开源的四项核心技术成果,从底层原理出发,分别在角色动画的物理合理性、流式生成的低延迟架构、多主体的一致性表达以及扩散模型的训练效率上提供了扎实的工程解法。
这四项技术是对视频生成物理规律与数学本质的一次深度解构。
SCAIL重塑影视级角色动画的空间逻辑
让静态照片动起来不难,难的是让它动得符合物理规律。
传统姿态控制角色动画(Pose Controlled Character Animation)主要依赖2D骨骼点。
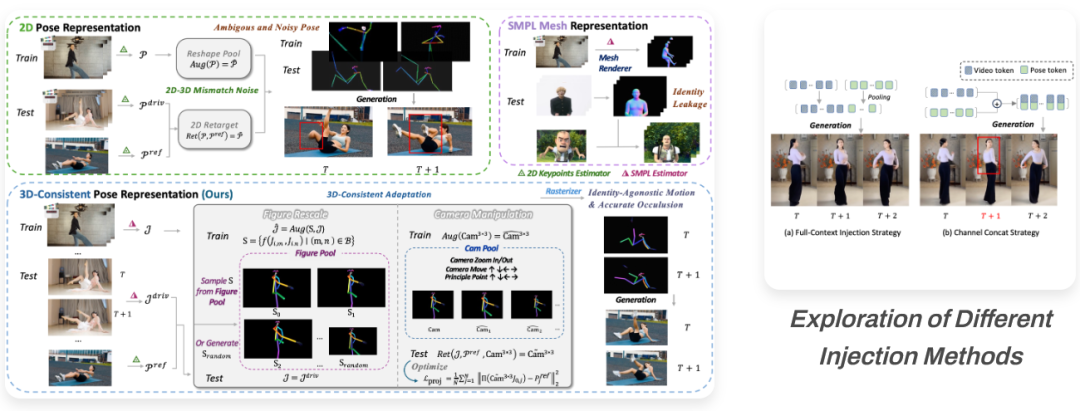
这种方法本质上是在二维平面上做文章,它丢失了最关键的深度信息。
一旦遇到空翻、街舞等肢体大幅度重叠或遮挡的复杂动作,AI往往会混淆前后肢体的关系,导致胳膊穿过胸腔、大腿反关节弯曲等肢体崩坏现象。
这种基于2D信息的推演,注定无法满足影视级的专业需求。
SCAIL(Studio-grade Character Animation via In-context Learning)旨在解决这一空间逻辑缺失的问题。
它抛弃了传统的2D关键点方案,也未采用带有身份信息的SMPL Mesh方案,而是另辟蹊径,利用3D关节点估计技术,在三维空间中将肢体的拓扑结构光栅化渲染为柱体骨骼。
这种3D一致性姿态表征(3D-Consistent Pose Representation)的优势在于显式编码了深度与遮挡关系。
对于模型而言,画面不再是平面的像素集合,而是有前后景深的立体空间。
模型能够清晰地感知到哪根骨骼在前、哪根在后,从而在处理复杂遮挡场景时,依然能保持肢体结构的完整性。
这不仅解决了崩坏问题,更为后续的运动信息保持增强与重定向提供了坚实的几何基础。
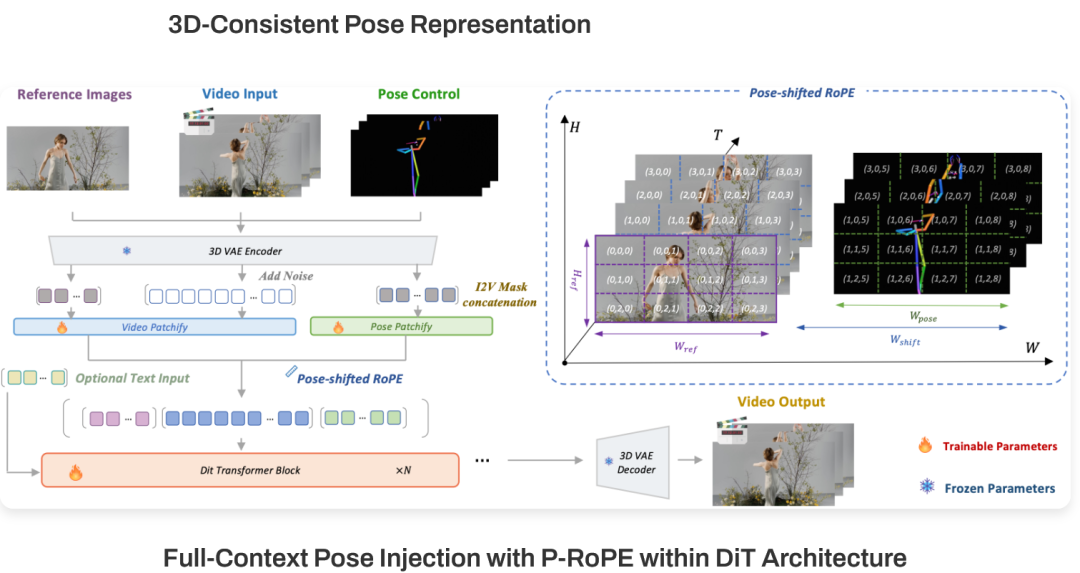
解决了空间问题,还得解决时间问题。
传统ControlNet或Adapter通常采用逐帧控制,就像让一个画家只盯着当前这一秒作画,完全不考虑上一秒动作的连贯性,导致生成的视频抖动、不自然。
SCAIL在DiT(Diffusion Transformer)架构中引入了全上下文姿态注入机制(Full-Context Pose Injection)。它通过Pose-Shifted RoPE(姿态偏移旋转位置编码),在序列维度上区分控制信号。
这相当于强迫模型在生成每一帧时,必须同时看到整个动作序列。
模型不再是机械地逐帧堆叠,而是具备了时空推理(Spatio-temporal reasoning)能力,能够根据上下文推断出动作的流动趋势。
这种机制使得SCAIL不仅在单人复杂运动上表现出色,更能扩展到多人交互场景,确保人物之间的互动符合物理与视觉逻辑。
RealVideo通过流式架构突破实时交互瓶颈
视频生成模型的效果虽然惊艳,但动辄分钟级的生成等待时间,直接切断了其在实时对话场景下的应用可能。
用户提问后漫长的空白期,足以消磨掉所有的交互热情。
RealVideo旨在打破这一延迟诅咒,将视频生成的首响延迟从数分钟压缩至2至3秒。
这一数量级的跨越,使得实时视频对话从概念走向了现实。
用户提供一张照片并提问,短短几秒后,画面中的数字人便能流畅作答,视听体验与真人视频通话几无二致。
实现这一突破的核心在于对生成架构的彻底改造。
RealVideo采用自回归模型对抗训练,引入Self-forcing框架。
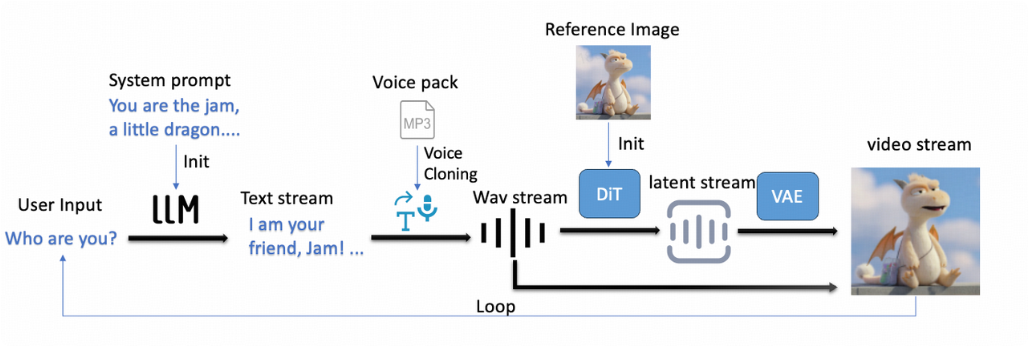
在双向视频生成模型作为教师模型的监督下,模型能够迅速掌握自回归生成的模式。配合对抗损失监督,视频生成中常见的画面漂移问题得到了有效抑制。
为了在长对话中保持画面的稳定性与连贯性,RealVideo引入了滑动注意力窗口与Dynamic Sink RoPE策略。
视频生成就像铺设铁轨,如果模型始终要背负着过去所有帧的记忆前行,计算量会随着时间呈指数级增长。
滑动窗口策略设定了一个常数级的上下文窗口,当视频长度超过阈值时,自动截断旧的kv cache。这为无限时长的视频生成扫清了显存障碍。
同时,Dynamic Sink RoPE策略确保了相对位置编码在训练与推理阶段的一致性,防止人物形象随时间推移发生形变。这套组合拳保证了即便是长达数分钟的连续演讲或对话,人物形象依然稳定如初。
在工程实现层面,RealVideo搭建了一套并行的流水线Pipeline。
它将大模型对话、文本转语音、视频生成、VAE解码等环节进行精细的时间切片与重叠调度。
CPU负责逻辑处理,GPU负责并行计算,API调用穿插其中。
这种极致的算力榨取,最大限度地降低了首响延迟,提高了生成帧率,让AI交互真正具备了流式的快感。
Kaleido构建跨配对数据解耦多主体特征
多主体(Multi-Subject)视频生成一直是业界的痛点。
当画面中同时出现人物与特定物体,或者多个人物时,现有模型往往会偷懒,直接复制参考图像的像素,甚至将背景、姿态等无关信息误认为是主体的身份特征。
这就导致生成的人物像是在平移纸片,动作僵硬,缺乏表现力。
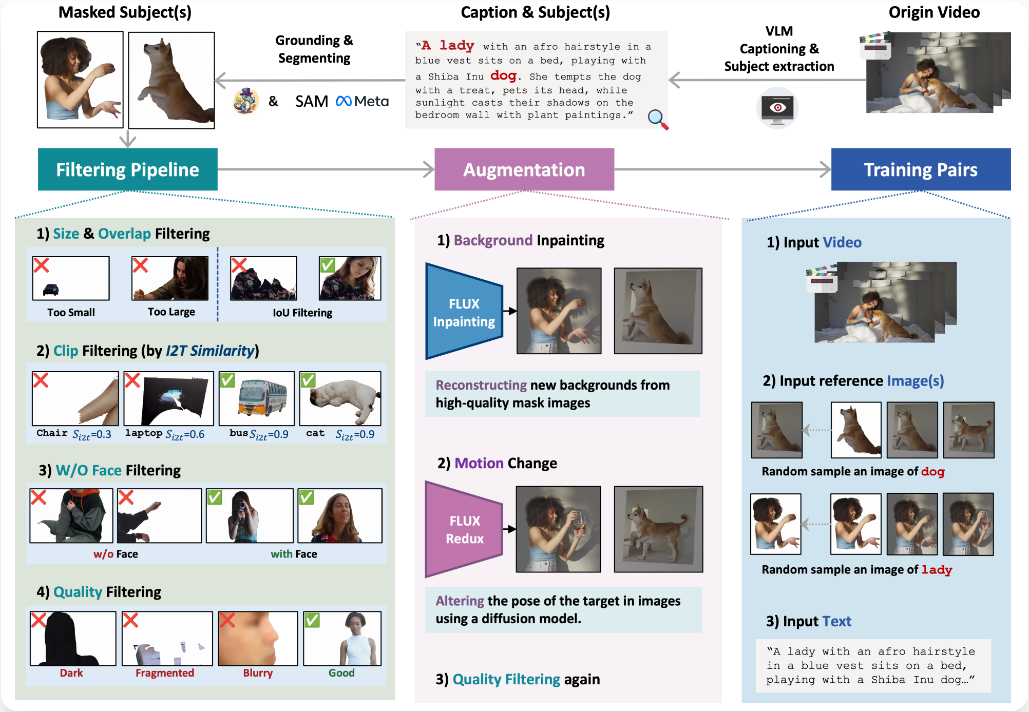
Kaleido提出了一套从数据构建到参考信息注入的完整解决方案,核心在于教会模型什么是主体,什么是背景。
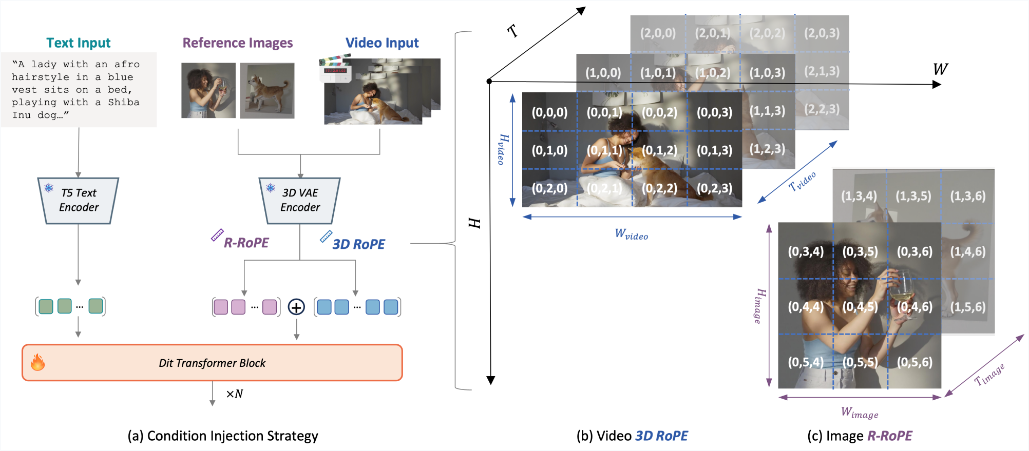
在模型架构层面,Kaleido引入了Reference Rotary Positional Encoding(R-ROPE)。
在DiT架构中,如何区分参考图像的Token与生成视频的Token是一个难题。
R-ROPE机制对参考图像的Token进行了独立的旋转位置编码。通过显式的空间位移,模型在计算注意力时,能够清晰地划定不同主体与视频帧之间的边界。
这就像是给每个主体贴上了独立的电子标签,防止了特征的相互混淆与干扰。
单纯依靠模型结构调整还不够,数据质量同样关键。
针对背景纠缠问题,Kaleido构建了Cross-Paired数据构建管线。
通过背景修复与运动增强技术,团队合成大量跨配对训练数据。训练过程中,模型看到的是同一个主体出现在完全不同的背景和姿态中。
这种强迫式的训练策略,逼迫模型必须学会从复杂的背景中抠出真正的主体特征,而非简单地记忆像素。这种深度的解耦能力,使得Kaleido在多主体及受控背景下的生成效果达到了开源领域的顶尖水平。
SSVAE利用谱分析从本质提升训练效率
视频生成模型的训练是一场算力与资金的燃烧竞赛。
业界传统的优化思路通常聚焦于提升VAE(变分自编码器)的像素级重构质量,认为还原度越高,生成效果越好。
但智谱的研究团队发现了一个反直觉的现象:像素级的重构质量并不完全等同于扩散模型的训练效率。
相比于画面还原的精细度,隐变量(Latent)的结构特征对扩散模型的收敛速度贡献更大。
SSVAE(Spectral-Structured VAE)便是基于这一发现诞生的成果。

它不再仅仅盯着像素误差,而是从谱分析(Spectral Analysis)的第一性原理出发,探索影响训练效率的深层统计特性。
通过大量实验分析,团队发现具有时空低频偏置(Low-Frequency Bias)和通道特征值少模式偏置(Few-Mode Bias)的隐空间分布,最适合扩散模型的胃口。
简单来说,如果隐空间的数据分布过于杂乱无章(高频、多模式),扩散模型需要花费大量时间去学习这些复杂的分布;而如果通过正则化手段,将隐空间约束为结构清晰、低频为主的分布,扩散模型的学习难度将大幅降低。
SSVAE正是据此优化了训练目标。
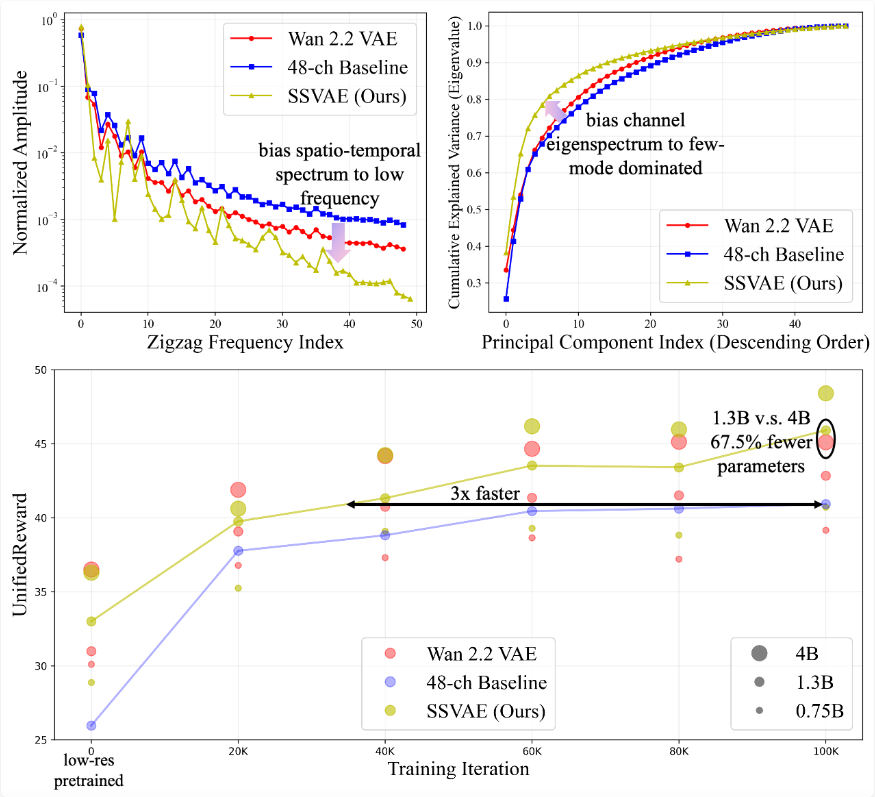
实验数据极具说服力:在使用SSVAE提取的Latent训练视频扩散模型时,在达到相同生成质量的前提下,收敛速度提升了整整3倍。
这意味着训练成本的大幅下降和迭代周期的显著缩短。
更令人惊叹的是,SSVAE仅需1.3B参数量的扩散模型,便能在性能上超越基于Wan 2.2 VAE的4B参数量模型。
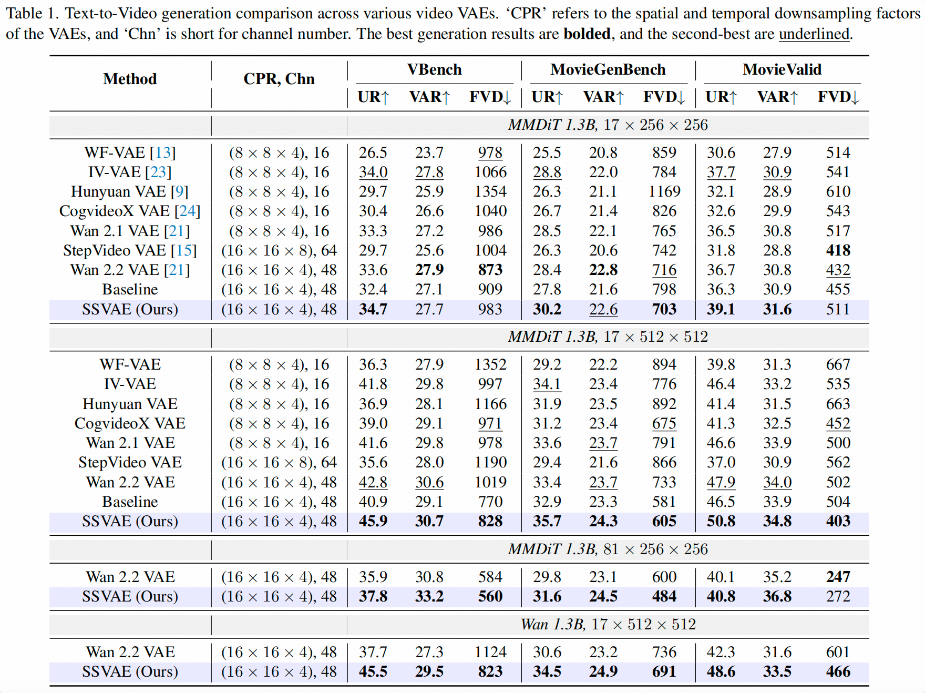
SSVAE通过谱正则化,在训练收敛速度和 Video Reward 上相对于 Baseline 的显著提升,超越Wan 2.2 VAE。
这四项技术的开源,为视频生成社区提供了从理论到工程的全方位弹药。
无论是追求极致画质的影视创作者,还是探索实时交互的产品开发者,亦或是致力于降低训练门槛的研究人员,都能从中找到可复现、可二次开发的坚实基石。
视频生成的未来,不在于盲目堆砌参数,而在于对物理规律与数学本质的深刻理解与精准建模。
参考资料:
https://teal024.github.io/SCAIL/
https://github.com/zai-org/SCAIL
https://z.ai/blog/realvideo
https://github.com/zai-org/RealVideo
https://criliasmiller.github.io/Kaleido_Project/
https://github.com/zai-org/Kaleido
https://zhazhan.github.io/ssvae.github.io/
https://github.com/zai-org/SSVAE
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









