



刚刚,美团开源6B参数图像模型LongCat-Image。

LongCat-Image 模型,以6B参数量的轻量化设计,在双语文本理解、图像逼真度以及复杂的指令编辑任务中,展示了令人印象深刻的性能。
在多项基准测试中超越更大规模模型,并提供了从推理到训练的全链路开源方案。
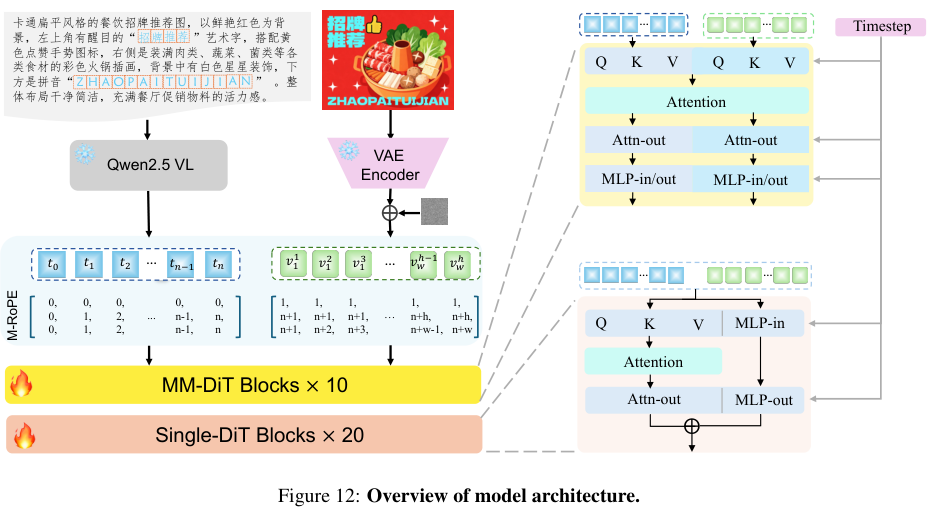
参数效率与架构设计
在开源社区中,常见的图像生成模型参数量往往在10B到80B之间,巨大的参数量虽然带来了丰富的语义理解能力,但也极大地推高了推理成本和部署门槛。
LongCat-Image选择了一条不同的路径,将参数量控制在6B。这一设计决策并非简单的减法,而是基于对模型架构的深度优化。
通过基准测试数据可以看到,LongCat-Image在GenEval(生成评估)和DPG(深度概率图)等指标上,以6B的体量与20B甚至80B的模型分庭抗礼。
在GenEval测试中,LongCat-Image取得了0.87的评分,这一成绩与20B参数的Qwen-Image(通义千问图像)持平,并优于12B参数的FLUX.1-dev(0.66)以及80B参数的HunyuanImage-3.0(混元图像3.0)。
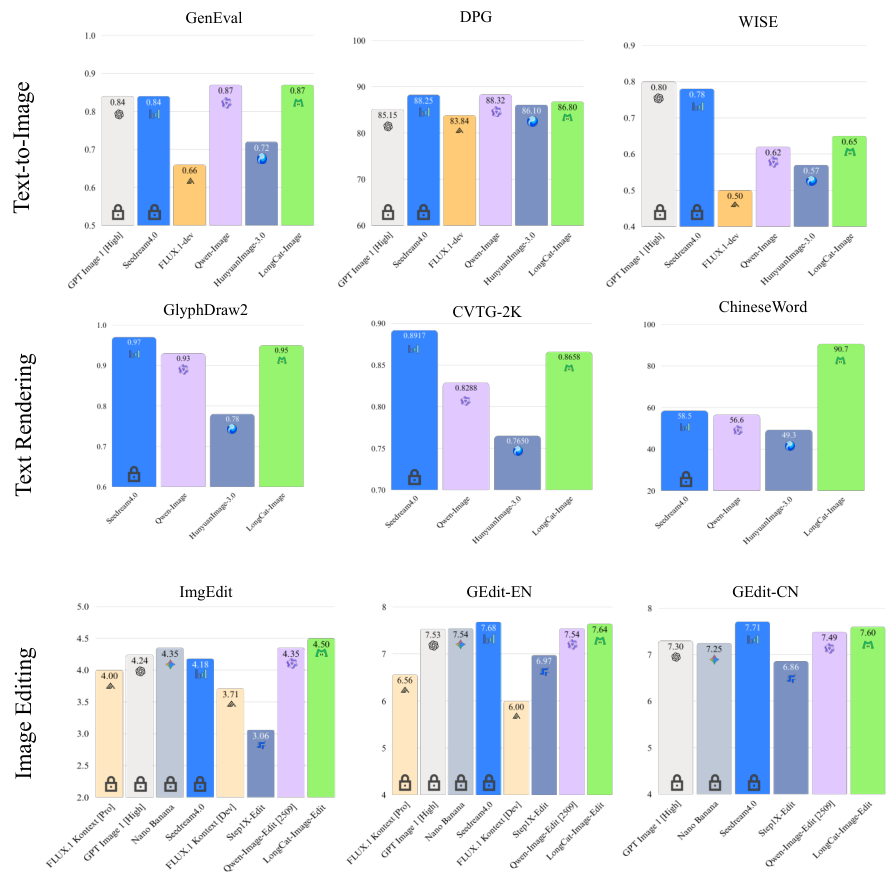
这种跨量级的性能表现,揭示了高效模型设计的巨大潜力:通过优化训练策略和数据质量,小模型完全可以在特定领域达到甚至超越大模型的表现。
6B参数模型可以在更广泛的消费级显卡上运行,降低了从实验室走向生产环境的硬件门槛。
对于开发者而言,这意味着更快的迭代速度和更低的运营成本。
攻克中文文本渲染的顽疾
现有的许多主流开源模型在处理英文文本渲染时表现尚可,但在面对结构复杂、笔画繁多的中文字符时,往往会出现乱码、笔画缺失或结构崩坏的现象。
这一直是中文图像生成领域的痛点,也是制约文生图技术在国内电商、广告设计等领域落地的主要障碍。
LongCat-Image在中文文本渲染方面取得了显著突破。


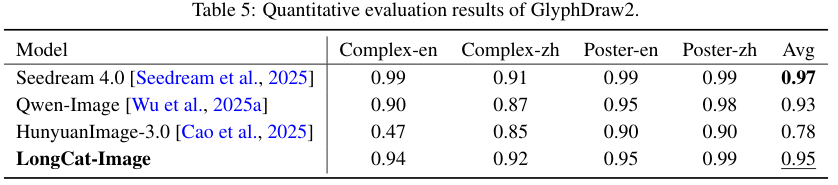
数据显示,在GlyphDraw2(字形绘制)测试中,该模型获得了0.95的高分,优于Qwen-Image的0.93和HunyuanImage-3.0的0.78。
在CVTG-2K(中文文本生成)测试中,其得分0.8658同样表现优异。
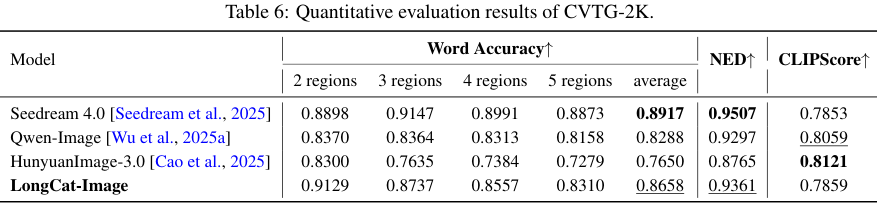
更值得关注的是其在Acc(准确率)指标上的表现,达到了78.59%,且CLIPScore(CLIP评分)高达90.7。
CLIPScore反映了生成图像与文本描述的语义一致性,90.7的高分说明模型不仅写对了字,还将字完美地融合进了图像的整体风格中,没有出现生硬的拼贴感。
这种能力得益于行业领先的中文词典覆盖率以及针对性的训练框架,使得模型能够像理解物体形状一样,精准地理解和构建中文字符的拓扑结构。
在主观的人类评估(MOS)中,LongCat-Image在Realism(真实感)上得分为3.60,超越了HunyuanImage-3.0(3.50)和Seedream 4.0(3.54)。
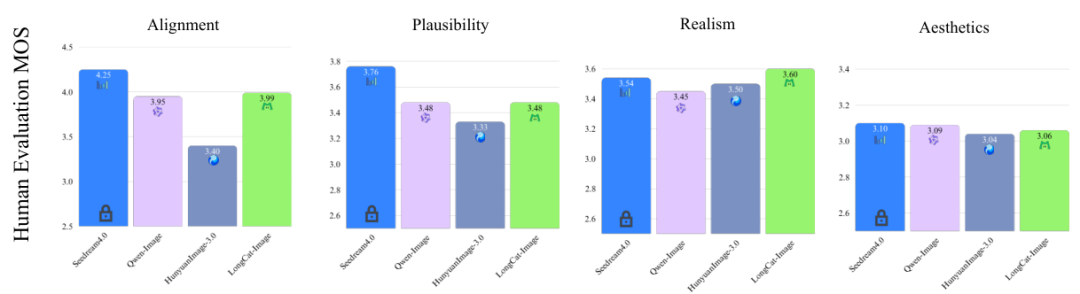
这表明模型在追求文字准确性的同时,并未牺牲图像的整体质感和摄影写实度。
精确可控的图像编辑能力
图像编辑的核心难点在于模型需要准确执行用户的编辑指令(如把猫换成狗),同时必须保持原图中背景、光影、风格等无关区域的绝对一致。
LongCat-Image-Edit是专门为此优化的编辑模型。

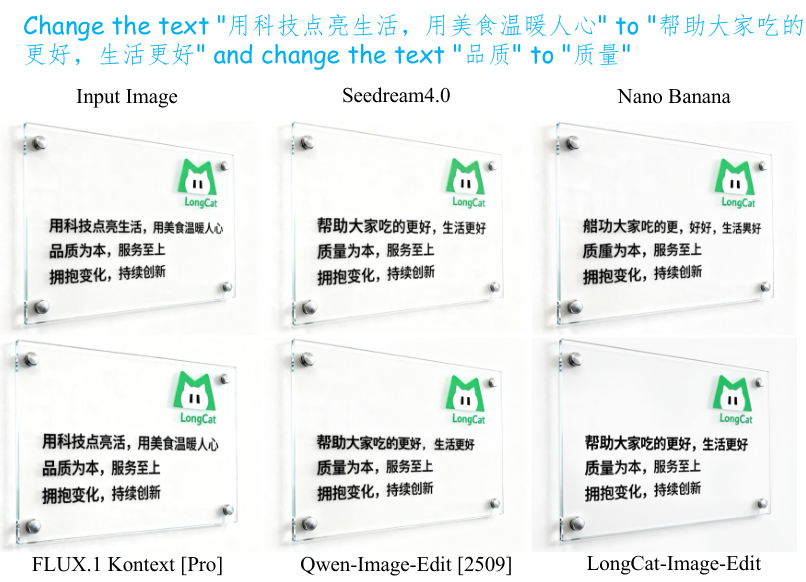
在衡量编辑能力的CEdit-Bench(中文编辑基准)和GEdit-Bench(通用编辑基准)测试中,该模型展现了卓越的视觉一致性。
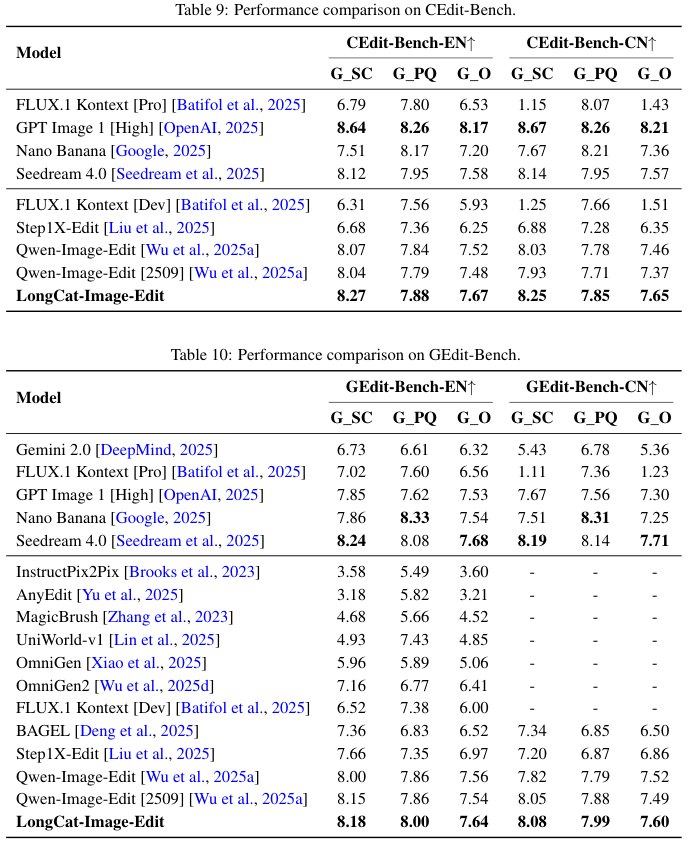
以GEdit-Bench-EN(英文通用编辑)为例,LongCat-Image-Edit在G_SC(结构一致性)得分为8.18,G_PQ(感知质量)得分为8.00。
对比来看,FLUX.1 Kontext [Pro]在同项测试中的G_SC仅为7.02。用户在修改图像局部时,不会意外破坏图像的其他部分。
在与闭源模型和竞品的直接对比中,LongCat-Image-Edit也展现了极强的竞争力。
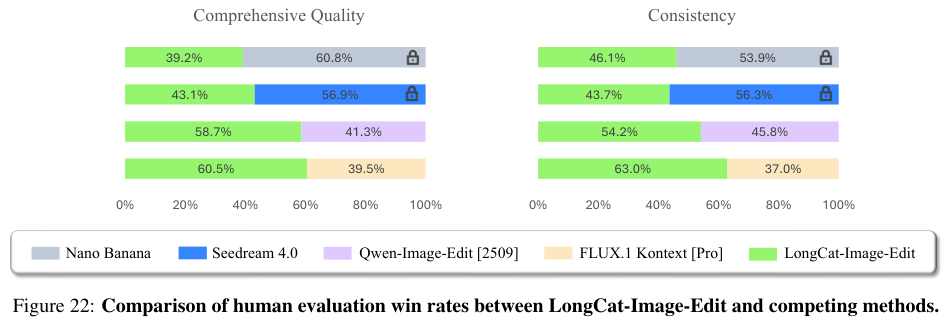
在人类评估的胜率对比中,LongCat-Image-Edit在综合质量上以60.5%对39.5%的比例战胜了FLUX.1 Kontext [Pro],在一致性上更是以63%对37%大幅领先。
全链路开源构建开发者生态
LongCat-Image团队提供了一个完整的开源生态系统。
整个发布包含了三个核心版本:
LongCat-Image 是最终发布版,经过充分训练和调优,适合用户开箱即用,直接进行高质量的图像推理。
LongCat-Image-Dev 是开发版,本质上是一个训练中期的检查点(Checkpoint)。对于研究人员和开发者来说,这个版本极具价值,因为它保留了更多的可塑性,非常适合用于Fine-tuning(微调)以适应特定的垂直领域需求。
LongCat-Image-Edit 是专门针对图像编辑任务优化的专用模型。
除了模型权重,团队还开源了完整的训练代码工具链。
支持SFT(监督微调)、LoRA(低秩适应)、DPO(直接偏好优化)以及专门的编辑训练。
对于希望在本地部署高性能图像模型,或需要进行深度定制开发的团队来说,LongCat-Image提供了一个极具吸引力的选项。
参考资料:
https://github.com/meituan-longcat/LongCat-Image
https://huggingface.co/meituan-longcat/LongCat-Image
https://huggingface.co/meituan-longcat/LongCat-Image
https://huggingface.co/meituan-longcat/LongCat-Image-Dev

















 1748
1748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









