 CUDA 13.1重大更新解析
CUDA 13.1重大更新解析




英伟达 CUDA Toolkit 13.1 发布,这是 20 年来最大的一次更新。

CUDA Toolkit 13.1 引入了 CUDA Tile 接口,这是自 CUDA 平台诞生以来在编程模型上最大的一次飞跃,它允许开发者以数据块为单位定义算法,将复杂的硬件映射工作交还给编译器。
2006 年 CUDA 诞生,将 GPU 从图形渲染专用的固定管线解放出来,变成了通用的并行计算设备。
近二十年来,开发者一直沿用 SIMT(单指令多线程)模型与硬件对话。
这种模式要求程序员指挥每一个独立的线程,手动管理它们在寄存器、共享内存和全局内存之间的数据搬运。
随着 GPU 架构日益复杂,为了追求极致性能,程序员不得不像微雕大师一样,精细控制成千上万个线程的同步与协作。
Blackwell 架构带来了更强大的张量核心和异步数据搬运能力,继续沿用旧有的线程微操模式,不仅开发效率低下,代码的可移植性也变得极差。
CUDA 13.1 不再要求开发者纠结于线程的 ID 计算和指令排布,而是引入了 Tile(图块)这一更高层级的抽象。
CUDA Tile 让算法回归数据本质
CUDA Tile 是一种全新的编程范式,它改变了开发者思考并行计算的方式。

在传统的 SIMT 模型中,开发者必须将数据分解为网格和线程块,编写在单个线程上运行的标量程序,依靠硬件的线程调度器来并行执行这些标量操作。
这在处理简单的向量加法时很有效,但在面对矩阵乘法、卷积等复杂线性代数运算时,为了通过 Tensor Core(张量核心)获得加速,程序员需要处理极度复杂的内存布局和数据对齐。
Tile 模型允许开发者直接声明和操作数据块。
你不再需要告诉第 0 号线程去读取内存地址 A,告诉第 1 号线程去读取内存地址 B。
你只需要告诉编译器:加载这个 16x16 的数据块。编译器和运行时系统会自动处理底层的脏活累活。
这种抽象带来的好处是巨大的。
它将算法描述与硬件实现解耦。开发者专注于数学逻辑,例如两个矩阵块相乘。
底层的编译器负责将这些块操作映射到具体的硬件指令上。
在 Blackwell 架构上,编译器会自动调用 TMA(张量内存加速器)来搬运数据,会自动调度 Tensor Core 来执行计算,会自动处理流水线并行。
这种解耦确保了代码的未来兼容性。
针对 Blackwell 编写的 Tile 代码,在未来的 GPU 架构上,只需重新编译,编译器就会根据新硬件的特性生成最优的指令序列。
开发者不再需要为了适应新一代显卡的 Shared Memory(共享内存)特性而重写内核代码。
CUDA Tile 目前主要针对 NVIDIA Blackwell 架构(计算能力 10.x 和 12.x)进行了支持,未来将扩展到更多硬件平台。
为了支撑这一体系,英伟达构建了两层接口。
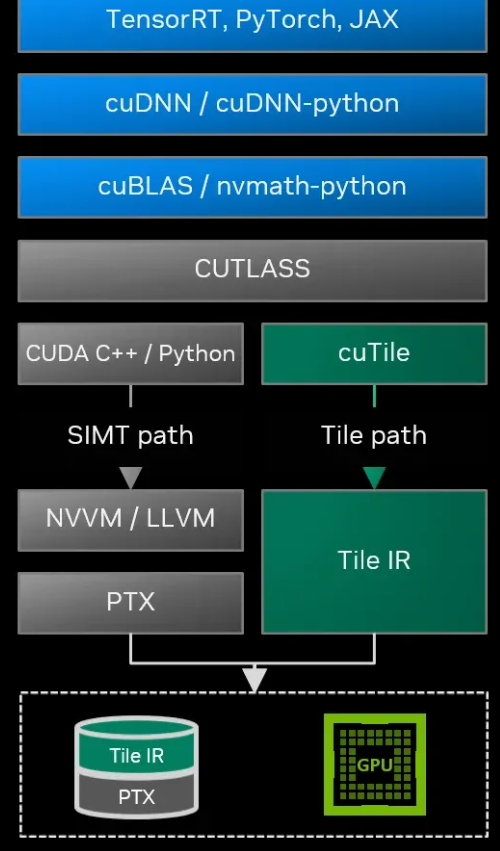
底层是 CUDA Tile IR(中间表示),这类似于 PTX 指令集,是一套专门用于描述图块操作的规范。
编译器开发者和框架构建者可以利用这套 IR 开发特定领域的语言或工具。
上层则是直接面向应用开发者的语言支持,此次更新重磅推出了 Python 接口。
Python 开发者获得原生高性能算力
长期以来,Python 是 AI 开发的通用语言,但在高性能计算内核的编写上,Python 始终是个二等公民。
开发者要么依赖 C++ 编写 CUDA 扩展,要么忍受解释器的性能损耗。
CUDA 13.1 推出的 cuTile Python 彻底改变了这一局面。
cuTile Python 是构建在 CUDA Tile IR 之上的 Python 库。
它允许开发者直接在 Python 中编写 GPU 内核,且不损失性能。
这不是传统的 Python 包装器,它是直接编译。
当你在 Python 中调用 cuda.tile 的函数时,这些代码会被即时编译成高效的机器码运行在 GPU 上。
以一个向量加法为例,在传统 CUDA C++ 中,你需要计算全局线程索引,判断边界,处理每个元素。
而在 cuTile Python 中,你只需要获取当前的 Block ID(块索引),使用 ct.load 将数据加载为 Tile,直接对 Tile 进行加法运算,最后用 ct.store 存回内存。

整个过程符合 Python 用户的直觉,代码清晰易读。
更重要的是,cuTile Python 能够直接利用 Tensor Core。
在涉及矩阵运算时,Python 代码中的加减乘除会被映射为 GPU 上专用的矩阵指令。
这使得数据科学家和算法工程师能够在不精通 C++ 和底层硬件架构的情况下,开发出能够榨干硬件性能的高效算力内核。
英伟达在官方博客中展示的代码表明,使用 cuTile 编写的程序在结构上比 SIMT 模型更加紧凑,逻辑更加纯粹。
编译器在幕后承担了繁重的工作。
它负责分析数据依赖,安排指令流水线,插入必要的同步屏障。
对于 Python 开发者而言,这就像是拥有了一位精通汇编语言的助手,你只管下达战略指令,战术执行由助手完美完成。
这种开发模式的转变,极大地降低了高性能 GPU 编程的门槛,让更多专注于算法本身的创新能够快速落地。
资源隔离与虚拟化技术的新突破
随着 GPU 算力的暴涨,单一任务往往无法填满整张显卡的算力。
多任务并发成为了数据中心的常态,但也带来了“吵闹邻居”的问题。
一个低优先级的任务可能会抢占关键资源,导致高优先级任务(如自动驾驶推理、高频交易)出现延迟抖动。
CUDA 13.1 引入了 Green Contexts(绿色上下文)来解决这一痛点。
Green Contexts 是一种在这一代 SDK 中新增的执行环境。
它允许开发者将一部分 GPU 的 SM(流式多处理器)在物理上隔离出来,专门分配给特定的上下文。比如,你可以将 80% 的 SM 划分为一个绿色上下文,专门用于处理核心业务,剩下的 20% 处理后台任务。
这种空间上的隔离(Spatial Sharing)比传统的时间分片(Time Slicing)更加彻底。它确保了关键任务在执行时,其计算资源不会被其他任务干扰,从而实现了极低且稳定的延迟。
对于 Blackwell 架构(B200/B300),英伟达进一步引入了 MLOPart(内存局部性优化分区)。
在传统的 MPS(多进程服务)中,多个进程共享 GPU 资源,但内存访问模式可能会相互干扰,导致缓存命中率下降。
MLOPart 技术能够将物理 GPU 虚拟化为多个逻辑分区,每个分区不仅拥有独立的算力,还通过优化内存局部性,使其表现得像一个独立的物理设备。
这在云原生和多租户环境中价值巨大。
服务提供商可以在一张强大的 Blackwell 显卡上安全地运行多个用户的 AI 模型,既保证了利用率,又保证了每个用户的服务质量(QoS)。
对于 Ampere 及之后的架构,CUDA 13.1 还支持了静态 SM 分区,通过启动 MPS 守护进程时的特定标志,可以强制实现确定性的资源分配,彻底杜绝了资源争抢带来的性能波动。
这些特性的加入,标志着 GPU 从单纯的计算加速卡,向着具备完善资源管理能力的计算平台演进。
开发者不再需要通过复杂的应用层逻辑来规避资源冲突,而是可以通过 Runtime API(运行时接口)直接向硬件申请专用的计算领地。
核心数学库的精度与确定性升级
数学库是 CUDA 生态的基石。
在 13.1 版本中,核心数学库针对 Blackwell 架构进行了深度优化,特别是在低精度计算和结果确定性方面取得了重要进展。
大模型训练和推理正在向 FP8 迁移。
CUDA 13.1 的 cuBLAS 库增强了对 FP8 的支持,特别是在分组通用矩阵乘法(Grouped GEMM)中。
这种计算模式在混合专家模型(MoE)中极为常见。
相比于过去使用多流(Multi-stream)技术来并发处理多个小矩阵乘法,新的 Grouped GEMM API 能够直接在设备端调度这些操作,消除了主机与设备之间的同步开销。
在 Blackwell 架构上,这种优化带来了数倍的性能提升。
除了速度,科学计算领域对结果的可复现性有着苛刻的要求。
由于浮点数加法不满足结合律,并行计算中累加顺序的微小差异会导致结果在最后几位小数上出现波动。这对于调试和验证模型正确性是极大的干扰。
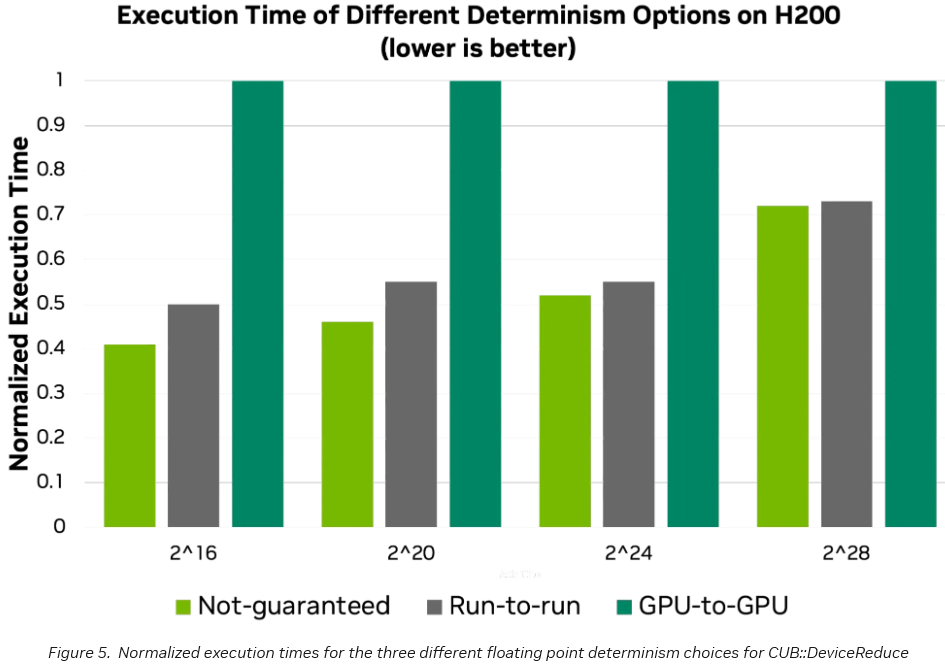
CCCL(CUDA C++ 核心库)3.1 版本引入了确定性执行模式。
开发者现在可以根据需求在三种模式间切换:不保证确定性以追求极致速度;保证同一程序多次运行结果一致;保证不同 GPU 之间结果一致。
特别是GPU-to-GPU的确定性模式,基于最新的算法研究,确保了在不同型号、不同数量的 GPU 上运行相同的规约(Reduction)操作,都能得到二进制级完全一致的结果。
在线性代数求解器 cuSOLVER 方面,针对 Blackwell 架构的高带宽特性,批处理特征值分解(Batched SYEV)性能得到了显著增强。
与 L40S 相比,在 RTX 6000 Ada 等新一代硬件上,处理大规模批次矩阵分解的速度提升了一倍以上。这直接造福于量子化学计算、流体动力学模拟等传统 HPC(高性能计算)领域。
工具链全面适配图块化编程
新的编程模型必须有配套的调试工具才能落地。
Nsight Compute 和 Compute Sanitizer 在 13.1 中都进行了针对性的升级。
Nsight Compute 2025.4 版本新增了对 Tile 编程的分析能力。
在性能分析报告中,出现了一个专门的Tile Statistics(图块统计)面板。开发者可以直观地看到 Tile 的尺寸、流水线的利用率以及数据搬运的吞吐量。
更重要的是,性能热点不再是映射到底层的汇编指令,而是可以直接映射回 cuTile Python 的源代码。这意味着开发者看着 Python 代码就能知道哪一行导致了性能瓶颈,无需去猜测编译器生成了什么指令。
Compute Sanitizer 是检查内存错误的神器,但过去它的运行速度极慢,往往比正常执行慢几十倍。
新版本引入了编译时插桩技术。
开发者在编译时加上 -fdevice-sanitize=memcheck 选项,编译器会将检查逻辑直接植入二进制代码中。
这种方式大幅降低了运行时开销,使得在全量测试集中开启内存检查成为可能。它还能检测到过去难以发现的相邻内存块越界访问等隐蔽错误。
CUDA Toolkit 13.1 是英伟达面对后摩尔定律时代计算挑战给出的系统性解答。
通过 CUDA Tile,它屏蔽了底层硬件的复杂度;通过 Green Contexts,它解决了资源管理的无序性;通过对 Python 的原生支持,它极大地扩张了高性能计算的开发者版图。
这套软件栈的更新,确保了 Blackwell 等新一代硬件的恐怖算力能够被算法工程师真正驾驭,而不是停留在理论参数上。
GPU 编程从微观调控正式迈入了宏观调度的新时代。
参考资料:
https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware
https://developer.nvidia.com/blog/nvidia-cuda-13-1-powers-next-gen-gpu-programming-with-nvidia-cuda-tile-and-performance-gains
https://developer.nvidia.com/blog/simplify-gpu-programming-with-nvidia-cuda-tile-in-python

















 2437
2437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









