



南京大学,腾讯优图实验室,新加坡国立大学发布了DiP框架(模型、代码也即将开源)。

DiP框架在不依赖VAE的情况下,以仅增加0.3%参数量的代价,将推理速度提升10倍并在ImageNet上取得1.79的FID分数,彻底解决了扩散模型在像素空间难以兼顾质量与效率的顽疾。

扩散模型(Diffusion Models)重塑了图像合成、视频生成和3D创作的格局,全面超越了生成对抗网络(GANs),但其背后的算力消耗惊人。
如何在不牺牲质量的前提下降低计算门槛,是所有研究者面临的头号难题。
潜在扩散模型(LDMs)选择了妥协。
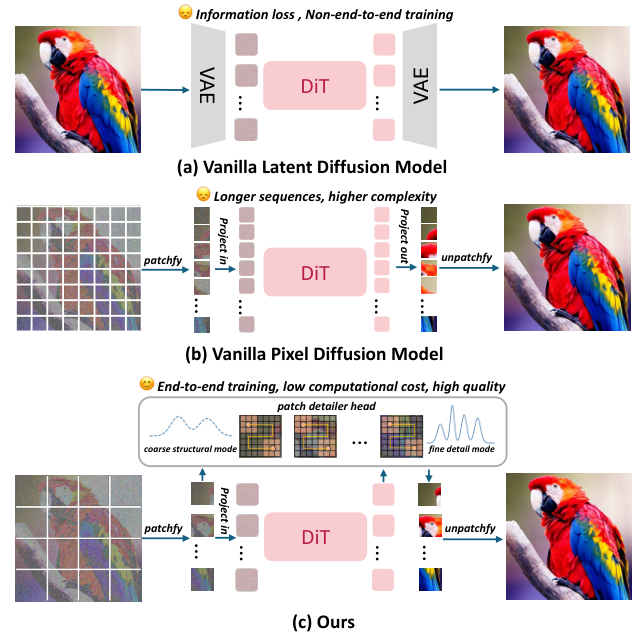
它们利用变分自编码器(VAE)将高分辨率图像压缩进紧凑的潜在空间。
这确实降低了去噪过程的计算复杂度。
代价是画质上限被锁死。
VAE的压缩过程不可避免地造成信息丢失。
非端到端的训练流程引入了难以消除的重建伪影。
直接在像素空间训练模型看似是完美的解决方案。
现有的像素空间模型,尤其是基于Transformer架构的模型,面临严重的可扩展性危机。
为了捕捉细腻的纹理,它们必须处理极小的图像块(Patches)。
随着图像分辨率提升,输入序列长度呈二次方爆炸式增长。
高分辨率图像的生成在计算上变得不可行。
这就是DiP(Diffusion in Pixel space)想要打破的僵局。
全局构建与局部精修
DiP的核心逻辑在于解耦。
图像生成不必在一个网络中完成所有维度的任务。
DiP将生成过程分为两个协同阶段:全局结构构建和局部细节恢复。
全局阶段交给扩散Transformer(DiT)主干网络。
研究团队做了一个关键设定:将DiT配置为处理大的图像块。
这个设定至关重要。
大图像块大幅减少了输入序列的长度。
这使得DiP在像素空间的计算开销直接降低到了与潜在空间模型(LDMs)相当的水平。
它不再需要VAE进行压缩。
它实现了完全的端到端训练。
DiT主干网络凭借自注意力机制,能够高效捕捉图像的宏观布局和语义内容。
问题随之而来。
由于处理的是大图像块,DiT输出的图像在细节上必然是模糊的。
它丢失了高频信息。
这就引出了第二阶段:局部细节精修。
DiP引入了一个轻量级的图像块细节头(Patch Detailer Head)。
这个模块并不独立存在,而是与DiT主干网络协同训练。
它接收DiT提取的上下文特征。
利用这些特征,细节头在每个大图像块内部进行精细化操作。
它利用强大的局部感受野,合成缺失的高频纹理和边缘信息。
这种设计让DiT专注于它擅长的全局一致性。
让细节头专注于它擅长的局部纹理还原。
二者各司其职,互为补充。
最终实现了在像素空间的高效、高质量生成。
引入局部归纳偏置更有效
DiT的设计初衷是为了模拟图像的长程依赖关系。
自注意力机制在处理块与块之间的关系时表现出色。
但它处理块内部信息的方式存在先天不足。
它将块内丰富的空间信息压缩成了一个单一的、扁平化的Token。
这种扁平化操作破坏了像素间的空间邻域关系。
模型虽然学会了哪里该画一只猫,哪里该画草地。
但它不知道猫毛的具体纹理该如何排列,草叶的边缘该如何锐化。
研究团队通过实验证实了这一点。

当在像素空间对单个高分辨率图像进行过拟合实验时,仅使用DiT的模型无法重建清晰的细节。
图像看起来是糊的。
这说明DiT缺乏处理局部细节所需的归纳偏置(Inductive Bias)。
DiP的设计原则就是显式地将被压缩掉的归纳偏置注回模型。
通过引入专门的细节头,模型重新获得了感知局部空间关系的能力。
在特征空间的可视化(t-SNE)中,DiP表现出了更紧密的类内聚类和更清晰的类间分离。
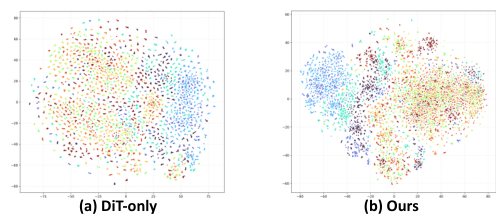
这意味着引入局部归纳偏置不仅提升了画质,还增强了模型的高级语义可分离性。
细节修复的最佳执行者
研究团队探索了多种细节头的架构设计。
标准多层感知机(MLP)表现最差。
因为它把像素视为无序集合,没有任何空间概念。
基于坐标的MLP引入了位置信息,但缺乏对纹理的先验知识。
块内注意力机制(Transformer)虽然强大,但计算太重。
最终胜出的是轻量级卷积U-Net。
它包含4个下采样块和4个上采样块。
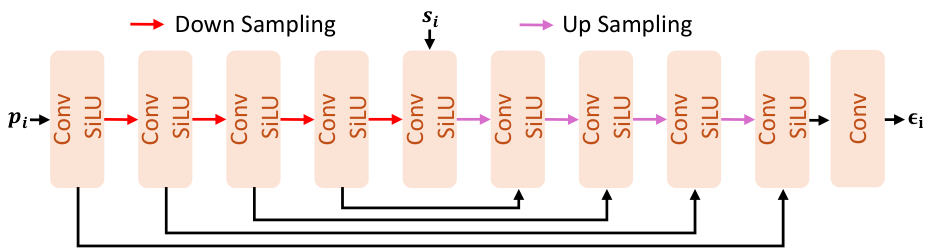
卷积网络天然具备局部性和平移等变性。
这正是修复局部纹理和边缘所急需的特质。
卷积U-Net能够高效捕捉多尺度空间特征,并保证局部连续性。
最重要的是,它非常轻。
引入这个模块仅增加了0.3%的总参数量。
这几乎是可以忽略不计的计算成本。
关于细节头放在哪里的问题,研究对比了“事后细化”(Post-hoc Refinement)、“中间注入”(Intermediate Injection)和“混合注入”(Hybrid Injection)三种策略。
结果表明,事后细化策略不仅实现了关注点的清晰分离(DiT 负责全局,细节头负责局部),而且性能最佳。
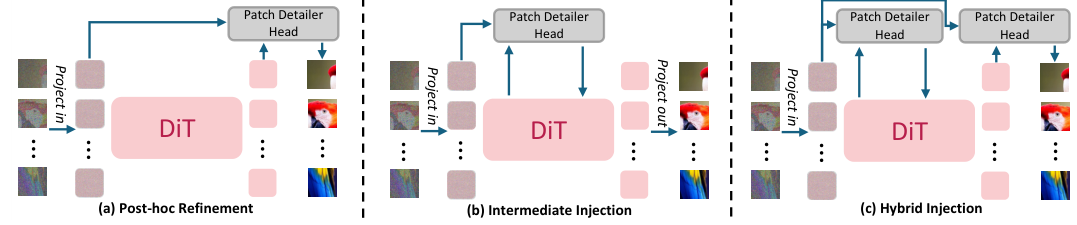
即只在DiT主干网络的末端接入细节头。
这种方式不仅性能最优,而且实现简单。
它不需要修改DiT的内部结构。
这意味着可以直接利用现有的预训练DiT模型进行微调。
实现了全局建模与局部精修的完美解耦。
DiP全方位超越现有方案
在ImageNet 256×256 分辨率的基准测试中,DiP交出了令人信服的答卷。
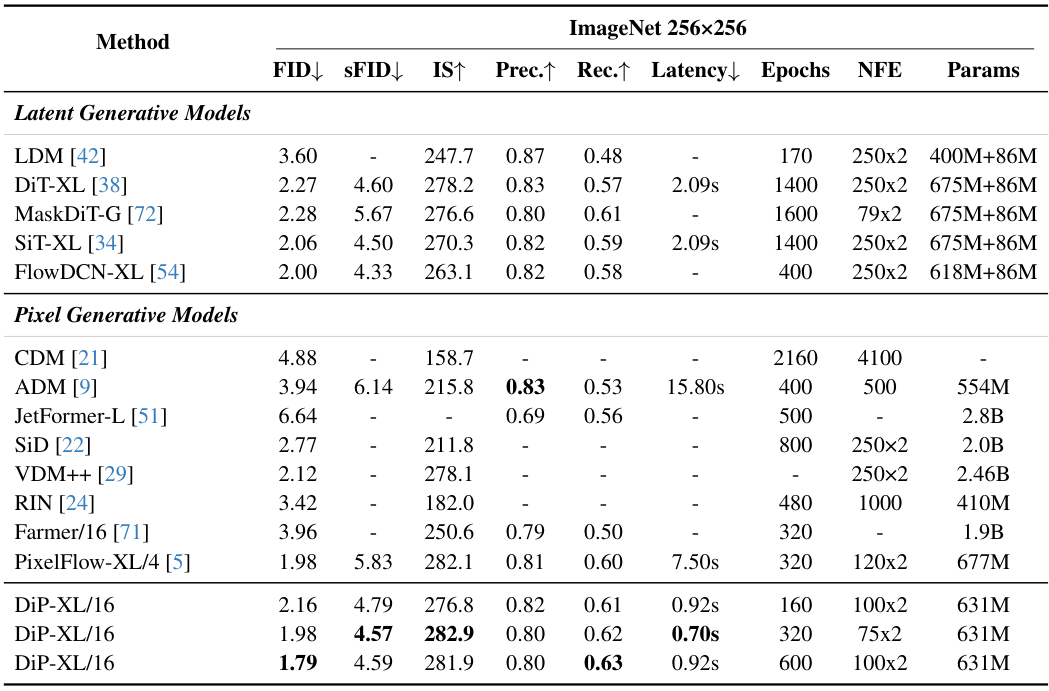
生成质量方面,DiP-XL/16取得了1.79的FID分数。
这个数字击败了作为基准的DiT-XL(2.27)。
也优于另一种主流架构SiT-XL(2.06)。
相比其他像素空间模型,优势更为明显。
ADM的FID是3.94。
VDM++是2.12。
此前表现最好的PixelFlow-XL/4是1.98。
DiP刷新了这一记录。
在推理速度上,DiP展现了像素空间模型罕见的高效。
单张图像推理仅需0.92秒。
DiT-XL需要2.09秒。
PixelFlow-XL更是长达7.50秒。
DiP比前者快了2倍,比后者快了8倍。
如果在75步推理设置下,DiP仅需0.70秒即可达到竞品的画质。
速度提升超过10倍。
参数量方面,DiP仅有631M。
相比之下,VDM++高达2.46B,Farmer也有1.9B。
DiP用极小的模型规模实现了更优的性能。
训练成本同样大幅降低。
DiP仅需320个训练周期就能达到最佳状态。
而DiT-XL和SiT-XL通常需要1400个周期。
这意味着训练时间缩短了75%以上。
高分辨率下的表现同样稳健。
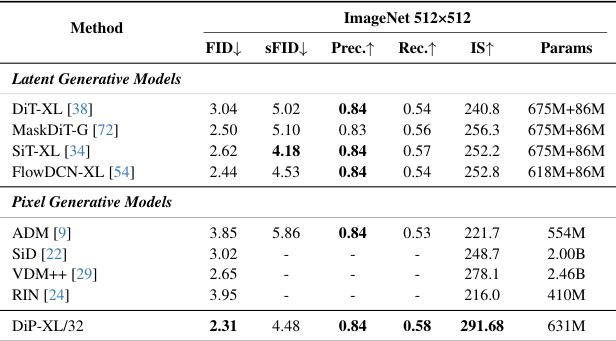
在ImageNet 512×512 分辨率下,DiP取得了2.31的FID分数。
优于DiT-XL(3.04)和SiT-XL(2.62)。
证明了该框架优异的可扩展性。
在像素空间扩散模型中,单纯堆砌DiT的层数是低效的。
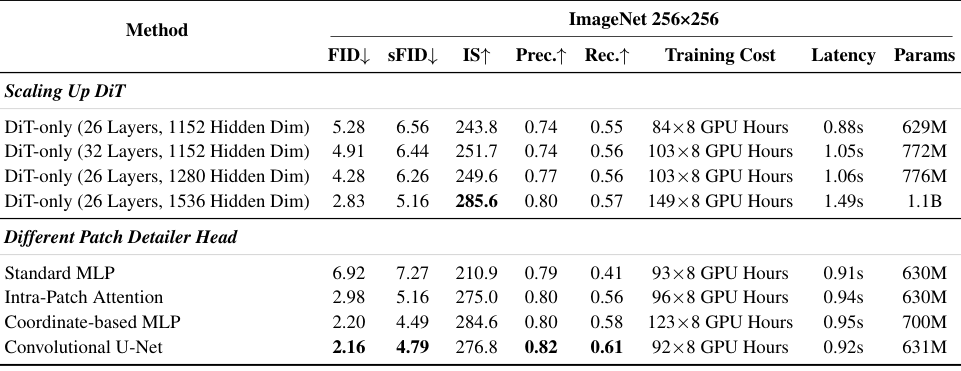
实验表明,将DiT深度从26层增加到32层,FID仅从5.28微降至4.91。
增加隐藏层维度虽然能提升画质,但带来了参数量和训练成本的暴涨。
参数量增加74.9%,训练成本增加77.4%。
这是一条性价比极低的路线。
相反,引入图像块细节头是四两拨千斤之举。
仅用0.3%的参数增量,就将FID从5.28大幅优化至2.16。
这证明了性能的瓶颈不在于网络的深度或宽度。
而在于是否引入了正确的归纳偏置。
卷积U-Net作为细节头,精准补齐了Transformer在局部细节处理上的短板。
这比盲目扩大模型规模要聪明得多。
DiP不仅是一个新的模型架构。
它提供了一种解决生成质量与效率矛盾的通用范式。
它证明了在像素空间进行高效、高质量的端到端生成是完全可行的。
VAE不再是必选项。
南京大学与腾讯优图的这项工作,让扩散模型在像素空间重获新生。
参考资料:
https://github.com/NJU-PCALab/DiP
https://arxiv.org/abs/2511.18822
END

















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









