



香港科技大学,Video Rebirth,浙江大学,北京交通大学开源了AnyTalker,提出音频驱动多人交互生成新范式。
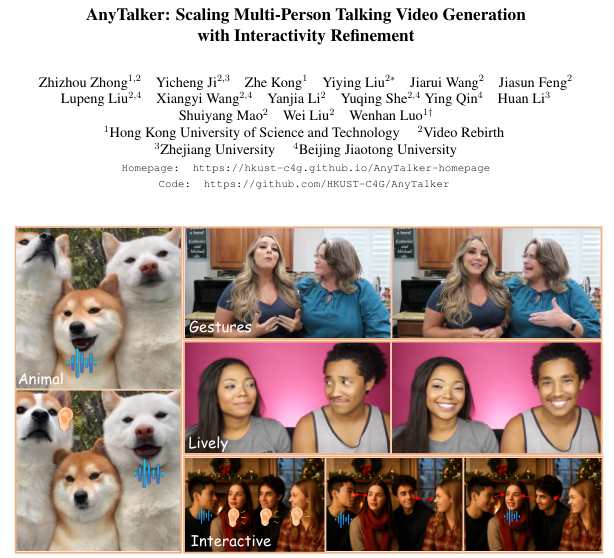
AnyTalker仅需极少量的多人对话数据即可生成具有自然眼神交流和即时反馈的多人对话视频,打破了以往模型对大规模昂贵数据集的依赖 。
,时长00:12
视频生成技术正在经历一场从单体到群体的演变。
在数字媒体、播客制作以及直播带货等领域,内容的核心往往不是单一角色的独白,而是多人之间丰富且微妙的互动 。
尽管基于扩散模型(Diffusion Transformer, DiT)的视频生成技术已经为单人说话视频提供了强大的基础架构,实现了逼真的口型同步,但现有的解决方案在面对多人场景时显得捉襟见肘 。
它们通常难以处理多音频流的复杂性,或者生成的角色之间缺乏自然的互动,往往呈现出各说各话的割裂感 。
AnyTalker 框架,正是为了解决这一核心痛点。
它通过创新的音频-人脸交叉注意力机制(Audio-Face Cross Attention, AFCA)和一种独特的两阶段训练策略,在极低的数据成本下实现了高质量、可扩展的多人视频生成 。
音频与人脸的动态耦合架构
AnyTalker 的核心构建在 Wan I2V 视频扩散模型之上,保留了其强大的图像生成能力,但为了适应多人场景,研究团队对注意力机制进行了手术刀式的改造 。
传统方法如 MultiTalk 试图通过标签旋转位置编码(L-ROPE)来区分不同的说话人,这种方法需要预先定义标签范围,限制了模型处理任意数量角色的能力 。
AnyTalker 选择了一条更具普适性的道路,设计了可扩展的音频-人脸交叉注意力模块(AFCA)。
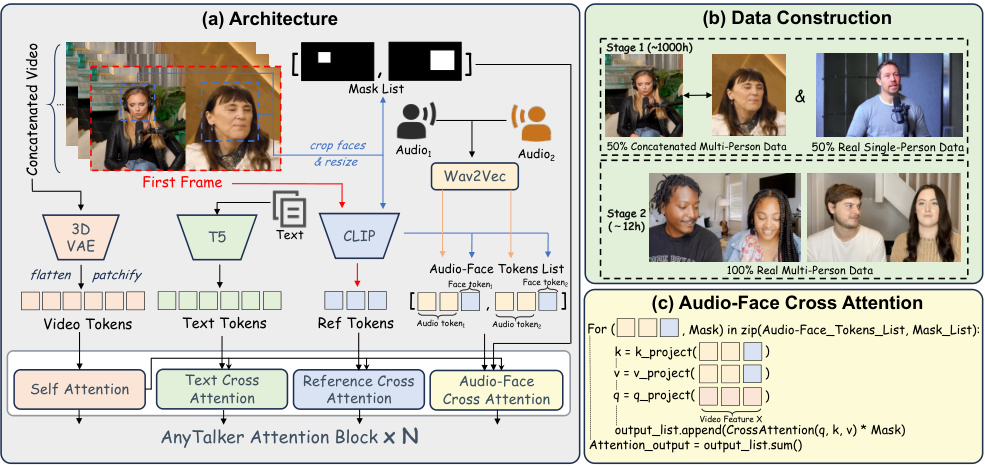
AFCA 模块的设计哲学是不预设身份数量。
该结构是一个递归调用的循环系统,根据输入的人脸-音频对的数量进行迭代处理 。
在输入端,模型首先对多模态特征进行标准化处理:视频特征经过 3D VAE(Variational Autoencoder,变分自编码器)压缩、分块并展平;文本特征由 T5 编码器生成;音频特征则通过 Wav2Vec2 模型提取 。
为了确保身份的一致性,模型还引入了参考注意力层,利用 CLIP 图像编码器从视频首帧提取参考特征 。
在注意力计算的核心环节,AFCA 并不孤立地处理音频或人脸,而是将两者进行深度的特征融合。
每一个参与计算的音频令牌(Token)都会与由 CLIP 编码的人脸令牌进行拼接 。
这种设计使得视频查询向量(Query)能够同时关注到音频内容和对应的身份信息。
具体的数学实现上,拼接后的特征被映射为键(Key)和值(Value),通过多头交叉注意力机制(MHCA)生成初步的注意力输出 。
为了实现时间维度上的精准同步,模型引入了时间注意力掩码(Temporal Attention Mask)。
第一个潜在帧被允许关注所有的音频令牌,以获取全局上下文,而后续的每一帧则被限制在一个包含四个音频令牌的局部时间窗口内 。
这种结构化的对齐机制确保了口型运动与语音节奏的严丝合缝。
AFCA 的另一个精妙之处在于其对输出的精准控制。
为了防止生成的面部运动超出合理范围,或者因大幅度运动导致画面崩坏,模型利用 InsightFace 库预先计算了一个全局面部掩码(Face Mask) 。
这个掩码覆盖了视频全过程中面部可能出现的最大区域,充当了一个严格的边界守卫。在注意力输出阶段,该掩码被重塑并展平,与注意力结果进行逐元素相乘 。
这一操作确保了扩散模型生成的每一处像素变化都严格限制在面部区域内,有效避免了伪影的产生。
最终,DiT 模块中的隐藏状态通过累加每个身份对应的 AFCA 输出进行更新 。
由于所有身份共享同一套 AFCA 参数,这种累加机制赋予了 AnyTalker 理论上无限的身份扩展能力,无论是双人对谈还是四人小组讨论,模型都能游刃有余地处理 。
巧用单人数据学习多人模式
构建多人对话生成模型的最大障碍在于数据的稀缺。
采集并标注高质量、多角度、包含自然交互的多人对话数据,成本极其高昂 。
现有的数据集大多局限于单人独白,难以支撑多人模型的训练需求 。
AnyTalker 提出了一种另辟蹊径的训练策略:利用海量的单人数据来教会模型如何进行多人对话。
整个训练过程被划分为两个阶段。
第一阶段的核心任务是让模型掌握基础的视听对应关系和多身份的空间定位能力。
研究团队使用了约 1000 小时的单人说话视频数据 。
为了模拟多人场景,训练批次(Batch)以 50% 的概率随机切换单人模式和双人模式 。
在双人模式下,模型并不依赖真实的双人视频,而是通过水平拼接的方式,将两个独立的单人视频并在同一画面中,同时拼接对应的音频流 。
这种看似简单的拼接策略蕴含着深刻的直觉。
它迫使模型学习将左声道的音频信号映射到左侧的人脸,将右声道的信号映射到右侧的人脸,从而在没有真实交互数据的情况下,确立了多流信号的空间对应关系 。
为了辅助模型理解这种合成场景,团队还预定义了一系列描述双人说话的通用文本提示词 。
这一阶段虽然没有涉及真实的眼神交流或互动,但它为模型打下了坚实的口型同步和身份控制基础。
实验表明,如果完全舍弃这一阶段的单人数据混合训练,模型生成的口型准确度将大幅下降,画面稳定性也会受到严重影响 。
第二阶段则是注入灵魂的过程。
模型使用经过严格筛选的真实多人数据进行微调。
这部分数据的体量非常小,仅有约 12 小时 。
为了确保数据质量,研究团队构建了一套严密的过滤管线:使用 InsightFace 确保画面中始终有两张人脸,利用音频分割技术(Audio Diarization)分离并确认说话人数量,通过光流法(Optical Flow)剔除运动过大的片段,并计算 Sync 得分以保证音画同步 。
这 12 小时的数据虽然少,却包含了极其珍贵的交互信息,如倾听时的点头、眼神的注视以及对同伴发言的非语言反馈。
令人惊讶的是,得益于 AFCA 架构的通用性设计,即便微调数据仅包含双人场景,模型却展现出了强大的泛化能力,能够自然地处理三人甚至四人以上的交互场景 。
模型不仅学会了怎么说,更学会了怎么听,这种从单人数据中提取共性规律,再用少量真实数据点亮交互技能的策略,极大地降低了训练门槛。
交互性的量化与评估
在多人视频生成的评估中,传统的单人指标如 FID(弗雷歇初始距离)或 Sync-C(唇形同步率)已经无法全面衡量视频的质量 。
这些指标关注的是图像的清晰度或嘴唇是否对上了声音,却忽略了多人对话中最本质的要素——互动。
如果一个角色在不说话时像雕塑一样静止,或者眼神空洞,那么生成的视频依然是失败的。
为了填补这一空白,AnyTalker 团队构建了名为 InteractiveEyes 的专用基准数据集 。
该数据集包含从互联网收集的真实双人对话视频,每段视频时长约 10 秒,经过精细的音频切分,确保包含了丰富的说话与倾听交替的片段 。
更重要的是,这些视频捕捉了真实的眼神交流和头部运动,为评估模型提供了高标准的参照 。
基于此数据集,团队提出了一项全新的度量指标:以眼部为中心的交互性(Interactivity) 。
眼神交流是人类对话中最本能的反应,也是判断视频是否自然的关键。
该指标深受手部关键点方差(HKV)的启发,通过追踪生成视频中眼部关键点的运动轨迹来量化互动的活跃度 。
具体的计算逻辑非常符合人类直觉。
Motion(运动)值计算的是面部对齐后眼部关键点在连续帧之间的位移和旋转幅度 。

为了避免被说话时的面部肌肉牵动所干扰,该指标专门聚焦于角色的倾听阶段(图示中的 L2 和 L3 时段) 。
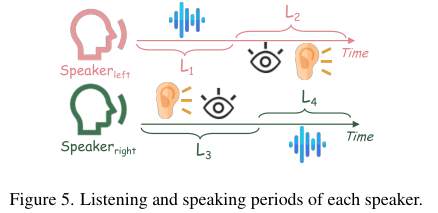
在这一阶段,如果角色表现出头部转动、挑眉或眼球移动等响应性行为,Motion 分数就会升高;反之,如果角色呆若木鸡,分数则会很低 。最终的 Interactivity 得分是倾听阶段平均运动强度的量化体现。
性能表现与技术突破
在严格的对比实验中,AnyTalker 展现出了超越现有最先进方法(SOTA)的性能。
研究使用了两个不同参数规模的模型版本:Wan2.1-1.3B-Inp 和 Wan2.1-I2V-14B 。
在单人生成的传统赛道上,尽管 AnyTalker 并非为此专门设计,但其表现依然强劲。
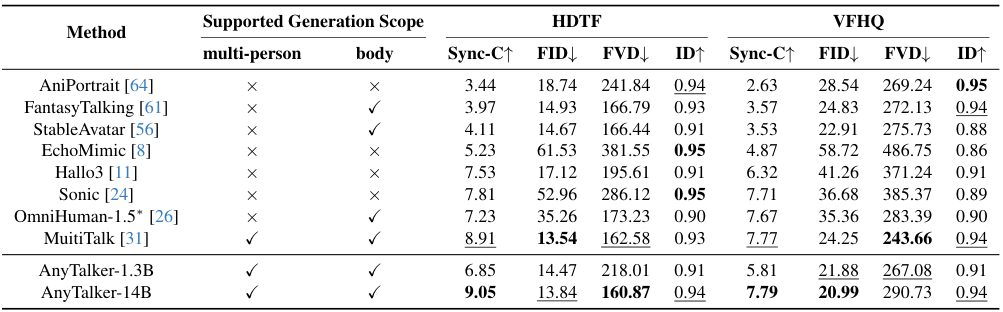
在 HDTF 和 VFHQ 等标准基准测试中,AnyTalker-1.3B 模型在口型同步(Sync-C)指标上取得了 6.85 的优异成绩,优于 Hallo3 的 7.53 和 Sonic 的 7.81(该指标越低越好),同时也超越了同等量级的 AniPortrait 和 EchoMimic 。
这证明了即使在处理最基础的单人说话任务时,其底层的视听对齐能力也是顶级的。
在多人生成的交互性比拼中,AnyTalker 的优势更为显著。
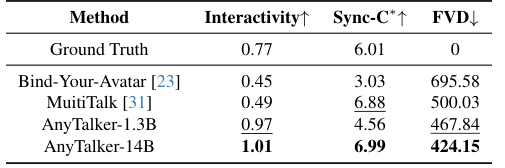
在 InteractiveEyes 基准测试中,AnyTalker-14B 的 Interactivity 得分高达 1.01,这一数据远超 Bind-Your-Avatar 的 0.45 和 MultiTalk 的 0.49 。
这意味着 AnyTalker 生成的视频中,角色不再是冷冰冰的读稿机器,而是能够对同伴的发言做出自然反应的鲜活个体。

定性分析也佐证了这一点,相比于其他方法生成的静态表情或微弱的眼部活动,AnyTalker 生成的角色拥有更丰富的眼神流转和头部姿态 。
消融实验进一步揭示了各个组件的不可或缺性。
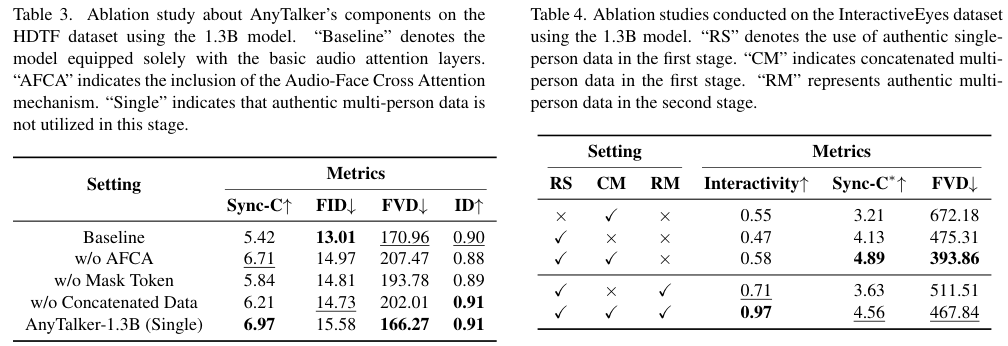
移除 AFCA 机制或掩码令牌都会导致口型同步率和画面质量的明显下滑 。
特别是第一阶段的拼接数据训练,对于模型掌握精确的口型运动至关重要;若跳过这一步直接使用真实多人数据,模型往往无法收敛到稳定的状态 。
虽然第二阶段的微调会导致口型同步率由于增加了复杂的面部表情而略有牺牲,但换来的是交互性得分从 0.71 到 0.97 的质的飞跃,这在提升用户观感方面是极其划算的权衡 。
AnyTalker 用极小的数据成本,通过合理的架构设计与训练策略,撬动了多人交互视频生成的大门。
参考资料:
https://hkust-c4g.github.io/AnyTalker-homepage/
https://arxiv.org/abs/2511.23475
https://github.com/HKUST-C4G/AnyTalker
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









