



AI打破了永远是初学者的魔咒,开始自我进化。
谷歌DeepMind团队联合伊利诺伊大学提出了Evo-Memory框架。

通过引入测试时自我进化机制,彻底改变了大型语言模型只能被动检索历史、无法像人类一样从经验中提取智慧的现状,让智能体在持续的任务流中实现了真正的终身学习。
AI演进历程中的记忆问题
当下的顶尖大模型已经展现出令人惊叹的能力,它们能编写复杂的代码,操控浏览器完成预定任务,甚至在奥林匹克级别的数学竞赛中通过推理得出正确答案。
模型虽然拥有极长的上下文窗口,可以记住用户在几分钟前说的每一句话,但这种记忆是静态且被动的。
当智能体在解决一个复杂问题时,它确实能回顾之前的对话内容,这被称为对话召回。
一旦任务结束,即便它刚刚经历了一场艰难的推理风暴并最终找到了解决问题的捷径,这些宝贵的经验也会随着会话的结束而烟消云散。
下一次遇到相似但不完全相同的难题时,它依然要从零开始,重新尝试,重新犯错,重新推理。
这就好比一个虽然拥有过目不忘能力的初学者,却永远无法成为经验丰富的专家,因为他只记得发生过什么,却从未从中提炼出解决问题的方法论。
DeepMind与伊利诺伊大学的研究团队构建了名为Evo-Memory的全新基准测试与框架,并提出了一种具备自我进化能力的智能体架构ReMem。
这一研究的核心价值在于,它将关注点从单纯的模型推理能力转移到了记忆的生命周期管理上,探讨了智能体如何在部署阶段,通过不断的行动、思考与反思,让记忆库像生物体一样自我新陈代谢,从而在连续变化的任务流中实现性能的螺旋式上升。
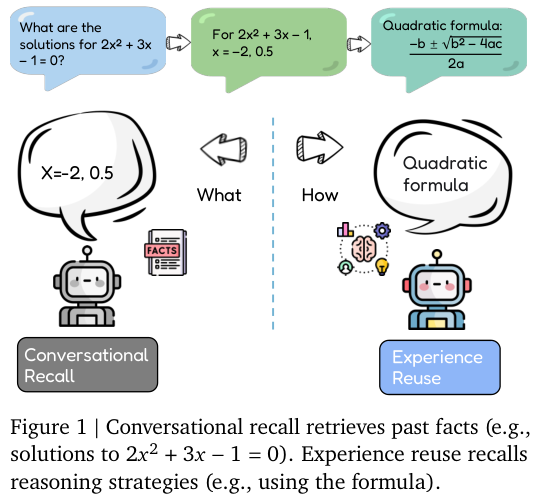
我们必须厘清对话召回与经验复用这两个截然不同的概念。
如图所示,左侧展示了目前大多数记忆系统的工作模式,即对话召回。
当用户询问之前的数学题答案时,模型只是简单地从历史记录中翻找出具体的数值。
这仅仅是信息的搬运,不涉及任何深度的认知加工。
右侧展示的则是经验复用,这是通向高阶智能的必经之路。
当智能体再次面对同类型的数学题时,它回忆起的不再是上一次的具体数字,而是解决此类问题通用的二次方程公式。
这种区别在具身智能场景中更为致命。
想象一个家庭服务机器人,由于缺乏经验复用能力,每次接到把杯子放入微波炉的指令时,它都要重新探索如何识别微波炉、如何打开门、如何放置物品。
即便它昨天刚刚成功地把番茄放进了微波炉,今天面对杯子时,它依然无法将昨天的动作序列抽象为一种通用的物体放置策略。
Evo-Memory所要解决的,正是让智能体从机械的复读机进化为能够举一反三的思考者。
Evo-Memory基准测试
这并非传统意义上的一次性考试,而是一场持久的拉力赛。
传统的评估方法通常使用静态数据集,给模型一堆独立的问题,统计其准确率。
Evo-Memory则将数据集重构为流式任务流,模拟了真实世界中任务连续发生的场景。
在这个框架下,智能体处理的是一个时间序列上的任务链。
在处理当前任务时,智能体被允许且被鼓励去检索、利用之前所有任务中积累的记忆。
这要求模型不仅要关注当下的解题,还要时刻维护一个不断演进的记忆库。
为了形式化这一过程,研究者将记忆增强型智能体定义为一个包含基础模型、记忆更新机制、检索模块和上下文构造机制的四元组。
这种数学化的定义将记忆不再视为一个外挂的硬盘,而是内化为智能体决策循环中不可或缺的一个变量。
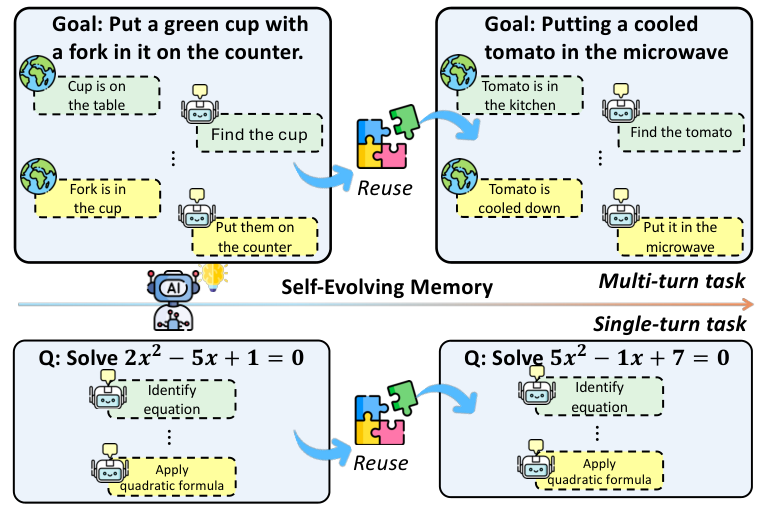
无论是多轮交互任务如机器人在厨房中寻找并加热番茄,还是单轮推理任务如求解代数方程,智能体都需要在任务流中不断搜索过去的信息,将其合成为当前的上下文,并在任务完成后更新记忆。
这种测试时进化(Test-time Evolution)的设定,模拟了人类在工作中边做边学、越做越熟练的过程,填补了现有评测体系中对动态适应性考核的空白。
在具体的实现路径上,论文提出了两种具有代表性的方案,分别是作为基线的ExpRAG和作为完全体的ReMem。
ExpRAG全称为经验检索与聚合,它的设计思路相对朴素,遵循了情境学习的基本原则。
每当完成一个任务,系统就将输入、模型的预测结果以及环境反馈打包成一条结构化的文本经验存入数据库。
当新任务到来时,系统通过计算相似度检索出最相关的几条历史经验,直接拼接在提示词中喂给模型。
ExpRAG虽然简单,但在处理具有高度重复性的任务时已经表现出了超越传统方法的潜力。
它证明了即便不进行复杂的模型微调,仅仅通过有效地利用历史数据,也能显著提升模型的表现。
它依然存在明显的局限性,因为它缺乏对记忆的深度加工。
所有的历史经验都被一视同仁地存储,无论其中包括了错误的尝试还是冗余的步骤,这种机械的堆砌在面对复杂多变的难题时往往显得力不从心。
ReMem架构带来的性能效率提升
为了克服ExpRAG的缺陷,研究团队推出了核心成果ReMem架构。
ReMem不再将记忆视为静态的文本库,而是将其视为一个需要精心耕耘的花园。
它引入了一个至关重要的操作环节——Refine(提炼)。
在传统的智能体框架中,如ReAct模式,智能体通常只具备思考(Think)和行动(Act)两种能力。
ReMem在此基础上增加了一个维度的操作,构成了一个思考、行动、记忆提炼的闭环。
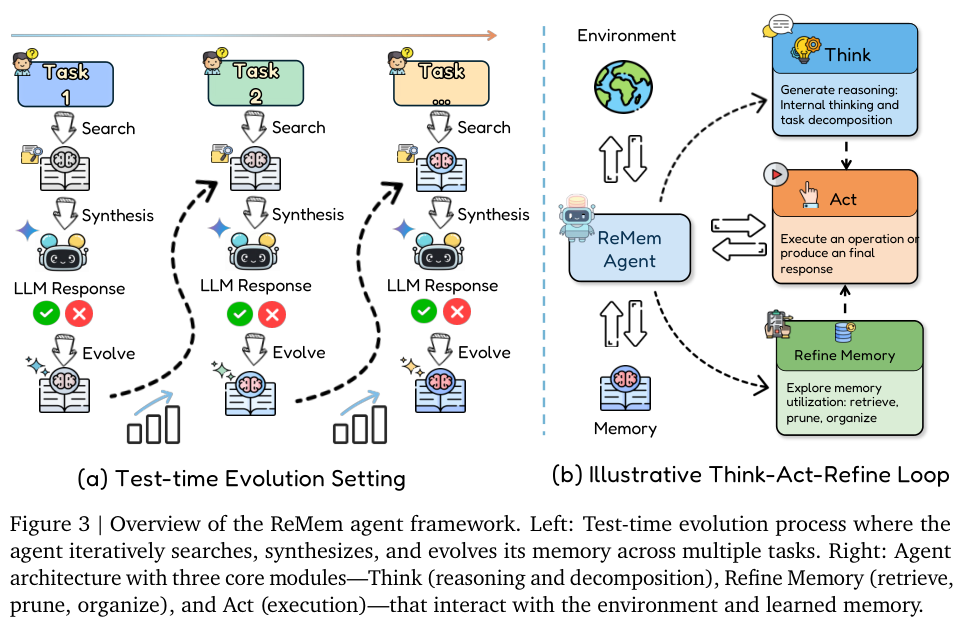
ReMem智能体在解决问题的每一步,都可以自主选择是继续推理、执行外部动作,还是停下来整理自己的记忆。
当它选择Refine操作时,它会回溯之前的推理轨迹,识别出哪些步骤是关键的转折点,哪些步骤是无效的试错,甚至会主动删除记忆库中过时或产生误导的信息。
这种元认知能力的引入,使得ReMem能够像人类专家一样,在实战中不断复盘,将具体的战术动作升华为通用的战略直觉。
为了全方位验证这一架构的有效性,Evo-Memory基准涵盖了十大极具挑战性的数据集。
这些数据集被精心划分为单轮推理与多轮交互两大阵营。
在单轮推理侧,包含了AIME系列这种高难度的数学奥赛题,测试模型在纯符号逻辑领域的迁移能力;同时也包含了GPQA-Diamond这种博士级别的科学问答,以及MMLU-Pro这种多学科知识库。
在工具使用方面,ToolBench测试了模型调用API解决实际问题的能力。
在多轮交互侧,测试环境更为复杂多变。
AlfWorld要求智能体在模拟家庭环境中理解自然语言指令并完成一系列家务;BabyAI通过网格世界测试智能体的导航与规划能力;ScienceWorld则模拟了科学实验的全过程,要求智能体具备极强的因果推理能力;PDDL任务则回归到了经典的规划问题。
这些环境不仅考验智商,更考验智能体在长序列操作中保持目标一致性并灵活应对环境反馈的能力。
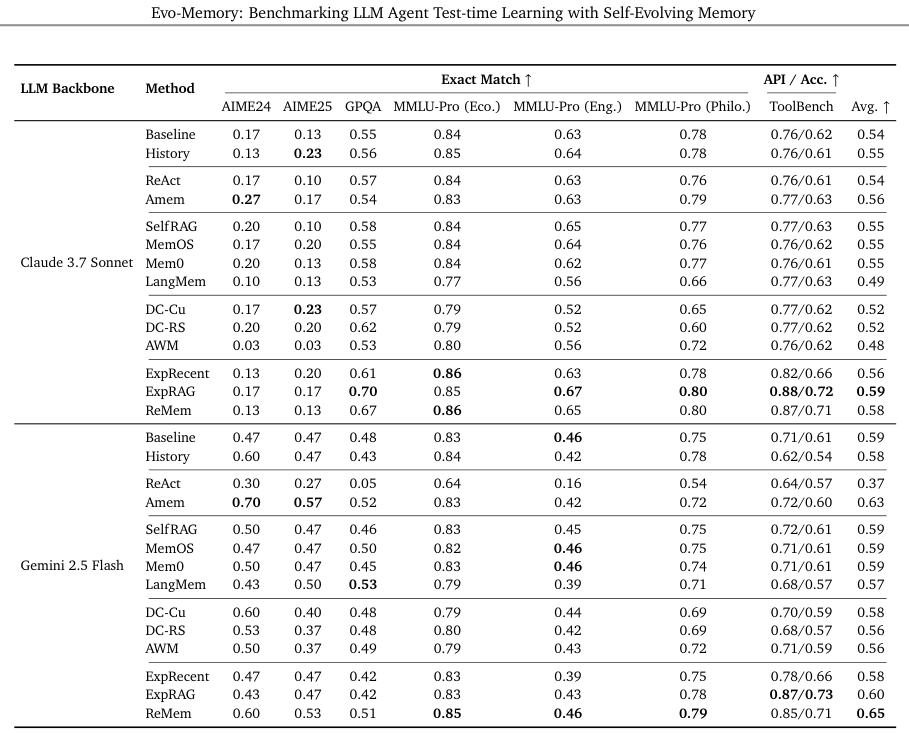
实验结果令人振奋,ReMem在绝大多数任务中都展现出了巨大优势。
在Gemini 2.5 Flash模型上,ReMem在单轮任务中的平均准确率达到了0.65,显著高于所有基线方法。
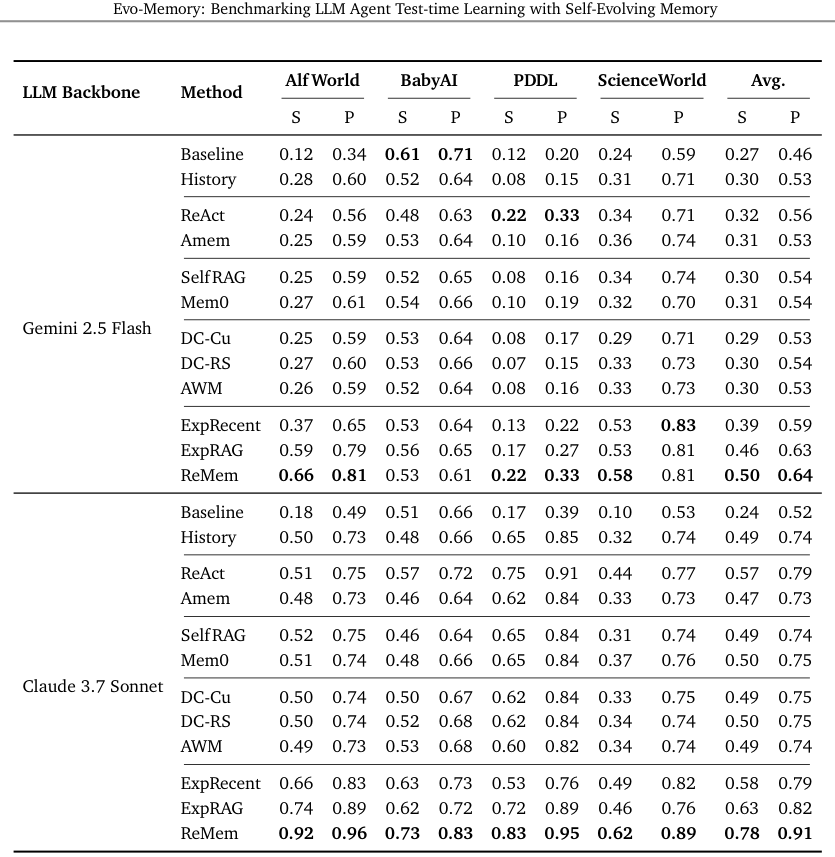
在多轮推理环境中,ReMem在Gemini-2.5和Claude Sonnet上都实现了强大而稳定的性能。
效率的提升是ReMem带来的另一个惊喜。
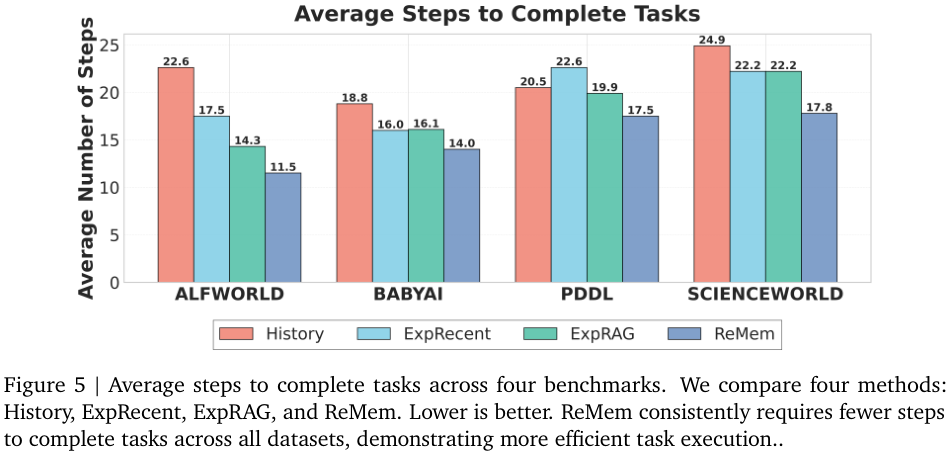
在AlfWorld任务中,基线方法平均需要22.6步才能完成一个任务,而ReMem将其压缩到了11.5步。
这一数据直观地反映了经验复用的价值。智能体不再像无头苍蝇一样在环境中乱撞,而是学会了走捷径。
它记住了上次在厨房找到刀具的位置,记住了切割苹果的正确动作顺序,从而大幅减少了无效的探索步骤。
无论是在AlfWorld、BabyAI还是PDDL环境中,ReMem(深蓝色柱状图)所需的平均步数都远低于仅依赖历史上下文的基线方法(红色柱状图)。
决定记忆的关键因素
深入分析实验数据,研究人员发现任务之间的相似度是决定记忆复用效果的关键因子。
在PDDL和AlfWorld这类结构化程度高、任务模式重复度高的环境中,ReMem的表现堪称完美。
这是因为这类任务背后的逻辑规则是恒定的,一旦掌握了核心模式,就可以无限复制到新任务中。
而在AIME或GPQA这种每道题目都独辟蹊径的测试中,虽然也有提升,但幅度相对较小。
这揭示了一个深刻的道理:经验的价值在于规律的重复,只有当历史具有某种韵律时,记忆才能发挥最大的效能。
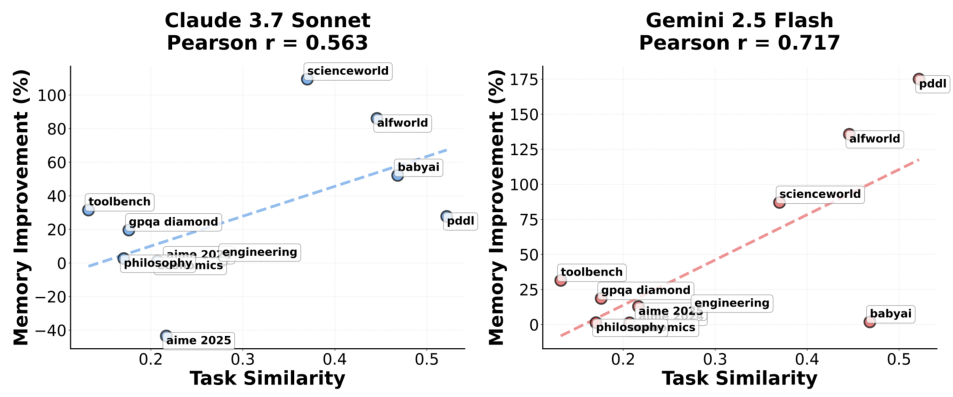
过散点图量化了这一结论。横轴代表数据集内部任务的相似度,纵轴代表ReMem相较于基线的性能提升幅度。
两者呈现出显著的正相关关系。PDDL和AlfWorld高居图表右上角,而涉及广泛常识和多变逻辑的GPQA则位于左下角。
这为未来记忆系统的设计指明了方向,即如何通过更好的表征学习,提高不同表面形式任务在潜在空间中的相似度匹配。
实验中还有一个极具启发性的发现,涉及任务序列的难度安排。
研究者设计了从易到难和从难到易两种任务序列。按照常理,循序渐进似乎更符合学习规律。
ReMem在先难后易的设置下表现出了惊人的稳健性。
当面对高难度任务的挑战时,ReMem被迫进行了更深层次的思考和更激进的记忆提炼,生成了更为抽象和通用的策略。
当这些在困难模式下练就的绝招被应用到随后的简单任务时,简直就是降维打击。相比之下,基线方法在遇到任务难度突增时,性能往往会发生断崖式下跌。
对于失败经验的处理,ReMem也展现出了独到的智慧。
如果简单粗暴地将所有失败的尝试都存入记忆库,这些错误的路径往往会成为干扰后续检索的噪声,导致模型重蹈覆辙。
ReMem利用其特有的Refine机制,能够主动分析失败的原因。
它不是简单地记录“我做错了”,而是将错误转化为一种约束条件,告诉自己在未来的类似情境中“不该做什么”。
这种对负面反馈的深度消化和利用,使得ReMem即便在充满挫折的探索初期,也能保持进化的稳定性。
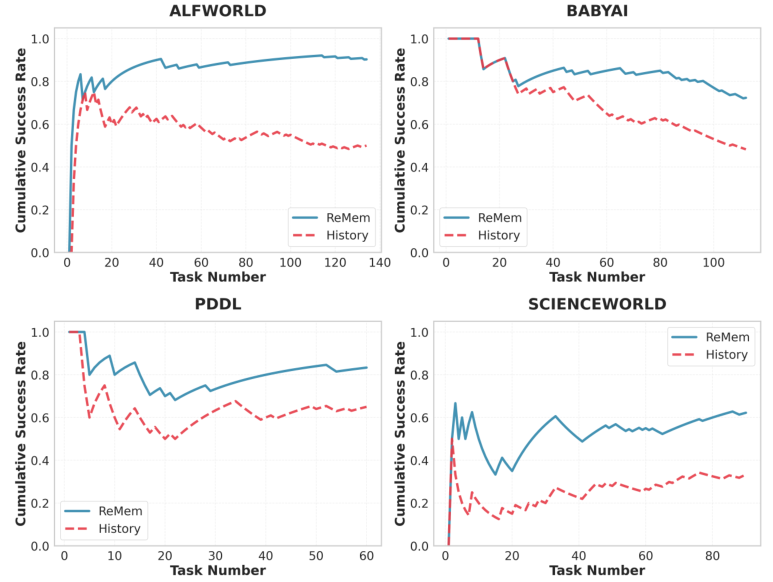
在四个交互式数据集中,随着任务数量的增加,智能体累积成功率的变化趋势。蓝色的实线代表ReMem,红色的虚线代表基线。
可以清晰地看到,ReMem的曲线始终压制着基线,并且随着时间的推移,两者之间的差距在逐渐拉大。
这说明ReMem的学习是累积性的,它像滚雪球一样,随着见识的增长而变得越来越强大。在ScienceWorld中,这种趋势尤为明显,曲线的震荡上行反映了智能体在适应复杂科学实验逻辑过程中的顽强进化。
ReMem告诉我们,智能的本质可能不仅仅在于算力的堆叠或参数的规模,而在于如何管理和利用由于交互产生的经验流。
未来的大模型也许不需要每次发布都进行昂贵的重新训练,而是可以通过在测试时的持续自我进化,适应千变万化的应用场景。
这种轻量级但高效的进化范式,为将大模型部署到资源受限的终端设备上提供了理论支持。
这一研究也为我们重新审视“记忆”在人工智能中的地位提供了新的视角。
过去的记忆模块往往被设计为只读的参考资料,而ReMem证明了记忆应该是可读写、可编辑、可优化的动态资产。
智能体需要像整理文件柜一样,定期清理陈旧的记忆,归纳零散的片段,构建结构化的知识图谱。
这种主动的记忆管理能力,或许是通向通用人工智能(AGI)拼图上缺失的那关键一角。
参考资料:
https://arxiv.org/abs/2511.20857
END

















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









