



新加坡国立大学,香港理工大学,上海交通大学的研究团队推出了ViBT。

ViBT通过建立源数据与目标数据间的直接随机路径,配合方差稳定的速度匹配与校正采样,解决了传统扩散模型效率低与训练不稳定的难题。
模型在图像、视频风格化,图像编辑,视频插帧等任务上表现非常出色。
生成式AI的发展历程是一部不断寻找更优路径的历史。
从对抗生成网络到变分自编码器,再到如今统治领域的扩散模型,我们见证了生成质量的飞跃。
主流扩散模型的核心逻辑是噪声转视觉。
模型必须先将数据彻底破坏成毫无意义的高斯噪声,再像考古学家修复文物一样,一步步逆向还原出目标图像。
这种范式在从零创造新图像时非常有效,因为它确实是从虚无中诞生有形。
当我们面对图像编辑、视频风格化或帧插值这类任务时,事情变得有些荒谬。
输入数据本身已经包含了大量结构信息,比如物体的轮廓、场景的布局或视频的动作。
强行将这些清晰的画面退化为纯噪声再重新生成,就像为了给房子刷个新颜色的墙漆,先把整栋房子拆成砖块再重新盖起来。这既不直观,也极大地浪费了计算资源。
视觉转视觉的新范式
我们不需要绕道噪声的远路,而是直接在源图像和目标图像之间架起一座桥梁。
布朗桥模型正是为此而生。
它构建了一个连接源分布与目标分布的随机过程,让数据在两个有意义的状态间流转。
ViBT是首个将布朗桥模型扩展到200亿参数规模的大型尝试。
它不仅验证了这条路径的可行性,更通过精妙的数学修正,解决了大规模训练中棘手的数值稳定性问题。
直接连接两个数据点的想法听起来简单,实现起来却充满了数学陷阱。
概率路径建模试图定义一个连续的时间过程,把概率质量从起点搬运到终点。
最简单的搬运方式是直线。
整流流模型就是这么做的,它画一条直线连接起点和终点,速度恒定。
数据像坐上了一辆匀速列车,从源头直达目的地。这种确定性的路径虽然简洁,但在处理复杂的多模态分布变换时,往往显得僵硬。
为了捕捉数据间更微妙的相关性,我们需要引入随机性。
ViBT选择了布朗桥。在这个框架下,中间状态不再是死板的线性插值,而是遵循一个特定的高斯分布。
想象一座桥,两端固定在源图像和目标图像上。桥身并非紧绷的钢索,而是像一条在风中摆动的绳索。在桥的中间点,摆动的幅度最大,也就是方差最大。随着我们接近任何一端,摆动幅度逐渐减小,直到在端点处归零。
这种随机性为模型提供了探索空间,但也带来了严重的训练困难。
传统的扩散模型训练依赖于速度匹配。我们需要训练一个神经网络来预测数据流动的速度。
在布朗桥的设定中,当时间趋近于终点,也就是接近目标图像时,理论上的目标速度会变得极度不稳定。
这种发散是灾难性的。在训练过程中,接近终点的样本会产生巨大的损失值。模型会把绝大部分注意力都被迫集中在最后那一点点时间上,试图去拟合一个近乎爆炸的数值,而忽略了整个生成过程的中间阶段。
有些研究试图用位移匹配来替代速度匹配。
既然速度算不准,那就直接预测位置。位移匹配虽然避免了数值爆炸,却走向了另一个极端。随着时间接近终点,位移的量级会迅速衰减。
模型在后期的训练信号微乎其微,导致它学不会如何精准地完成最后的收尾工作。
ViBT的破局之道在于引入了一个归一化因子。
研究人员并没有试图强行压制速度的爆炸,而是重新定义了观察的标尺。
他们提出了方差稳定的速度匹配目标函数。通过计算速度目标的均方根幅度,他们设计了一个随时间动态变化的归一化系数。
这个系数在时间早期保持稳定,在时间趋近终点时,它与速度目标同比例增长。当我们将预测误差除以这个系数时,奇迹发生了。原本发散的损失函数被拉回了一个平稳的区间。
无论是在生成的开始、中间还是结尾,模型都能接收到强度一致的训练信号。
这种数学上的再平衡,消除了数值不稳定性,让神经网络能够在全时间段内从容地学习数据变换的轨迹。
解决了怎么练的问题,还得解决怎么用的问题。
在推理阶段,我们需要把连续的时间切分成离散的步长,一步步推导最终结果。
通常使用的欧拉-丸山采样法有一个默认假设:局部的噪声方差是恒定的。这在普通的扩散模型里没问题。但在布朗桥里,方差是随着时间变化的。
特别是当我们在桥上快走到头时,理论上方差应该迅速收缩为零。如果这时候还套用标准的采样公式,每一步注入的随机噪声就会显得过大。
这就像在做精密手术的最后关头,手本来应该越来越稳,采样器却还在按照刚开始的大动作幅度在抖动。结果就是生成的图像在最后阶段被不必要的噪声干扰,细节变得模糊,甚至结构发生偏离。
ViBT引入了方差校正采样。通过引入一个缩放因子,强制调整每一步注入的噪声大小。这个修正项确保了随着时间推移,注入的随机性能够平滑地衰减。
这种对离散采样动力学的精细校准,保证了推理过程严格遵循布朗桥的理论结构。最终生成的图像不仅保留了随机过程带来的多样性,更拥有了确定性路径般的清晰度与准确性。
ViBT实现大规模训练
有了坚实的理论基础,ViBT开始向大规模参数发起挑战。
在图像领域,ViBT基于200亿参数的Qwen-Image-Editing模型进行初始化。为了在庞大的参数量下保持训练的高效,团队采用了LoRA技术,以128的秩进行微调。
在视频领域,基础模型选用了13亿参数的Wan 2.1。这一次,团队选择了全参数微调,以释放模型在时序建模上的全部潜力。
实验涵盖了指令级图像编辑、视频风格化以及深度图转视频等多个高难度任务。

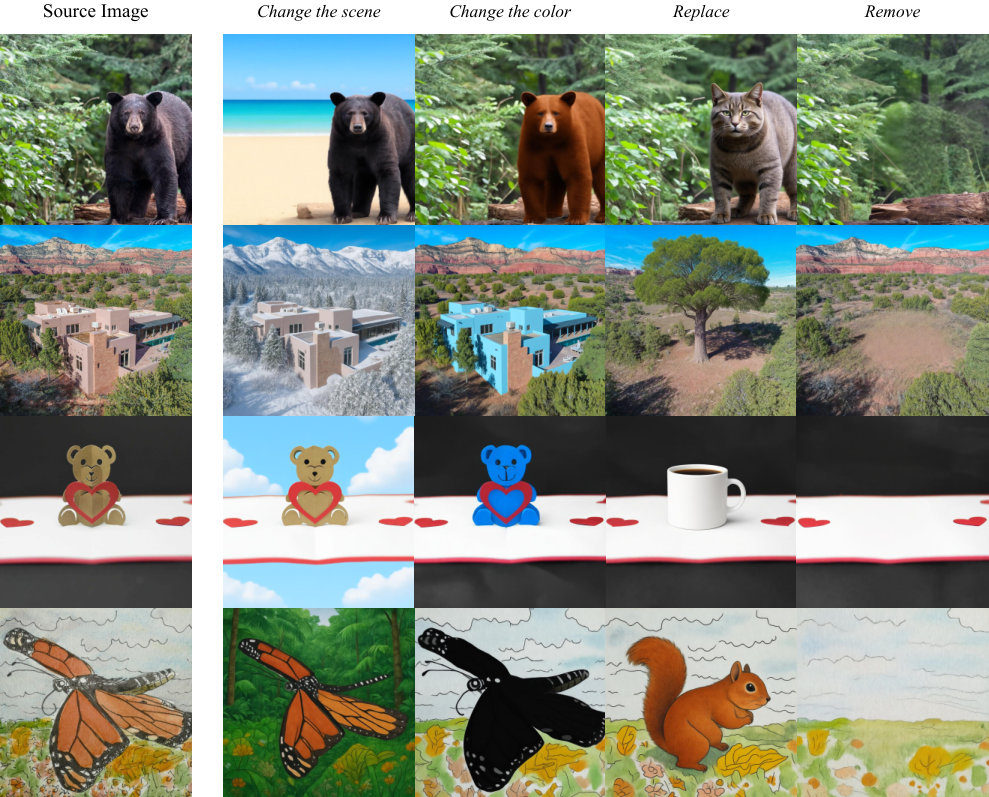
在指令级图像编辑任务中,ViBT展现了极高的指令遵循能力。当用户输入将背景改为雪原景观时,模型能够精准地识别并替换背景区域,同时完美保留前景物体的每一个像素细节。
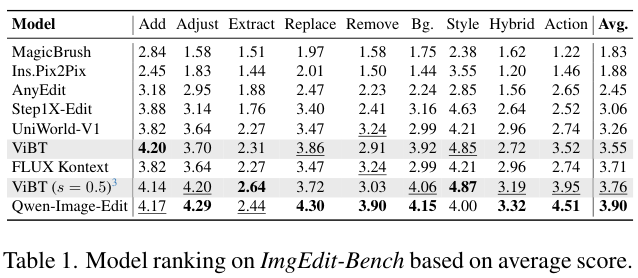
在ImgEdit-Bench(图像编辑基准)测试中,ViBT在对象添加和风格转换任务上分别拿到了4.20和4.87的高分,显著优于Magic Brush(魔法笔刷)等基线模型。
这种对非目标区域的极致保护,正是直接桥接数据分布带来的红利。
视频风格化任务不仅要求画面美观,更要求时间连贯。ViBT在处理让视频像梵高的画作这类指令时,生成的每一帧都充满了浓郁的艺术风格,同时物体运动的流畅度与原视频保持高度一致。
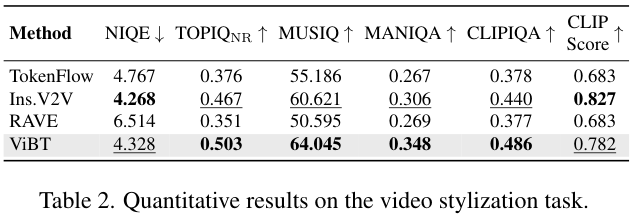
定量数据显示,ViBT在NIQE(自然图像质量评估器)指标上达到了4.328,优于TokenFlow(令牌流)等竞争对手。这说明其生成的视频在感知质量上更符合人类的审美标准。

最具挑战性的莫过于从深度图生成视频。这是一个典型的跨模态翻译问题。模型需要仅凭灰度的深度信息,臆想出多彩且合理的现实世界,并赋予其动态。
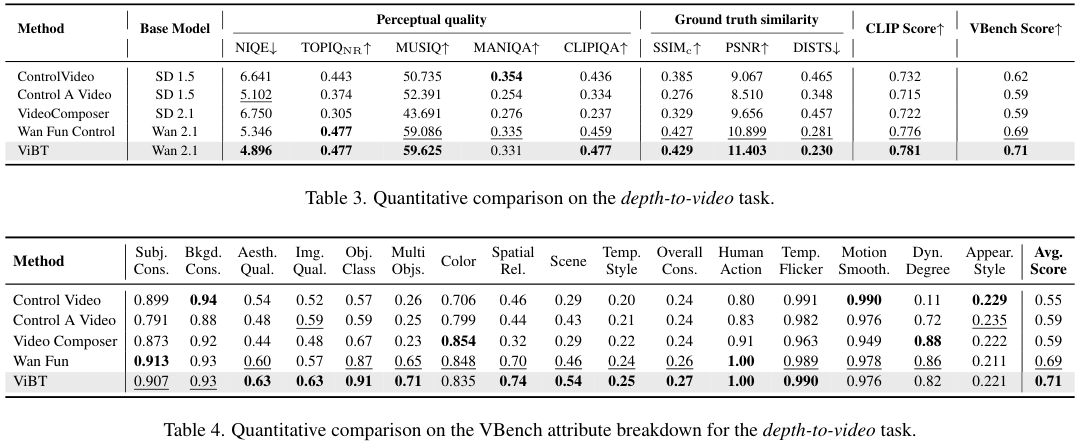
在VBench(视频基准)测试中,ViBT在对象一致性、背景一致性和整体一致性上均取得了最高分,其中整体一致性更是拿到了满分1.00。它生成的鸟类羽毛纹理清晰,姿态与深度图完全贴合,没有出现常见的结构扭曲。
ViBT的效率提升
传统的条件扩散变换器(Conditional DiT)在处理条件生成时,往往需要引入额外的编码器或在注意力层中插入大量的条件Token。
这些额外的组件不仅增加了模型的复杂度,更拖累了推理速度。
ViBT直接在潜在空间操作,不需要额外的条件Token。
这使得它在处理相同分辨率的输入时,计算量大幅下降。
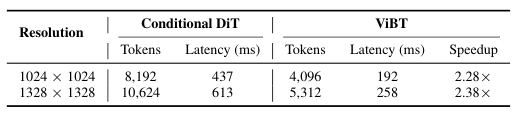
在1024x1024分辨率的图像生成任务中,ViBT的单次前向推理仅需192毫秒,而同类的条件扩散变换器需要437毫秒,速度提升了2.28倍。
到了视频生成领域,这种优势被进一步放大。
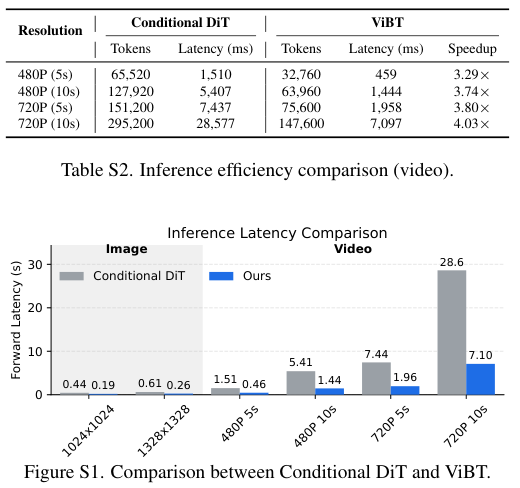
生成一段720P分辨率、10秒长的视频,ViBT仅需7.10秒,而对照组则高达28.6秒。超过4倍的速度提升,意味着在实际应用中,用户等待的时间从漫长的半分钟缩短到了仅仅几秒。
这种效率的飞跃,并不是通过牺牲质量换来的,而是通过去除冗余的计算路径实现的。
ViBT处理的Token数量远少于传统方法,在720P视频任务中,它仅需处理约14.7万个Token,而传统方法需要处理近30万个。
以前的观点普遍认为,布朗桥模型应该使用极小的噪声尺度,比如0.005,以此来接近确定性的整流流。ViBT的实验结果反驳了这一教条。
在深度图转视频任务中,表现最好的噪声尺度是2。在图像编辑任务中,最佳值是0.5。

这表明,在大规模模型和复杂任务中,保留适当的随机性对于提升生成质量至关重要。
过小的噪声会限制模型的探索能力,而过大的噪声则会破坏数据的结构。
推理的时间步调度也是影响质量的关键。实验对比了线性调度和偏移调度。
结果发现,采用偏移系数为5的调度策略效果最好。
这种策略将更多的计算资源分配给了生成的早期阶段,让模型在最初的几步里就能确立清晰的图像结构。
这使得ViBT即使在极少的推理步数下,比如4步或8步,也能生成高质量的结果。
ViBT的出现,展示了在生成式AI(人工智能)的赛道上,除了堆砌算力和数据,数学原理的创新依然具有四两拨千斤的力量。
通过方差稳定的速度匹配和方差校正采样,它成功驯服了布朗桥这一经典的随机过程,使其服务于最前沿的视觉生成任务。
参考资料:
https://yuanshi9815.github.io/ViBT_homepage/
https://github.com/Yuanshi9815/ViBT
https://arxiv.org/abs/2511.23199


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









