





文章链接:https://arxiv.org/pdf/2411.00776
项目链接:https://yucornetto.github.io/projects/rar.html
代码&模型链接:https://github.com/bytedance/1d-tokenizer
亮点直击
RAR(随机排列自回归训练策略),这是一种改进的训练策略,使得标准的自回归图像生成器能够实现SOTA性能。
引入双向上下文学习:RAR通过最大化所有可能的分解顺序的期望似然值,打破了自回归模型在视觉任务中的单向上下文限制,使模型能够在图像生成中更有效地利用双向上下文信息。
保持与语言建模框架的兼容性:RAR在提升图像生成性能的同时,保留了自回归建模的核心结构,它与大语言模型(LLM)的优化技术(如KV-cache)完全兼容,相比于MAR-H或MaskBit,采样速度显著更快,同时保持了更好的性能,便于在多模态统一模型中应用。
创新的退火训练策略:训练初期将输入序列随机排列,随着训练逐步回归至标准光栅顺序。这一过程使模型在各类上下文排列中均能获得优化,提升生成质量。
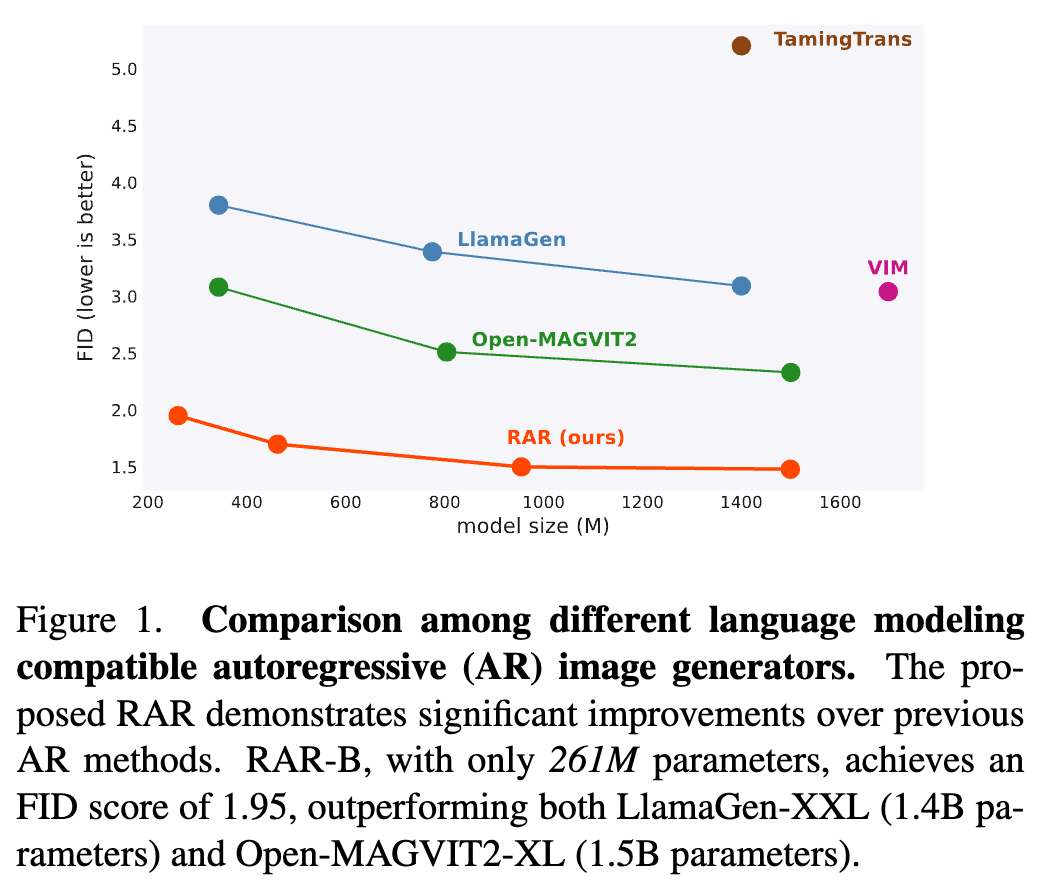
显著的性能提升:在 ImageNet-256 基准测试中,RAR实现了1.48的 FID 分数,显著超越了先前的自回归图像生成器,显示了其在图像生成任务中的突破性改进。
总结速览
解决的问题:
RAR(随机自回归建模)旨在提升图像生成任务的表现,同时保持与语言建模框架的完全兼容性。
提出的方案:
RAR采用了一种简单的方法,通过标准的自回归训练过程并结合下一个 token 预测目标,将输入序列随机打乱到不同的分解顺序。在训练过程中,使用概率 r 将输入序列的排列顺序随机化,其中 r 从 1 开始并逐渐线性衰减至 0,以让模型学习所有分解顺序的期望似然值。
应用的技术:
RAR在训练中应用了一种退火策略,使模型能够更好地利用双向上下文信息来建模,同时仍然保持自回归建模框架的完整性,从而实现了语言建模的完全兼容性。
达到的效果:
在 ImageNet-256 基准测试中,RAR 获得了 1.48 的 FID 分数,超越了之前最先进的自回归图像生成器,并优于领先的基于扩散和掩码Transformer的方法。
方法
背景
简要概述了基于下一个 token 预测目标的自回归建模。给定一个离散的 token 序列 ,自回归建模的目标是通过正向自回归分解来最大化该序列的似然。具体而言,目标是最大化在给定所有先前 tokens 的情况下预测当前 token 的联合概率
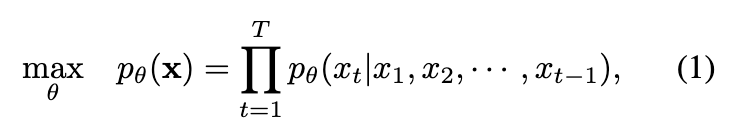
在自回归建模中,模型参数 定义了一个 token 分布预测器 ,用于预测给定位置的 token 分布。
由于在自回归模型中每个位置 t 的 token 仅依赖于之前的 tokens,这限制了模型只能进行单向的上下文建模。与此不同的是,masked transformer和扩散模型能够在训练时利用双向上下文。此外,尽管自然语言有固有的顺序(例如大多数语言从左到右),图像数据却缺乏固定的处理顺序。在图像生成任务中,行优先顺序(即光栅扫描)被广泛采用,并显示出优于其他替代方法的效果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1638
1638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









