




10月10日,由中科算网科技有限公司、算泥AI开发者社区联合主编,中国科学技术大学苏州高等研究院联合发布的《AI 大模型与异构算力融合技术白皮书》正式发布。白皮书精准聚焦当前大模型开发领域的核心痛点,致力于为开发者提供全面且实用的技术参考,助力推动大模型与异构算力实现深度融合。
以下为报告部分内容节选。
全球AI大模型发展概况
AI大模型与异构算力融合技术白皮书
国际大模型技术演进
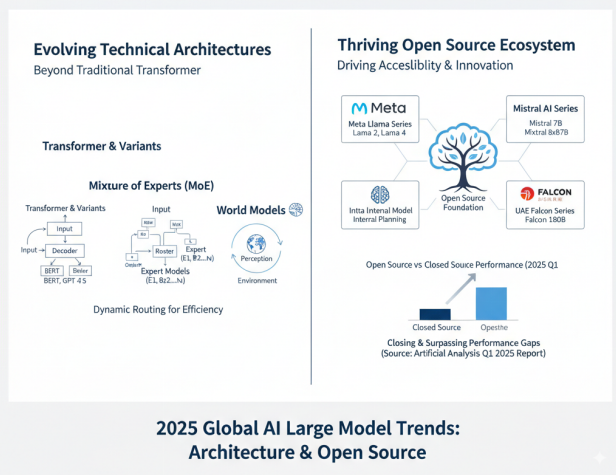
2025年,全球AI大模型技术呈现出快速迭代、规模持续扩大、效率显著提升的发展趋势。以OpenAI的GPT系列为代表,从GPT-3的1750亿参数发展到GPT-4的预估1.7万亿参数规模,再到GPT-5可能达到3至50万亿参数,模型参数量呈指数级增长。Meta的Llama系列作为开源大模型的标杆,2025年4月发布的4.0版本首次采用MoE(Mixture of Experts)架构,提供了三个不同规模的版本:Llama 4 Scout(1090亿参数)、Llama 4 Maverick(4000亿总参数,170亿激活参数)和Llama 4 Behemoth(2万亿总参数,2880亿激活参数,16个专家),展现了大模型架构的创新方向。

全球AI大模型参数规模的指数级增长与MoE架构的创新应用
在技术架构方面,Transformer已成为大模型的主流架构基础,同时各种创新变体不断涌现。MoE(混合专家模型)架构通过动态路由机制,在保持模型容量的同时显著降低了计算成本;世界模型(World Models)探索构建对环境的内部表征,为实现更通用的人工智能提供了新思路;多模态能力成为大模型的标配,从单一的文本处理扩展到图像、音频、视频等多种模态的理解和生成。2025年8月,Anthropic发布Claude Opus 4.1,将编码性能提升至SWE-bench Verified基准测试的74.5%,显著增强了深度研究和数据分析能力。
AI大模型技术架构的演进与开源生态的繁荣
开源生态的繁荣是国际大模型发展的另一重要特征。智谱的GLM系列、Meta的Llama系列、阿里的Qwen系列、腾讯混元系列、Mistral AI的Mistral系列、阿联酋的Falcon系列等开源模型的发布,极大地推动了大模型技术的普及和创新。这些开源模型不仅提供了强大的基础能力,还通过开放的权重和代码,为研究者和开发者提供了宝贵的实验平台,催生了大量基于开源模型的改进和应用。据Artificial Analysis公司2025年
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









