



谷歌Gemini 3击败了OpenAI,Nano Banana Pro震惊了世界。
要问我模型为什么这么强?且看Ironwood架构TPU v7你需要知道的3件事。

谷歌发布的第七代TPU Ironwood,是DeepMind团队用AlphaChip设计的芯片,以9.6 Tb/s的光互联带宽和1.77 PB的共享显存池,彻底重构了大模型推理的硬件基准。
11月25日,谷歌云揭开了其第七代定制芯片——Ironwood的面纱。
不同于以往单纯追求浮点运算能力的提升,这款芯片展现了谷歌对AI发展阶段的最新判断:训练不再是唯一的瓶颈,如何高效、实时地服务那些千亿参数的庞然大物,才是商业闭环的关键。
Ironwood是谷歌将DeepMind的研究能力与底层硅工程深度绑定的产物,其核心逻辑在于用极致的带宽换取模型响应的低延迟。
推理时代的硬件重构与光互联
过去几年,所有的目光都集中在训练上,如何让模型变得更聪明是唯一的考量。
随着Gemini等前沿模型进入大规模应用,算力消耗的重心不可避免地向推理倾斜。
推理和大模型训练对硬件的需求截然不同。
训练需要吞吐量,是可以容忍一定延迟的批处理任务。
推理则是实时的,它要求芯片在毫秒级的时间内响应用户的请求,每一个Token的生成都必须争分夺秒。
Ironwood正是为此而生。
官方数据显示,Ironwood在单芯片性能上相比上一代实现了超过4倍的提升。
这并非单纯依靠制程红利,而是源于架构层面对数据流动的优化。
在大模型推理中,计算单元往往因为等待数据搬运而空转。
Ironwood通过并行处理优化,最大限度地减少了数据在芯片内部穿梭(Data Shuttle)的时间。
真正的杀手锏在于片间互联(ICI)。
现代AI不再是单打独斗,而是集群作战。
当一个模型的参数量超过单卡显存上限时,模型必须被切分到成百上千张芯片上。
此时,芯片之间的通信速度决定了整个系统的短板。
Ironwood引入了速率高达9.6 Tb/s的ICI网络。
这是一个惊人的数字。在通用的数据中心网络中,400 Gb/s或800 Gb/s已属高端,而谷歌在TPU之间构建了一条比主流网络快一个数量级的高速公路。
这种极高带宽的直连,使得数据在芯片间传输的延迟几乎可以忽略不计。

物理上,它们是独立的硅片;逻辑上,它们被融合成了一颗巨大的超级芯片。
这种设计思路直接挑战了传统的冯·诺依曼架构瓶颈。
在Ironwood集群中,计算与通信的边界变得模糊。
对于拥有万亿参数的MoE(混合专家)模型而言,不同专家模块分布在不同芯片上,9.6 Tb/s的带宽保证了模型在调用这些专家时,就像调用本地内存一样流畅。
超级节点与1.77PB内存池
算力的堆叠需要容器,谷歌给出的答案是Superpod(超级节点)。
根据技术文档,一个Ironwood Superpod最大可扩展至9,216个芯片。
将近万颗高性能芯片集成在一个单独的通信域中,这在工程上本身就是一项壮举。

支撑这一架构的核心不仅是算力,更是内存。
大模型时代,显存容量决定了能加载多大的模型,显存带宽决定了模型跑得有多快。
Ironwood Superpod提供了一个高达1.77 PB(Petabytes)的共享高带宽内存(HBM)池。
1.77 PB的概念大约相当于1800台高端消费级电脑的硬盘容量总和,但这全是超高速的HBM。
这意味着,即使是目前最庞大的前沿模型,也可以将全部参数完整地加载到这个高速内存池中,无需在慢速的硬盘和内存之间反复倒腾数据。
这种全内存驻留的模式,彻底消除了I/O瓶颈,让大规模推理的能效比达到了新的高度。
下图展示了谷歌TPU近几代的关键参数演进,可以清晰看到这种暴力美学的进化轨迹:
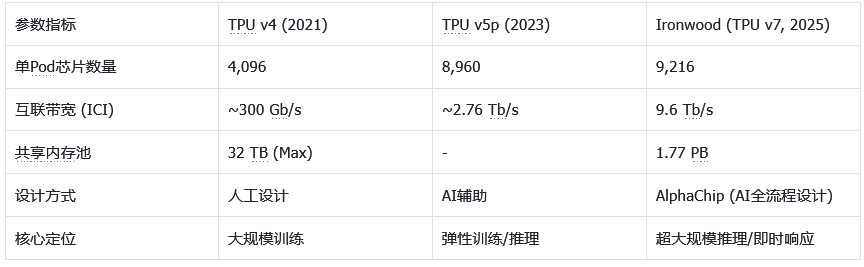
数据直接反映了战略重心的转移。从v4到Ironwood,互联带宽提升了30倍以上。
谷歌很清楚,在摩尔定律放缓的今天,单点的晶体管密度提升已经很难挖掘,唯有通过极致的互联将数量转化为质量。
AI设计AI:AlphaChip的闭环
Ironwood的另一个显著特征在于它的诞生地——它是由AI设计的。
芯片设计通常是一项耗时数年的人力密集型工作。
工程师需要花费大量精力规划电路布局(Floorplanning),以平衡散热、能耗和信号延迟。
这是一场在微米级画布上进行的复杂俄罗斯方块游戏。
谷歌DeepMind团队开发的AlphaChip改变了这一规则。
AlphaChip将芯片布局视为一个强化学习(Reinforcement Learning)问题。
通过在数以万计的布局方案中自我博弈和试错,AI能在几小时内生成优于人类资深工程师数周工作的布局方案。
Ironwood是连续第三代完全采用AlphaChip生成的TPU。
这种AI设计AI的模式构成了谷歌独有的飞轮效应:更强的TPU训练出更强的AlphaChip,更强的AlphaChip设计出下一代更强的TPU。
这种迭代速度是依赖传统EDA(电子设计自动化)工具的厂商难以企及的。
文档中提到,DeepMind的研究人员直接与硬件工程师协同工作。
当Gemini模型的架构师需要某种特定的算子加速时,他们可以直接影响TPU的设计指标。
这种软件定义硬件(Software Defined Hardware)的垂直整合能力,让谷歌在面对特定工作负载时,往往能比通用GPU取得更高的效率。
市场格局的暗流与英伟达的护城河
Ironwood的问世,不可避免地会被拿来与英伟达(Nvidia)的旗舰产品做对比。
长期以来,英伟达凭借CUDA生态和强大的NVLink技术统治着AI算力市场。
H100和Blackwell系列芯片几乎成为了硬通货。Ironwood的出现,从两个维度对这种垄断构成了冲击。
首先是推理成本的博弈。
对于训练任务,开发者或许离不开CUDA丰富的算子库。
但在推理阶段,任务相对单一且固定。
如果谷歌云通过Ironwood提供了比英伟达GPU更低延迟、更低成本的API服务,大量的商业客户会毫不犹豫地用脚投票。
毕竟,对于大多数应用层公司来说,他们不需要关心底层跑的是GPU还是TPU,他们只关心每百万Token的价格和响应速度。
其次是Meta等巨头的战略摇摆。
Meta虽然拥有自研芯片MTIA,但目前仍大量采购英伟达显卡。
Ironwood展示的技术路径——通过超高带宽互联解决显存墙问题——给行业提供了一个可行的替代方案。
Meta一直在寻求摆脱单一供应商依赖。
看到TPU在处理超大模型时的能效优势,扎克伯格(Mark Zuckerberg)可能会加速自研芯片向高带宽互联架构的演进,或者在部分非核心业务上尝试采用谷歌云的TPU算力作为补充。
虽然谷歌不会直接出售Ironwood芯片,但它作为一种云服务基础设施,分流了英伟达潜在的市场需求。
全球AI芯片市场正在从通用红利走向专用红利。
英伟达的GPU为了兼容图形渲染和各种科学计算,保留了大量通用架构。
而TPU去掉了所有与AI矩阵运算无关的部件,将晶体管全部投入到核心任务中。
在摩尔定律逼近物理极限的当下,这种专用化(Specialization)是提升性能的必经之路。
Ironwood是对未来计算范式的一种预演。
它告诉我们,未来的超级计算机不再是由无数个计算孤岛组成的松散联盟,而是一个由光和铜缆紧密编织在一起的神经网络。在这个网络中,数据不再需要长途跋涉,计算无处不在。
Ironwood提供了一个清晰的信号:AI算力的竞争,已经从单卡的肌肉秀,升级为集群通信和系统级设计的立体战。
参考资料:
https://blog.google/products/google-cloud/ironwood-google-tpu-things-to-know/
E

















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









