



AI 圈这几年什么最火?毫无疑问,是拼命把模型做大,从几十亿参数冲到万亿级别。
在人工智能发展的浪潮中,AI 巨无霸们都在购买芯片堆大模型,“越大越好”似乎已成为一种不可动摇的信仰。我们习惯了将最强大的通用大语言模型视为驱动一切AI应用的核心引擎。然而,全球AI硬件领导者,芯片生成者英伟达却给人一种反直觉的颠覆性疑问:小模型才是Agents的未来?
今天,英伟达正式推出Jet-Nemotron系列小模型,参数只有2B和4B,却直接在多项任务准确率上碾压不少庞然大物,推理效率更是最高飙升53.6倍!
推动这一颠覆性成果的,是一支全华人团队。
2025年初的CES展上,黄仁勋就已经明确点题:“基于AI Agent的Agentic AI,是接下来的重头戏。”那时候英伟达就亮出了NIMs和NeMo两大技术平台,帮助企业快速部署和管理AI Agent。
他还提到,英伟达要做的是给像ServiceNow、SAP、Oracle这些行业大佬们“递刀子”——提供开发AI Agent需要的工具包、库和模型,把整个AI生态的地基打好。
英伟达一直钟爱小模型,上一周他们刚刚发布了只有9B大小的NVIDIA Nemotron Nano 2模型,今天Jet-Nemotron又横空出世。

很多人可能一开始都想不通:为什么是小模型?大模型不是知识渊博、全能无敌吗?
小模型,真的已经强到离谱。
例如6.7B参数的Toolformer学会调API之后,性能直接超车175B的GPT-3;7B的DeepSeek-R1-Distill在多项推理任务上居然打赢了Claude3.5和GPT-4o。
这说明什么?“小”不等于“弱”。只要设计得好、训得巧,小模型在特定场景下完全可以比大模型还能打。
更别说,AI Agent里的大部分任务根本就不是开放聊天那种——而是高度结构化、格式固定的“机器对机器”对话,比如把用户指令转成一个标准JSON调用。
这种活儿,小模型干起来反而更利索:响应快、资源省、行为稳,不会随便瞎编乱造。反观大模型,成本高还难控制。
说到成本,就更致命了。
一个7B参数的小模型,推理成本比70B~175B的大模型便宜10~30倍!微调也快,几小时就能搞定,不用像大模型那样一等好几周。
便宜又好用,边缘设备也能跑,迭代起来飞快——这种经济性和灵活性,才是真正能落地的AI。
那么,Jet-Nemotron到底强在哪?
它最核心的突破,是两个技术大招:PostNAS(训练后架构探索适配)和新型线性注意力模块 JetBlock。
以往要找更好的模型架构,都得从头开始训练,耗时耗力还烧钱。但PostNAS不一样——它直接在一个已经预训练好的Transformer模型上动手术。
通过将PostNAS应用于基线模型后,在所有基准测试上都取得了显著的准确率提升。
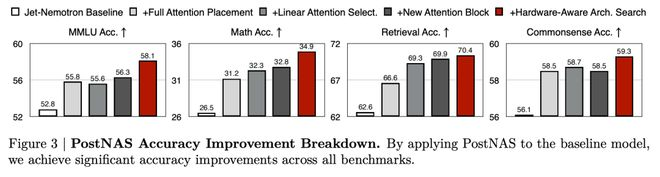
怎么做?四步走:
-
找准注意力层放哪儿最有效:不是每个注意力层都一样重要,PostNAS先锁定哪些层最关键;
-
线性注意力块择优上岗:系统性地测试现有模块,看谁又快又准;
-
设计新模块JetBlock:用动态卷积替代静态卷积,让模型能自适应学习;
-
硬件感知架构搜索:不光看参数量,还看实际硬件上跑得多快、多省。
通过PostNAS,引入了JetBlockJ新型线性注意力模块。它将动态卷积与硬件感知架构搜索相结合,以增强线性注意力,在保持与先前设计相似的训练和推理吞吐量的同时,实现了显著的准确率提升。
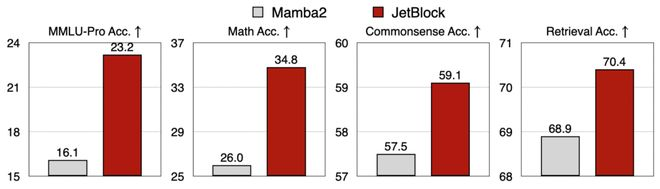
在同样的数据、同样的训练设置下,JetBlock的表现明显优于之前的明星模块Mamba2 Block。
光说不练假把式,是骡子是马,拉出来遛遛。
Jet-Nemotron-2B和4B在多项权威测试中全面开挂——对手是Qwen3、Gemma3、Llama3.2这些狠角色,但它俩依然做到了准确率更高、速度还更快。
具体来看:
-
Jet-Nemotron-2B:比Qwen3-1.7B-Base快21倍,MMLU、MMLU-Pro、数学、检索等指标全面领先;
-
Jet-Nemotron-4B:比Qwen3-1.7B-Base快47倍,准确度继续往上飙。
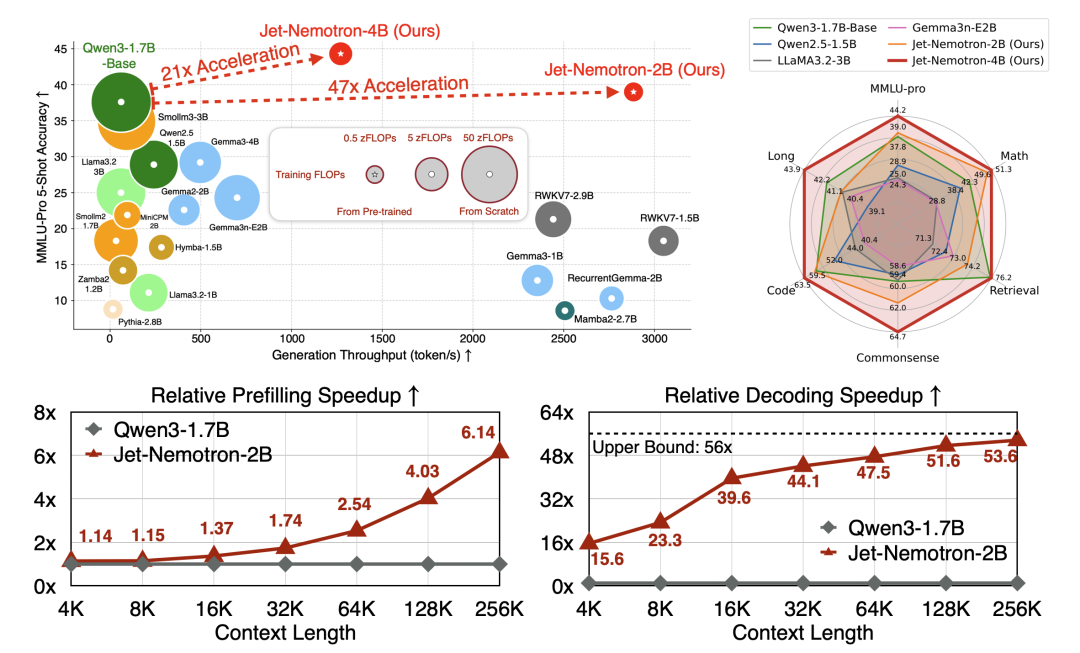
尤其是长上下文处理,上下文越长,Jet-Nemotron的优势越明显——解码吞吐量甚至能翻50多倍。
Jet-Nemotron简直就是“六边形战士”,雷达图几乎全满,又猛又稳。
如果说技术是“硬实力”,那英伟达带来的更是一场“架构观念”的地震。
以前的AI Agent是怎么搞的?基本靠调用一两个通用大模型(比如GPT-4o、Claude 4),让它们既当“大脑”,又当“打工人”——从理解意图到生成代码全包圆。
这种模式,像极了软件工程早期的单体架构:笨重、昂贵、难迭代。API调用烧钱如流水,响应延迟动不动抽风,明明很多任务根本不需那么大算力,却硬是用“牛刀杀鸡”。
就像从“单体应用”走向“微服务”,AI Agent也应该进入“小模型微服务”时代:
-
专家小模型:每人只干一件事,但做到极致。比如专门解析意图的、专门生成代码的、专门抽JSON的……它们小巧、高效、能独立迭代,Jet-Nemotron就是典型;
-
通用大模型:退居二线,当“API网关”或者复杂任务调度员,只处理真正需要通识和深推的难题;
-
智能控制器:轻量级路由,根据任务类型把请求精准分配给最合适的模型。
这样一来,整个系统就变得又灵活又省钱——绝大多数请求用小模型处理,成本暴降;单个模型挂了不影响整体;出新功能就加个新模型,像乐高一样随便组合。
Jet-Nemotron的发布,不只是一款模型的成功,更是一个强烈的信号:AI正在从小圈子技术走向普及化。
对企业来说,以后IT部门可能真得像“人力资源部”一样,去管理一支“AI员工团队”——谁擅长什么、怎么调度、如何协作,成了新的核心竞争力。
对硬件行业,边缘计算和专用推理芯片会迎来新机会。模型越小,硬件门槛越低,AI才能真正“飞入寻常百姓家”。
而对整个AI生态来说,英伟达选择开源Jet-Nemotron(代码和模型即将发布),无疑是在推动一场“小模型运动”。它不是在堆护城河,而是在搭舞台——让更多人能上台跳舞。
从硬件到软件,从训练到推理,从大模型崇拜到小模型实用主义——英伟达又一次踩准了节奏。
Jet-Nemotron用实力证明:AI的未来,未必是巨无霸的;精准、高效、经济的小模型,同样能掀起革命。
所以,如果你还在无脑追大模型,是时候重新思考了。
未来的AI Agent,不会再是“一个大模型包打天下”,而是——“一支精锐模型战队,分工协作,各司其职”。
这一局,英伟达又跑在了前面。
论文地址:https://arxiv.org/pdf/2508.15884
项目地址:https://github.com/NVlabs/Jet-Nemotron

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









