



我们花了几十年时间让计算机变得更加“人性化”,设计出直观的图形界面、优雅的交互方式,却在AI时代发现,这些专为人类设计的界面成了机器智能的“拦路虎”。
智谱AI发布了一个名为ComputerRL的自主桌面智能框架。在快速演进的AI驱动自动化领域,智谱AI推出的ComputerRL,是一个突破性框架,旨在赋予AI智能体导航和操控复杂数字工作空间的能力。目的,这就是要让AI真正学会像人一样使用电脑。
ComputerRL框架概述
当机器遇上人类界面
让我先跟你聊聊这个问题有多棘手。
现在的AI智能体面对电脑界面时,就像一个刚学会走路的孩子被扔进了迷宫。它们要么笨拙地模拟鼠标点击和键盘输入,要么只能调用那些冷冰冰的API接口。前者效率低得让人抓狂,后者又缺乏灵活性。
虽然人类能够完成超过72.36%的任务,但最好的模型只能达到12.24%的成功率,主要在GUI定位和操作知识方面存在困难。这个数据来自OSWorld基准测试,一个专门评估AI智能体在真实计算机环境中表现的权威测试。
想象一下,你要让AI帮你处理一份Excel表格,传统的方法要么是调用Excel的API(但很多功能API根本不支持),要么是让AI像一个视力不太好的老人一样,颤颤巍巍地找按钮、点菜单。这样的体验,怎么可能让人满意?
ComputerRL的巧思:API与GUI的完美融合
智谱AI的ComputerRL提出了一个我觉得相当聪明的解决方案——API-GUI混合范式。
简单来说,就是让AI在合适的时候用API的精确性,在必要的时候用GUI的灵活性。就像一个熟练的办公室老手,知道什么时候用快捷键,什么时候还是得老老实实点菜单。
这个框架最让我印象深刻的地方在于,它能自动构建API。用户只需要提供一些示例任务,系统就会分析需求,用相关的Python库实现API,甚至生成测试用例。比如,它为Ubuntu应用程序如GIMP和LibreOffice集成了API,让图像处理或文档格式化任务的步骤大大减少。
这不是为了炫技而用复杂的方法,而是为了解决问题选择最合适的工具。
千机并发的分布式训练
但光有好想法还不够,工程实现才是真正的挑战。
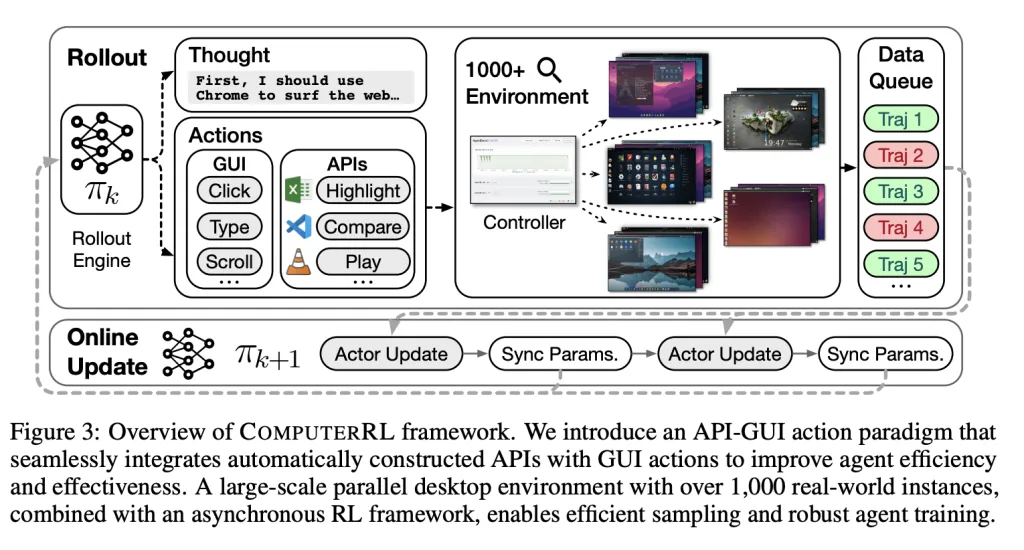
训练桌面AI智能体有一个巨大的痛点:虚拟环境太吃资源了。以前的系统动不动就卡死,网络瓶颈一堆,根本没法大规模训练。
ComputerRL用了一套基于Docker和gRPC的分布式强化学习基础设施,能够同时支持数千个并行的Ubuntu虚拟机。关键特性包括通过qemu-in-docker实现轻量级VM部署,多节点集群保证可扩展性,还有基于Web的监控界面。
配合AgentRL框架,这套系统实现了完全异步训练,把数据收集和参数更新解耦,大大提升了效率。这让高吞吐量的强化学习成为可能,支持动态批量大小和离策略偏差缓解,让长时间的训练不再停滞不前。
分布式强化学习基础设施架构
说句题外话,这种工程能力的积累,往往比算法创新更难,也更重要。很多AI公司都有不错的想法,但真正能把系统做到工业级别的,屈指可数。
解决探索衰减的妙招
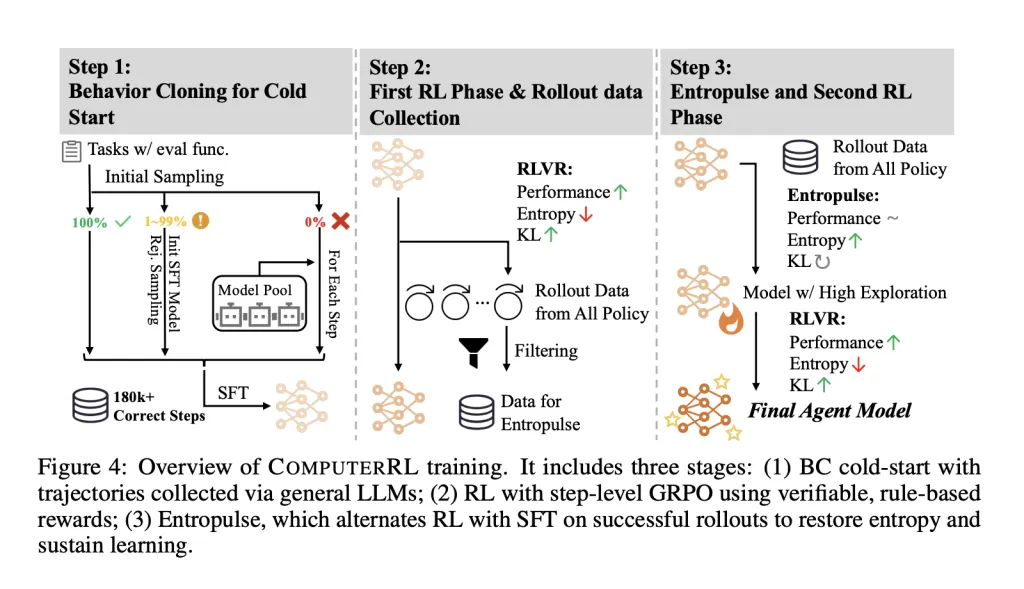
强化学习有个臭名昭著的问题叫“熵坍塌”——简单说就是AI在训练过程中会越来越保守,不愿意尝试新的动作,最终学习停滞。
ComputerRL引入了一个叫Entropulse的方法来解决这个问题。它会在强化学习阶段和监督微调之间交替进行,用成功轨迹的数据来恢复探索性,让AI保持学习的动力。
训练流水线从行为克隆开始,使用多个大语言模型的轨迹来增加多样性。然后应用步级别的组相对策略优化,配合基于规则的奖励系统,只对成功轨迹中正确且有贡献的动作给予正分。Entropulse通过从之前的推演中筛选出多样化、高质量的数据进行监督微调,防止过早收敛。
Entropulse训练方法示意图
类似人类学习的过程——我们不是单纯地重复成功的经验,而是在成功的基础上不断尝试新的可能性。ComputerRL在某种程度上模拟了这种学习模式。
OSWorld基准测试的亮眼表现
实际效果怎么样呢?
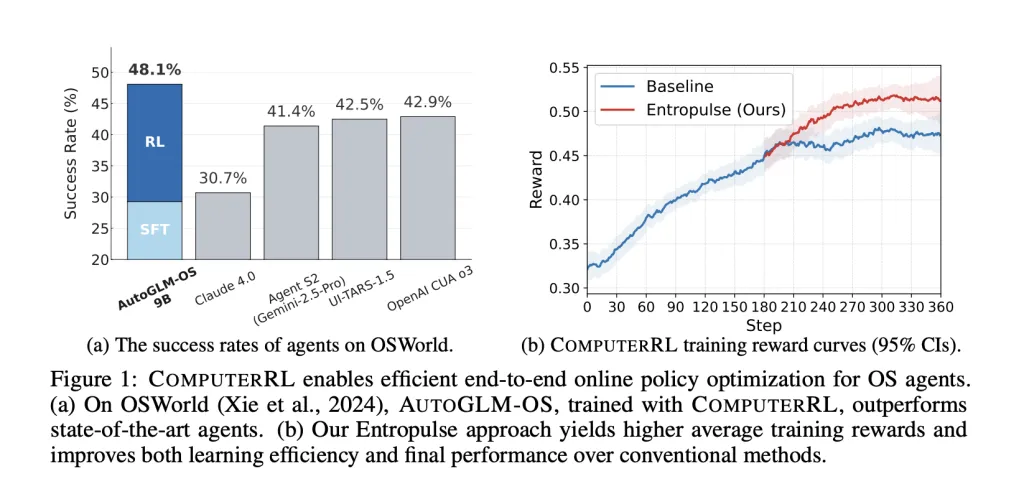
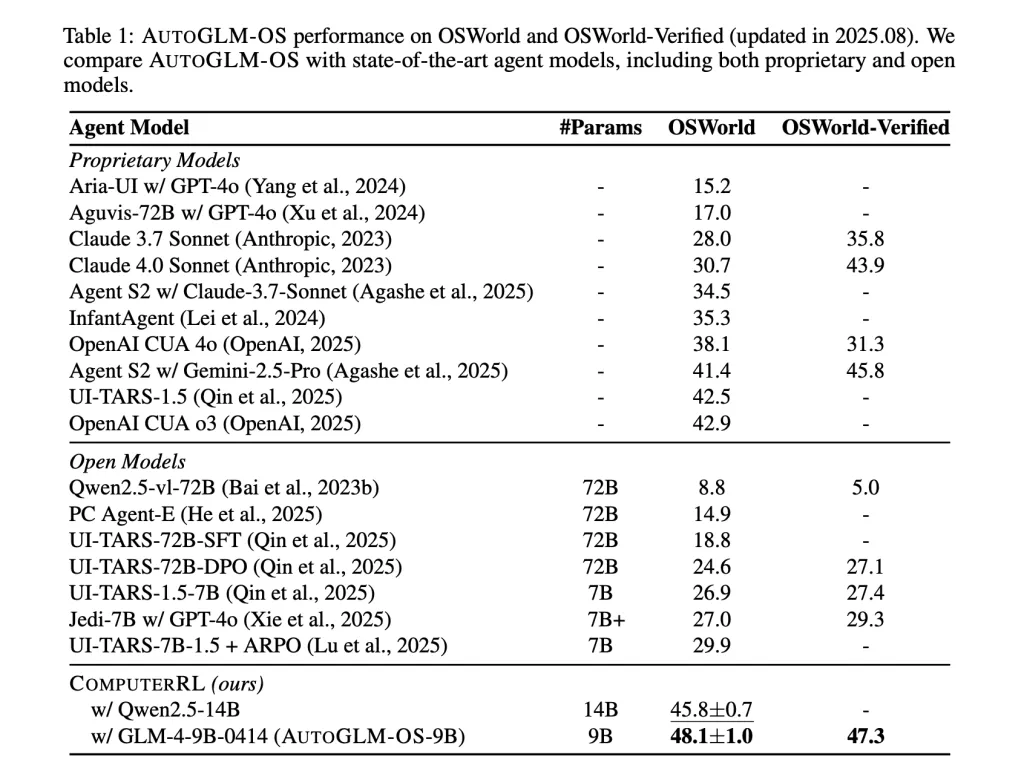
研究团队将ComputerRL应用到GLM-4-9B-0414和Qwen2.5-14B等开源模型上,产生了AutoGLM-OS系列变体。在OSWorld基准测试中,AutoGLM-OS-9B取得了48.1%的成功率,超过了OpenAI的CUA o3(42.9%)和Claude 4.0(30.7%)等专有模型。在OSWorld-Verified测试中也达到了47.3%的成绩。
这个结果相当令人振奋。要知道,人类测试者能够解决大约72.4%的OSWorld任务,而在OSWorld论文发表时,最好的AI智能体(一个为动作增强的最先进视觉语言模型)仅在12.2%的任务上成功。ComputerRL将这个数字提升到了48.1%,虽然离人类水平还有差距,但这已经是一个巨大的跃进。
更有意思的是消融研究(Ablation Study)的结果。API-GUI混合范式相比纯GUI方法提升了134%的成功率,特别是在办公和专业领域。训练消融实验显示,行为克隆提供了31.9%的基线,通过Entropulse启用的探索,强化学习阶段将成功率提升至45.8%。
OSWorld基准测试结果对比
让我们看几个具体的应用案例。比如在LibreOffice Calc中创建销售汇总表格,或者通过终端命令生成系统报告。这些看似简单的任务,对传统AI智能体来说却是不小的挑战,因为它们需要跨多个应用程序协调,涉及复杂的界面操作。
但ComputerRL训练出的智能体在这些任务上表现出了令人印象深刻的能力。当然,错误分析也揭示了一些挑战,比如视觉感知问题占失败原因的25.8%,多应用协调占34.4%。这些问题指向了未来改进的方向。
作为一个长期观察AI行业的人,我觉得ComputerRL的意义远不止技术层面的突破。
这代表了AI智能体开发思路的转变。从模仿人类操作到真正理解人机交互的本质,从单一的技术路线到多种方法的有机结合。
ComputerRL的开源,可能会加速整个桌面AI智能体领域的发展。
在AI代替人类成为打工人的路上,还有哪些阻碍吗?
当然,还有很多挑战。
视觉感知仍然是个大问题。AI需要更好地看懂界面,理解不同控件的功能和状态。多应用协调也是难点,现实工作中很多任务都需要在多个软件之间切换,这对AI的规划和执行能力提出了很高要求。
安全性也是不得不考虑的问题。当AI能够自主操作计算机时,权限管理、行为验证就变得至关重要。没有人愿意看到AI把重要文件删掉,或者执行危险的系统命令。
但ComputerRL为更强大的智能体铺平了道路,这些智能体将能够处理动态环境和长期任务。
我们拭目以待。
论文地址:https://arxiv.org/abs/2508.14040


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









