




 本文深入探讨了强化学习的基本概念及其与负反馈控制的区别,详细解析了马尔科夫决策过程(MDP)的五大要素及动态特性,并介绍了价值函数、最优策略等核心概念。
本文深入探讨了强化学习的基本概念及其与负反馈控制的区别,详细解析了马尔科夫决策过程(MDP)的五大要素及动态特性,并介绍了价值函数、最优策略等核心概念。
目录
1. 强化学习概念
1.1. 负反馈控制
在经典的自动控制原理中,控制信号 u u u是根据被控对象的状态进行控制的,同时再考虑被控量的理想值,最终能使被控量的实际值 和 理想值达到一致。
这样的控制作用基于经典的 负反馈思想
u ( t ) = K ( y ( t ) − y s ) u(t) = K(y(t) - y_s) u(t)=K(y(t)−ys)
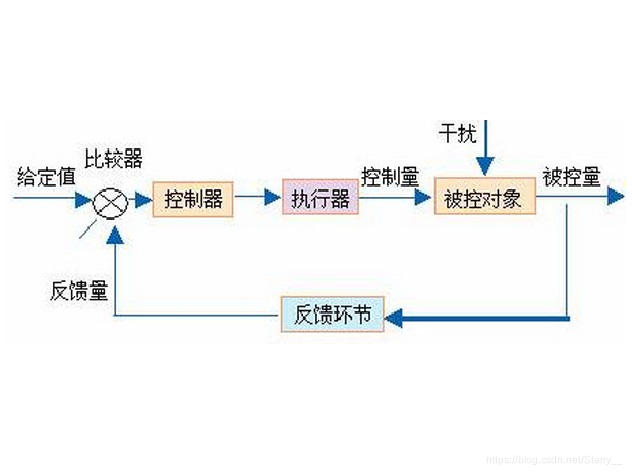
而对于离散系统,在 k k k时刻施加的控制信号 u ( k ) u(k) u(k) 是指在 k k k时刻观测到了系统状态 x ( k ) x(k) x(k)之后施加的控制信号,从而使系统状态由 x ( k ) x(k) x(k)变成 x ( k + 1 ) x(k+1) x(k+1)。而 u ( k ) u(k) u(k)的设计一定是使系统状态与预期值达到一致。
这样控制器和被控对象的交互就构成了一个序列:
x ( k ) , u ( k ) , x ( k + 1 ) , u ( k + 1 ) , . . . x(k), u(k), x(k+1), u(k+1),... x(k),u(k),x(k+1),u(k+1),...
控制作用就取决于 u ( k ) u(k) u(k)的式子了,经典控制中 u ( k ) u(k) u(k)的表达式是确定的,例如经典PID中的参数是先通过阶跃曲线法调好在加入控制回路中,LQR中的增益K也是提前计算好的。
同时也可以不断实验以调整 u ( k ) u(k) u(k)实现对系统的控制,最终得到针对某个特定系统的控制信号 u ( k ) u(k) u(k),这就是强化学习的思想。
1.2. 强化学习
强化学习的思路是是使智能体不断地控制,不断地从控制结果调整控制信号 u ( k ) u(k) u(k),最终完成控制。只不过强化学习的目标不再是使被控量收敛至预定值,而是达到最大的累积奖励。
比如你在写作业,在不知后果的情况下去打游戏,发现最后会被你妈打一顿。下次在写作业的时候,又去打游戏,然后又被打。长此以往你就知道了,跑去打游戏会被妈妈打,于是你选择继续写作业而不是去打游戏。强化学习就是基于这样的奖励机制调整控制策略的。
-
状态 State:即系统状态 x ( k ) x(k) x(k)。
-
动作 Action:针对当前状态施加的控制信号 u ( k ) u(k) u(k),从而智能体到达一个新的状态 x ( k + 1 ) x(k+1) x(k+1)
-
奖励 Reward:在状态 x ( k ) x(k) x(k)下应用某种动作 u ( k ) u(k) u(k)转移至另一个状态 x ( k + 1 ) x(k+1) x(k+1),会给出一个奖励值 r e w a r d [ x ( k ) , u ( k ) ] reward[x(k),u(k)] reward[x(k),u(k)]
-
值函数 Value function:在状态 x ( k ) x(k) x(k)下应用某种动作 u ( k ) u(k) u(k)会给出一个到达终止状态的累积奖励的期望 v a l u e F u n c t i o n [ x ( k ) , u ( k ) ] valueFunction[x(k),u(k)] valueFunction[x(k),u(k)]
值函数和奖励的区别在于,奖励只表达这一步行动的奖励值,值函数表达的是 这一步为开始,最终到达终止状态的所有奖励的和的期望值。即值函数衡量的是这一步对整体的贡献。当然值函数一定包括这一步的奖励。
-
策略 Policy:根据当前状态得出动作的方法,是基于值函数最大得出的动作,即 u ( k ) = P o l i c y ( x ( k ) , v a l u e F u n c t i o n ( ) ) u(k) = Policy( x(k),valueFunction() ) u(k)=Policy(x(k),valueFunction())。强化学习关注的是长远的利益而非眼前的奖励。
因此强化学习的目标就是得到 策略Policy,使智能体在任意状态下 达到最大的累积收益。
而这个策略的得出,则需要不断地训练调整得出。就需要智能体不断地探索数据,探索每一步的未来的累积收益如何,并利用这些探索的数据进行策略更新。
参考资料
2. 马尔科夫决策过程(Markov decision process, MDP)
马尔科夫决策过程 是强化学习中智能体应用策略的过程,与离散系统的控制类似,在当前状态施加一个行为,得到新的状态,并得到一个收益。
x ( k ) , u ( k ) , r e w a r d ( k + 1 ) , x ( k + 1 ) , u ( k + 1 ) , . . . x(k), u(k), reward(k+1), x(k+1), u(k+1),... x(k),u(k),reward(k+1),x(k+1),u(k+1),...
2.1. 定义
典型的MDP包含如下五个要素

其中
- S S S:系统状态的有限集合
- A A A:系统可采取的行动的的有限集合
- π ( a ∣ s ) \pi(a|s) π(a∣s):表示在状态 s s s下选择动作 a a a的概率,可看作在该状态下的随机策略。 π ( s ) \pi(s) π(s)表示状态 s s s下选择的动作,为确定性策略。用 π \pi π表示任意状态下的动作策略。
- R ( s , a , s ′ ) R(s,a,s') R(s,a,s′):收益,表示在状态 s s s下采取动作 a a a到达新状态 s ′ s' s′而获得的奖励。
- G G G:回报,在时间 [ 1 , T ] [1,T] [1,T]内所有行动的收益累积
因此MDP就是在状态 s s s下根据 π ( a ∣ s ) \pi(a|s) π(a∣s)求得行为 a a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











