




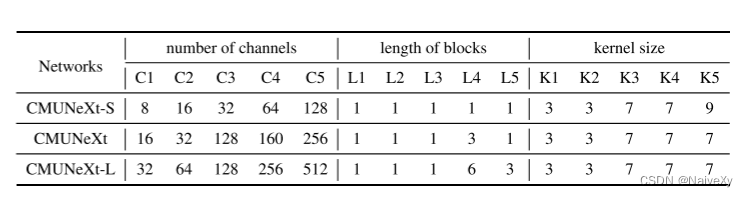
 本文介绍了一种名为CMUNeXt的轻量级医学图像分割网络,通过结合大内核和跳跃融合机制,有效提取全局上下文信息,改善了现有网络在资源受限环境下的性能,特别适合部署在移动和边缘设备上,提升诊断效率。
本文介绍了一种名为CMUNeXt的轻量级医学图像分割网络,通过结合大内核和跳跃融合机制,有效提取全局上下文信息,改善了现有网络在资源受限环境下的性能,特别适合部署在移动和边缘设备上,提升诊断效率。
CMUNeXt:一种基于大核和跳跃融合的高效医学图像分割网络
U形结构已经成为医学图像分割网络设计中的一个重要范例。然而,由于卷积固有的局部限制,具有U形架构的完全卷积分割网络难以有效地提取全局上下文信息,这对于精确定位病变至关重要。虽然结合CNN和Transformer的混合架构可以解决这些问题,但由于环境和边缘设备施加的计算资源限制,它们在真实的医疗场景中的应用受到限制。此外,轻量级网络中的卷积归纳偏差巧妙地适应了稀缺的医疗数据,这是基于Transformer的网络所缺乏的。
为了在利用归纳偏差的同时提取全局上下文信息,我们提出CMUNeXt,一个高效的全卷积轻量级医学图像分割网络,它能够在真实的场景场景中快速准确地辅助诊断。CMUNeXt利用大内核和反向瓶颈设计来彻底混合远程空间和位置信息,有效地提取全局上下文信息。我们还介绍了跳过融合块,旨在实现平滑的跳过连接,并确保充分的功能融合。在多个医学图像数据集上的实验结果表明,CMUNeXt在分割性能方面优于现有的重量级和轻量级医学图像分割网络,同时提供更快的推理速度,更轻的权重,和降低的计算成本。
轻量级分割网络适合部署在移动的和边缘设备上,为医生和患者提供快速访问辅助诊断结果的能力。此外,边缘部署可以解决使用以服务器为中心的模型时与数据传输相关的隐私问题。在这些模型中,UNeXt(Valanarasu和Patel 2022)基于CNN和MLP的混合架构设计了一种轻量级医学图像分割网络;Tolstikhin等人利用并改进了ConvNeXt块以实现高效分割。虽然大多数轻量级网络通过减少网络的宽度和深度来降低复杂性,但这种方法可能具有缺点,因为降低复杂性可能导致网络性能下降。此外,全局背景信息对于准确定位医学图像中的病变是至关重要的。尽管基于Transformer的分割网络减少了参数以匹配移动终端资源约束,但它们的性能明显劣于轻量级CNN。卷积的归纳偏差可以更好地拟合稀缺的医学数据,这是ViT网络所缺乏的。
最近,一些提出的工作已经利用具有大卷积核的CNN作为Transformer的替代方案来提取全局上下文信息。例如,ConvMixer(Trockman和Kolter 2022)使用大卷积核来混合远距离空间位置信息,而RepLKNet(Ding et al. 2022)使用31 X31超大卷积核提取全局信息。ConvNeXt(Liu et al. 2022)使用大卷积核和Swin Transformer(Liu et al. 2021)架构设计技巧,以提高全卷积网络在各个方面的性能。具有大核的卷积可以利用卷积归纳偏差,同时获得更大的感受野信息。然而,上述工作仅适用于一般的自然图像,自然图像与医学图像之间的巨大差距使得其难以应用于医学场景。为了解决上述问题,使其满足真实的的诊断应用需求,我们提出了CMUNeXt,一个完全卷积的轻量级医学图像分割网络,遵循U形架构设计,由具有跳过连接的五级编码器-解码器结构组成。我们重新设计了网络的每个模块,以实现最佳性能,同时保持重量更轻。
为了有效地提取全局上下文信息,同时减少冗余参数,受ConvMixer(Trockman和Kolter 2022)和ConvNeXt(Liu et al. 2022),我们提出了编码器阶段中的CMUNeXt块。CMUNeXt块将普通卷积替换为具有大内核的深度卷积和具有反向瓶颈设计的两个逐点卷积,以充分混合远距离空间和位置信息。在具有跳过连接的解码器阶段,提出了跳过融合块以实现平滑的跳过连接。它使用分组卷积与两个反向瓶颈设计逐点卷积,以取代普通卷积之间的编码器和解码器的语义特征充分融合。我们选择了四个乳腺和甲状腺超声医学图像数据集来评估CMUNeXt。大量的实验结果表明,CMUNeXt实现了分割性能和计算消耗之间的更好的权衡比其他先进的和广泛使用的分割方法。该方法具有参数少、计算量小、推理速度快等优点。
值得注意的是,我们选择超声数据集进行评估的原因是病变的位置是不固定的,病变的特征表现出多尺度和大的形态差异,这可以更好地说明我们提出的方法在提取医学图像的全局上下文信息的有效性。这项工作在以下方面作出了贡献:
1.提出了CMUNeXt,这是一种轻量级的完全卷积医学图像分割网络,可以有效地提取医学图像中的全局上下文信息,并实现快速精确的分割。
2.引入了CMUNeXt块用于提取全局信息,它可以以最小的参数充分提取和混合医学图像中的远距离空间和位置信息。
3.提出了跳过融合块中的skipconnections平滑功能融合,这使得编码器的知识有效地转移到解码器。
4.进行了大量的实验,以证明CMUNeXt实现了最佳分割性能和计算消耗之间的更好的权衡。
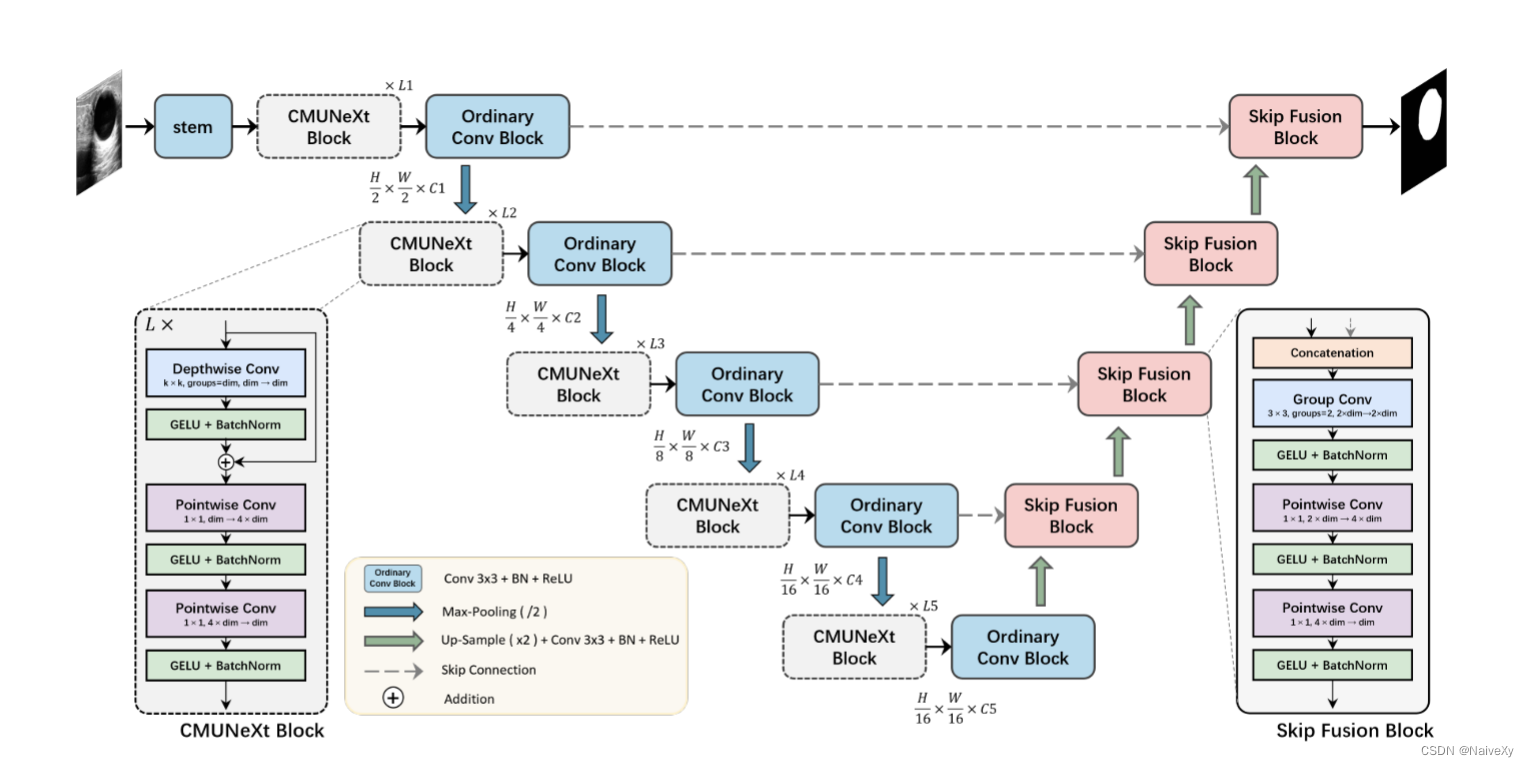 提出的CMUNeXt的架构如图所示。从上到下由五层组成,分为两个阶段:编码器级和解码器级具有跳跃连接。在编码器阶段,采用CMUNeXt块来提取不同级别的全局上下文信息,然后是普通卷积块来扩展通道的数量。在具有跳过连接的解码器阶段中,跳过融合块用于将来自编码器的全局语义特征与来自解码器的上采样特征完全融合。每层中CMUNeXt块的长度从上到下表示为L1到L5,并且每个块的内核大小为K1到K5,其中通道的数量为C1到C5。
提出的CMUNeXt的架构如图所示。从上到下由五层组成,分为两个阶段:编码器级和解码器级具有跳跃连接。在编码器阶段,采用CMUNeXt块来提取不同级别的全局上下文信息,然后是普通卷积块来扩展通道的数量。在具有跳过连接的解码器阶段中,跳过融合块用于将来自编码器的全局语义特征与来自解码器的上采样特征完全融合。每层中CMUNeXt块的长度从上到下表示为L1到L5,并且每个块的内核大小为K1到K5,其中通道的数量为C1到C5。
如图所示,编码器从上到下包括五个级别,每个级别由CMUNeXt块、普通卷积块和下采样操作组成。此外,我们利用stem提取原始特征的输入图像的顶层。
stem:在诸如ResNet(He et al. 2016)和ConvNeXt(Liu et al. 2022)会降低输出的分辨率并导致与顶层的跳过连接不一致。为了避免这种情况,我们采用了一个普通的卷积块,它配备了一个卷积层,一个批量归一化层和一个ReLU激活,内核大小为3×3,步幅为1,填充为1。通过使用这种方法,我们可以保持与顶层的跳过连接的一致性,并确保在编码过程中不会丢失重要的特征。
CMUNeXt Block的核心组件是深度可分离卷积,其已由MobileNetv2(Sandler et al. 2018)和MobileVit(Mehta和Rastegari 2021)。深度可分离卷积使用深度卷积的组合(即,组的数量等于信道)和逐点卷积(即,核大小为1×1)来代替完整的普通卷积运算。分离的深度卷积用于提取空间维度信息,并且随后的逐点卷积导致空间和通道混合的分离。与普通卷积相比,深度卷积可以有效地减少网络参数和计算量。在CMUNeXt块中,我们使用大内核大小的深度卷积来提取每个通道的全局信息,然后是残差连接。为了充分混合空间和信道信息,我们在深度卷积之后应用两个逐点卷积,并对它们执行反向瓶颈设计。这种设计涉及将两个逐点卷积层之间的隐藏维度设置为输入维度的四倍宽。倒置瓶颈设计已经在ConvNeXt(Liu et al. 2022年)。扩展后的隐维能够全面、充分地融合深度卷积提取的全局空间维信息。此外,我们在每个卷积之后利用GELU激活和激活后BatchNorm层。
下采样。许多方法,例如ConvNeXt(Liu et al. 2022)和MobileVit(Mehta和Rastegari 2021)利用步长为2的卷积对自然图像进行空间下采样。引入独立的下采样层可以增强训练期间的稳定性,同时提高性能。然而,医学图像通常表现出低分辨率和较小的局部边缘变化。与使用卷积进行下采样相比,传统的池化操作可以有效地滤除医学图像中存在的噪声,同时保持最小的计算开销。因此,CMUNeXt中采用的下采样策略是最大池化,采用2×2的滤波器窗口和2的步长。
跳过-融合块。传统的跳过连接通常使用普通卷积操作进行特征融合,这可能是直接和钝的,并且它增加了编码器和解码器的负担。在我们的Skip-Fusion块中,我们利用组卷积作为核心组件来解决这些问题。我们将卷积操作分成两组,并分别对跳过的编码器特征和上采样的解码器特征执行“逐特征”提取。组卷积的核大小为3×3,步长为1,填充为1。为了实现充分的特征融合,我们在组卷积之后合并了两个反向瓶颈逐点卷积。SkipFusion块将融合前的特征自适应分配给组卷积。而高效稠密的逐点卷积承担了繁重的特征融合工作。此外,Skip-Fusion块中的每个卷积之后是GELU激活和BatchNorm层。
上采样块。上采样块由上采样层、卷积层、批量归一化层和ReLU激活函数组成。我们利用双线性插值来对特征图上采样两倍。卷积层的内核大小为3×3,步长为1,填充为1。通过采用这些技术,我们能够有效地提高分辨率的特征图,同时保留重要的功能。
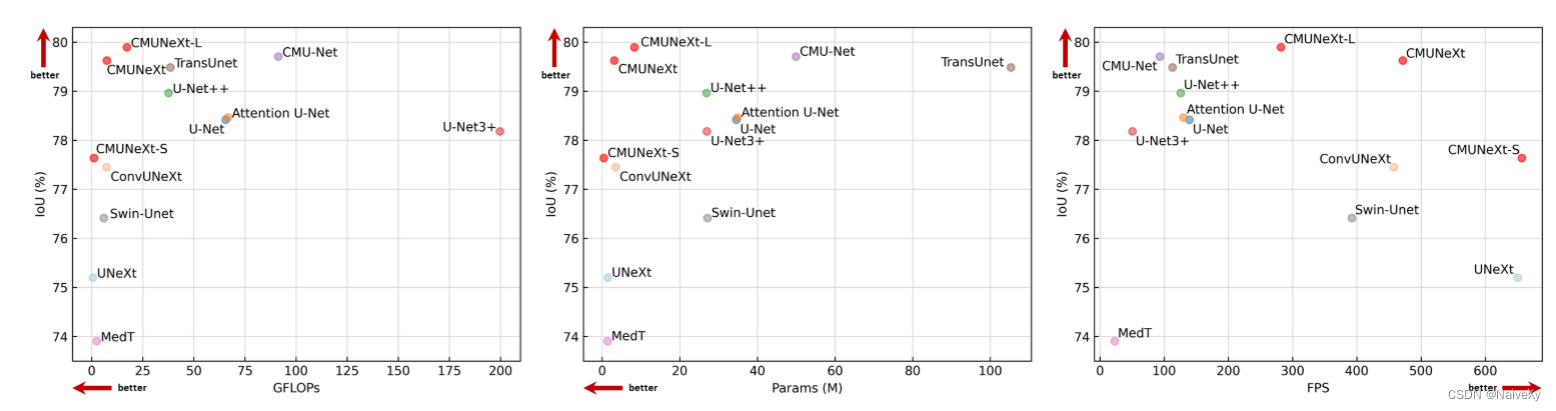
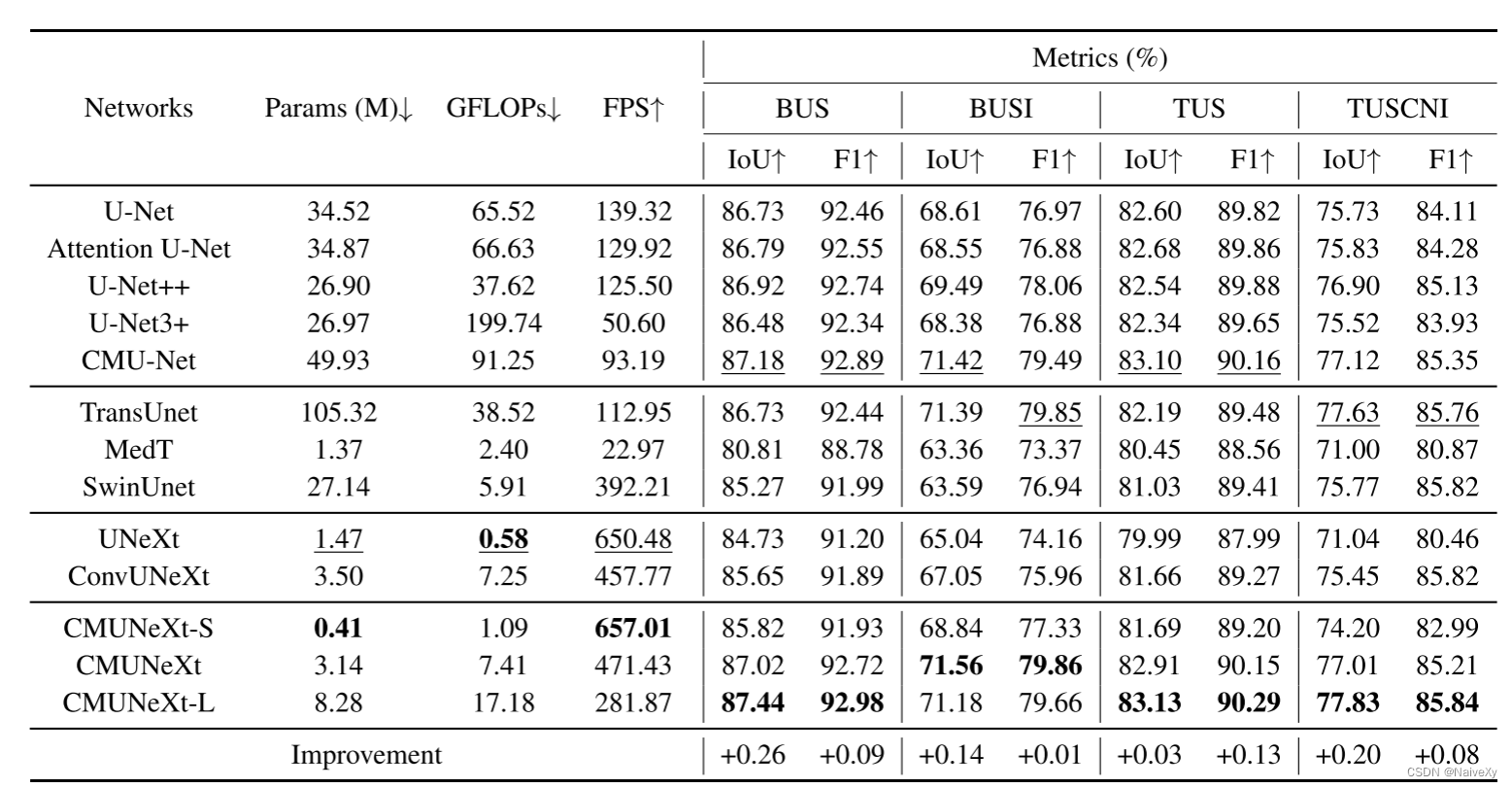

在这项工作中,我们提出了一种新的轻量级医学图像分割网络,CMUNeXt,通过一个精致的网络设计,实现了分割性能和计算消耗之间的最佳权衡。我们的大量实验表明,归纳偏差和大核卷积在轻量级网络中是至关重要的,在适合稀缺的医学数据和实现高分割性能的医学图像。此外,我们还提供了三种不同的CMUNeXt架构变体,每种变体都是针对不同边缘和设备平台上部署的环境和性能要求而定制的。这些变体能够在各种真实场景中实现快速准确的辅助诊断。总的来说,我们提出的CMUNeXt架构为医学图像分割任务提供了一个有前途的解决方案,有可能显着提高诊断的准确性和效率。


















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









