




 文章提出了一种名为DCA的双交叉注意力模块,用于增强基于U-Net的医学图像分割模型。DCA通过通道交叉注意(CCA)和空间交叉注意(SCA)捕获编码器和解码器特征之间的语义联系,解决了多尺度特征的空间和通道依赖性问题。实验表明,DCA能有效提升模型性能,适用于医学图像分析任务。
文章提出了一种名为DCA的双交叉注意力模块,用于增强基于U-Net的医学图像分割模型。DCA通过通道交叉注意(CCA)和空间交叉注意(SCA)捕获编码器和解码器特征之间的语义联系,解决了多尺度特征的空间和通道依赖性问题。实验表明,DCA能有效提升模型性能,适用于医学图像分析任务。
用于医学图像分割的双交叉注意力
我们提出了双交叉注意力(DCA),一个简单而有效的注意力模块,能够增强基于U-Net的skip-connections架构,用于医学图像分割。DCA通过顺序捕获跨多尺度编码器特征的通道和空间依赖性来解决编码器和解码器特征之间的语义差距。
首先,通道交叉注意(CCA)通过利用多尺度编码器特征的跨信道标记的交叉注意来提取全局信道依赖性。然后,空间交叉注意(SCA)模块执行交叉注意以捕获跨空间令牌的空间依赖性。最后,这些细粒度编码器特征被上采样并连接到它们对应的解码器部分以形成跳过连接方案。
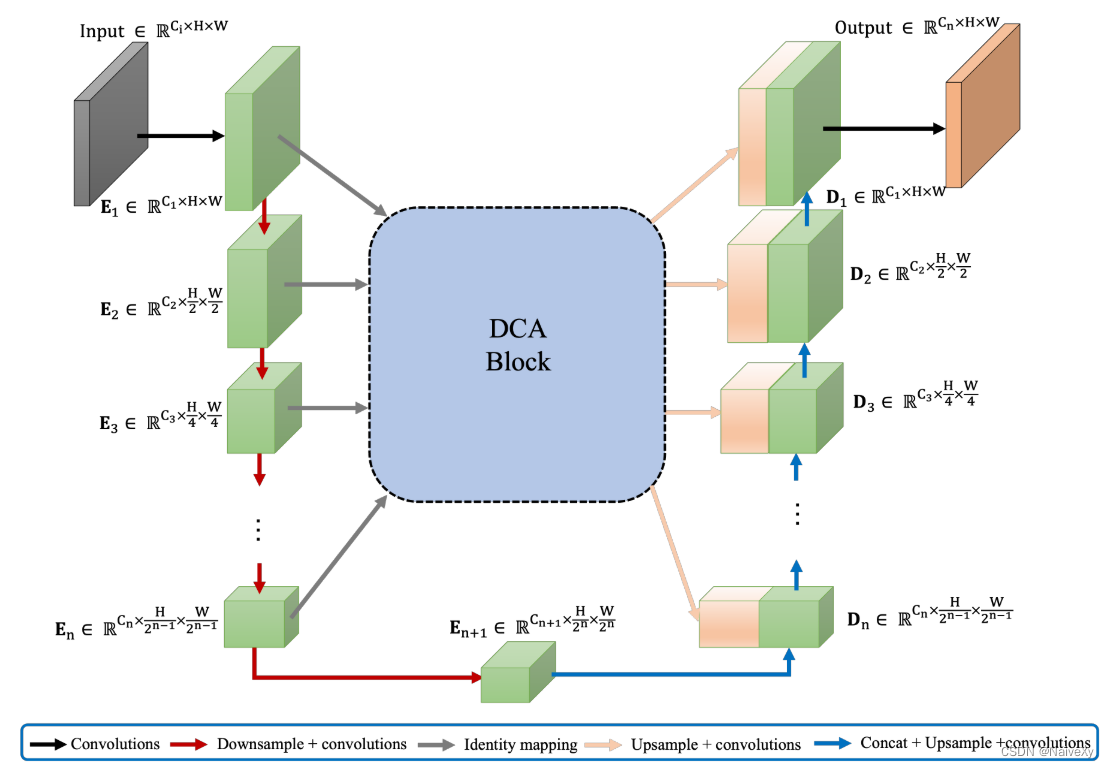
上图说明了提出的DCA块集成到一个通用的FCN架构skipconnections。DCA块的架构是不变的编码器阶段的数量(给定n+1个多尺度编码器级,DCA块将来自前n个级的多尺度特征作为输入,产生增强表示,并将它们连接到它们对应的n个解码器级)
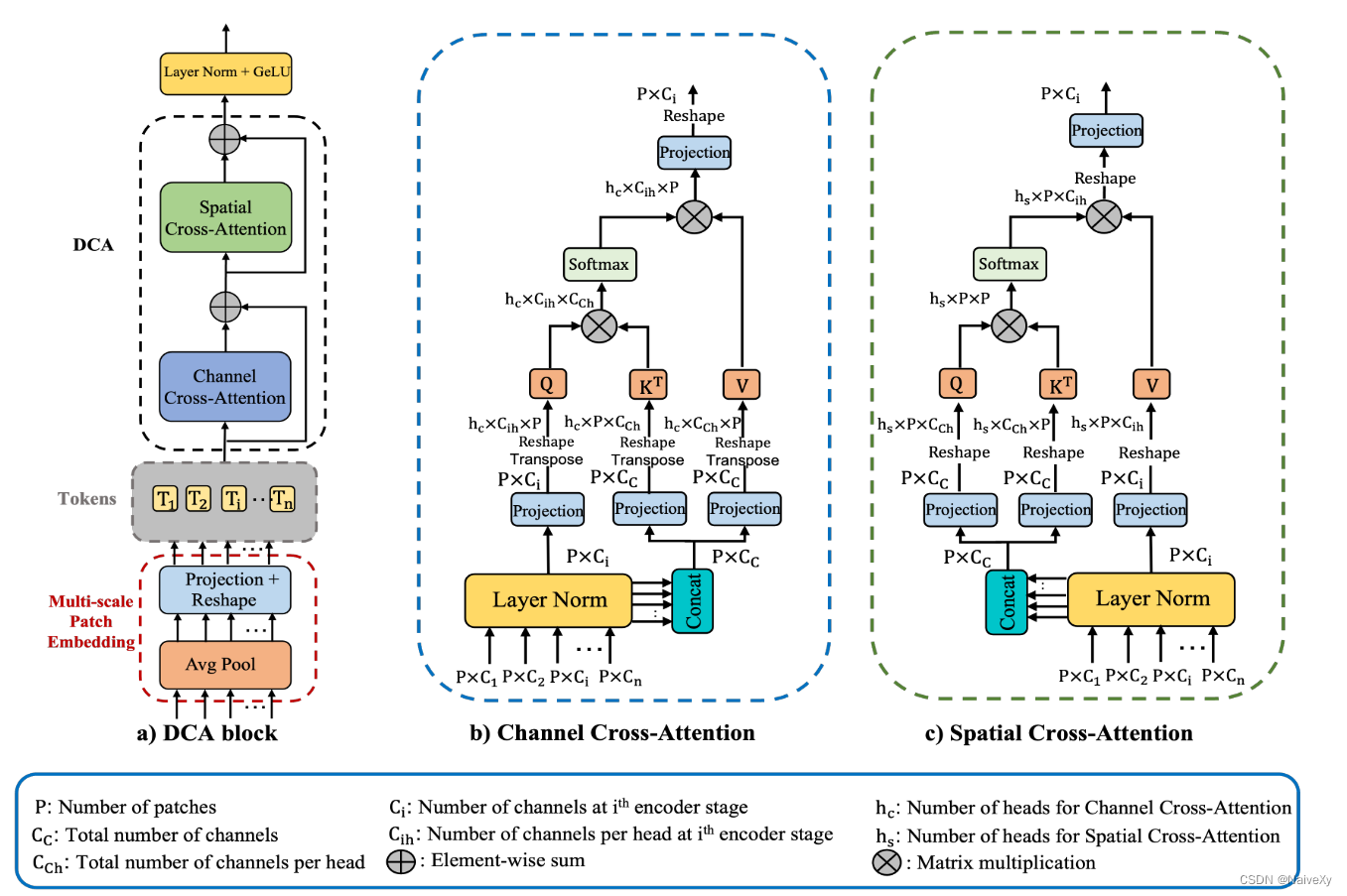
如下图a所示,DCA块分为两个主要阶段:第一阶段由多尺度补丁嵌入模块组成,以获得编码器令牌;在第二阶段,我们使用通道交叉注意(CCA)和空间交叉注意(SCA)模块对这些编码器令牌执行我们提出的DCA机制,以捕获长距离依赖性。最后,我们应用层归一化和GeLU序列并对这些令牌进行上采样,以将它们连接到它们的解码器对应物。
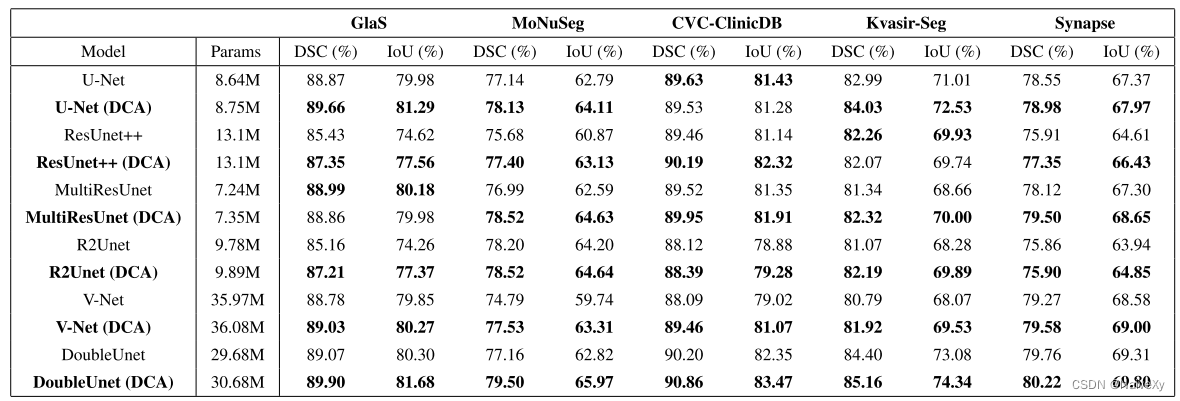
论文对DCA块的有效性进行广泛的实验,使用六个基于U-Net的模型和五个基准的医学图像分割数据集。为了公平比较,对普通模型和DCA集成模型使用相同的训练设置,总体结果见下表:


















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









