



本论文提出了一种全新的无监督三维点云语义分割方法GrowSP。与依赖大量人工标注数据的传统方法不同,GrowSP不需要任何人工标签或预训练模型即可实现高效的语义分割。该方法的核心创新在于通过逐步生长超点(superpoints)的方式来发现语义元素,进而有效地将点云数据分割成具有语义意义的类别。该方法由三大部分构成:特征提取器、超点生长构建器以及一个语义构建模块。
论文题目:GrowSP: Unsupervised Semantic Segmentation of 3D Point Clouds
作者:Zihui Zhang, Bo Yang, Bing Wang, Bo Li
论文地址:http://arxiv.org/abs/2305.16404
代码地址:https://github.com/vLAR-group/GrowSP
1.引言
在过去的几年里,3D点云语义分割技术取得了显著进展,特别是在全监督学习的推动下。许多深度学习模型,如PointNet和SparseConv,已经显著提升了3D点云分割的精度和效率。然而,这些方法依赖于大量的人工标注数据,这对于现实世界中的大规模3D点云数据来说,标注成本非常高且耗时。为了解决这个问题,近年来一些研究开始尝试减少人工标签的需求,探索基于更少标签或者跨领域信息的弱监督学习方法,甚至开始探索完全的自监督学习。
尽管这些方法在一定程度上缓解了标注负担,但依然无法避免人工标注的依赖,尤其是在面对从未见过的新场景时。传统的无监督学习方法虽然在其他领域有所应用,但在3D点云的语义分割任务中,仍面临许多困难:点云数据稀疏且没有统一的结构,使得传统2D方法难以直接迁移。此外,现有的自监督预训练方法虽然能学习到一定的点特征,但缺乏语义上的明确性。
因此,本文提出了一种全新的方法——GrowSP,该方法是一个完全无监督的3D点云语义分割方法。本文方法的贡献主要包括以下三点:
- 针对真实世界点云,首次提出了一个完全无监督的3D语义分割框架,无需人工标注或任何预训练;
- 引入了一种简单的superpoints扩张策略,引导网络逐渐学习高级语义信息;
- 在多个真实3D场景数据集上展示出了有前景的语义分割效果,显著地优于将2D适配到3D的方法和3D自监督预训练方法。

图1.给定来自S3DIS数据集的具有复杂结构的输入点云,GrowSP仅通过逐步增长超点即可自动发现准确的语义类别,在训练过程中无需任何人工标注。
2.方法
2.1 Overview
GrowSP将无监督三维语义分割问题概括为在缺乏人工标注的情况下,联合进行三维点特征学习与聚类。如图2所示,给定包含H个点云的数据集,以单次扫描获得的
点云(包含N个点)作为输入,特征提取器首先会获取每点特征
(嵌入长度K可自由预设,例如K=128)。我们采用强大的稀疏卷积架构作为特征提取器,无需任何预训练步骤。在获得初始无意义的输入点云
及其点特征
后,我们将它们输入超点构造器,通过多轮训练迭代逐步生成规模持续扩大的超点(详见2.2节)。这些超点将被输入语义基元聚类模块,为所有超点生成伪标签(如2.3节所述)。在训练过程中,这些伪标签将用于优化特征提取器。
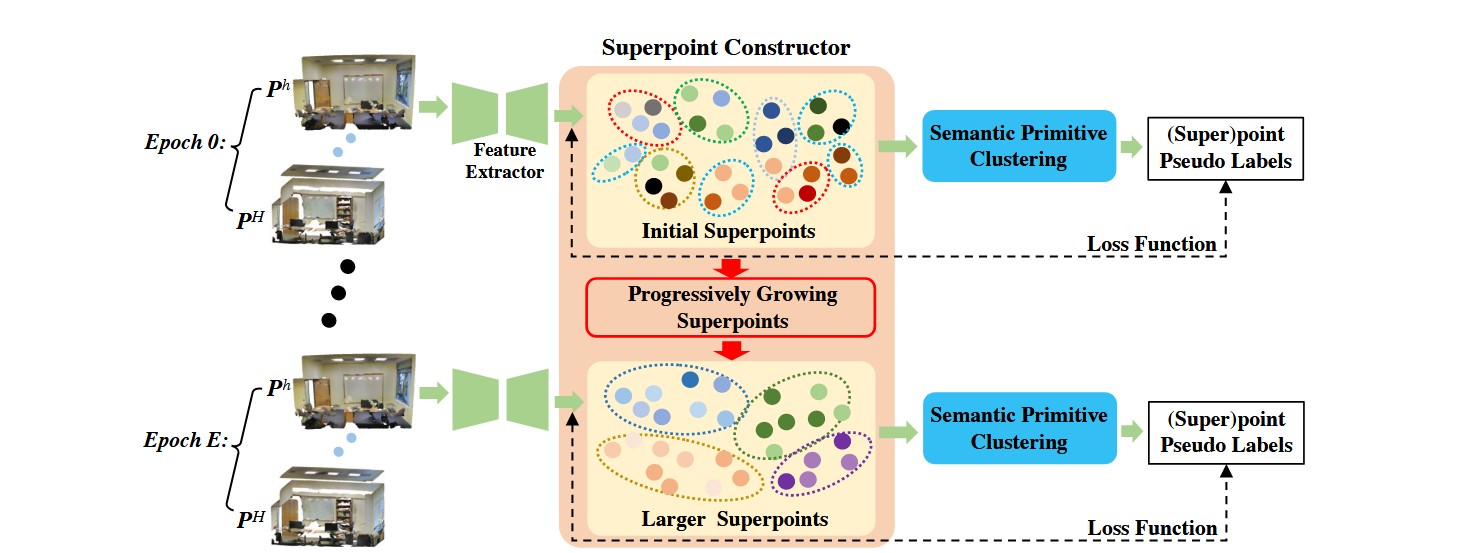
图2.GrowSP的通用学习框架。它主要由三个部分组成:1)特征提取器,用于学习每个点的特征;2)超点构建器,逐步增大超点的尺寸;3)语义基元聚类模块,旨在将超点分组为语义元素。
2.2 Superpoints Constructor
超点构建器是GrowSP的核心模块之一,其主要任务是根据训练过程中的学习动态,逐步生成超点。超点可以看作是由多个3D点组成的更大的数据块,每个超点代表了点云中具有相似语义的区域。GrowSP通过逐步扩大超点的大小,逐渐让每个超点包含更多具有相似特征的点。具体来说,在训练初期,超点构建器通过经典的几何方法(如表面法线和点间连通性)生成初始的超点。随着训练的进行,超点的大小会逐渐增大,以便从更多的点集中学习到更丰富的语义信息。这种逐步生长超点的策略使得GrowSP能够从较小的局部区域逐渐扩大视野,从而捕捉到更大的语义单元。
该模块首先需要构建初始超点, 用于在训练初期引导网络的学习。本文结合了两种方法来进行初始超点的确定:VCCS和Region Growing,这两种算法共同考虑了三维点之间的空间距离、法向量距离和归一化RGB距离。对于特定输入点云,其初始超点表示为
![]() ,其中每个超点
,其中每个超点![]() 由原始点云
由原始点云的一个小子集构成。需要注意的是,不同点云的初始超点数量
通常各不相同。如图3所示:
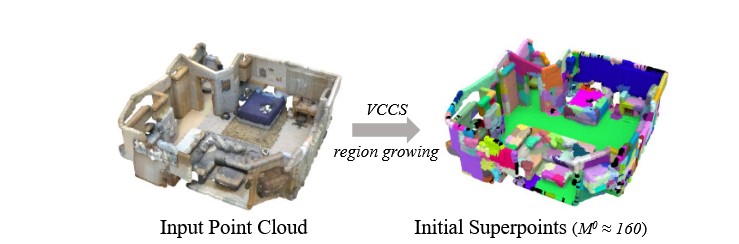
图3. 由VCCS和区域生长构建的初始超点示例。每个彩色块代表一个超点
在确定初始超点之后,需要在在训练过程中逐步增长超点来构建更大的超点以供后续训练。对于一个特定的输入点云,我们有它的神经特征
和初始超点
![]() 。首先计算初始超点的平均神经特征。
。首先计算初始超点的平均神经特征。
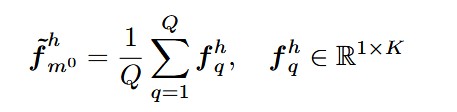
其次,在获得这些初始的超点特征后,我们简单地使用K均值算法将个向量分组为
个簇,其中
<
。每个簇代表一个新的、更大的超点。这样我们得到了新的超点。

每经过一定数量的训练轮次(即一轮),我们将通过重复上述两个步骤来计算下一级更大的超点。给定T级生长,输入点云的超点数量将从→
→
逐渐减少,直到达到一个较小的值
。在每个轮次中,整个数据集的所有超点都将输入到语义基元聚类模块中。
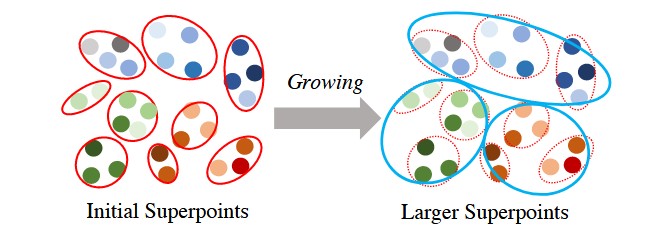
图4. 超点增长示意图
每个点代表一个3D点的神经嵌入,红色圆圈表示初始超点。
蓝色圆圈则表示通过吸收一个或多个初始超点形成的更大超点。
2.3 Semantic Primitive Clustering
在每个训练周期中,每个输入点云会生成若干超点,每个超点代表物体或场景的特定组成部分。对整个数据集而言,所有超点可视为一个庞大的基础语义元素集合,例如椅背、桌面等。为了从这些超点中发掘语义信息,需要解决两个关键问题。
- 如何有效分组这些超点?直接的方法是使用现有聚类算法将所有超点直接划分为若干物体类别。然而,我们通过实验发现这种做法过于激进,因为在训练初期,许多属于不同类别的超点特征相似,会被错误归入同一语义组,且后期难以修正。因此,我们选择在整个训练周期中始终将超点划分为相对较多的聚类簇。
- 超点的神经特征是否足以支撑语义聚类?考虑到网络训练初期,3D点及超点的神经特征尚未具备意义,更可靠的做法是显式结合点云几何特征(如表面法线分布)来增强超点的区分度。为此,我们为每个超点简单拼接其神经特征与经典PFH特征作为聚类依据。
2.4 Implementation
训练阶段:GrowSP在训练时不需要给定实际的语义类别数量,因为GrowSP仅学习语义基元。
测试阶段:一旦网络训练完成,我们保留在训练集上通过K-means估计的S个语义基元的中心点。在测试时,这些中心点通过K-means直接分组为C个语义类别。新获得的C个类别的中心点将作为最终的分类器。给定一个测试点云,所有逐点的神经特征直接被分类为C个类别之一,无需再构建超点。
由于本文以完全无监督的方式进行语义分割,所产生的类别标签只能用于区分不同的类,而和ground truth的标签序号不一致,因此,最终评估时使用匈牙利算法将预测类别与真实标签进行匹配。
3.实验
为了验证算法可行性,本文在两个常用的室内数据集S3DIS,ScanNet和一个室外数据集SemanticKITTI上评估了算法性能。
3.1 Evaluation on S3DIS
本文首先在S3DIS上与baselines进行了比较,选择了适配2D无监督语义分割算法PICIE和IIC到3D点云场景,以及对原始点云信息进行K-means聚类三种作为baselines。本文方法都要优于上述baselines,并且在Area5上取得了非常接近全监督训练的PointNet的效果。
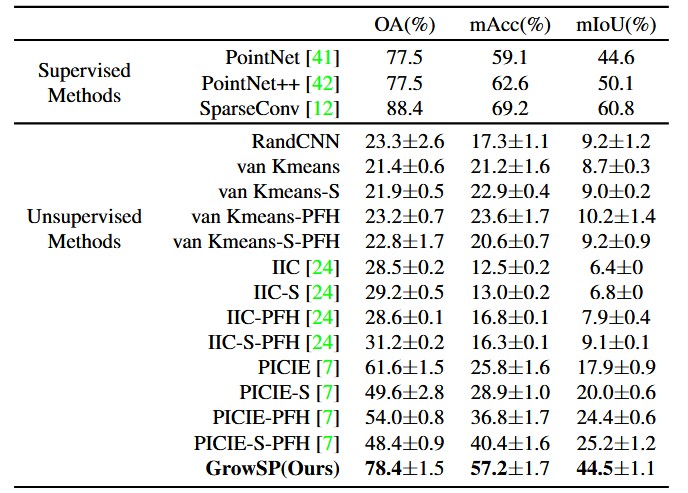
表1.S3DIS-Area5数值结果对比
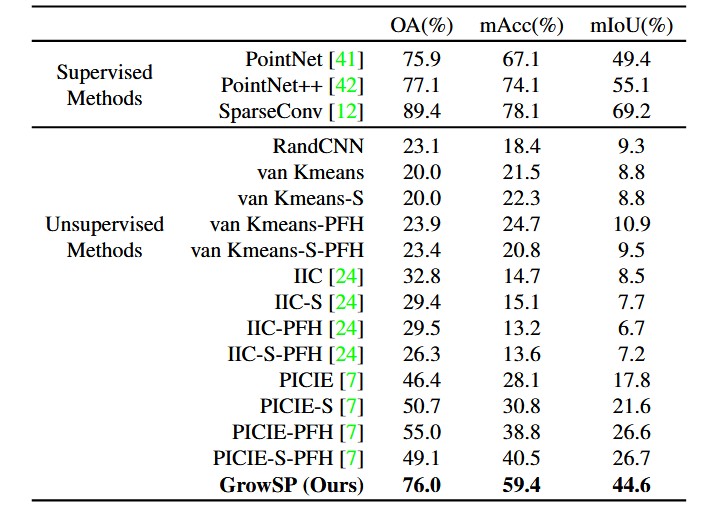
表2: S3DIS 6-fold交叉验证结果对比
3.2 Evaluation on ScanNet
本文也评估了在ScanNet数据集上的表现。如表3&4所示,ScanNet上也大幅超越baselines。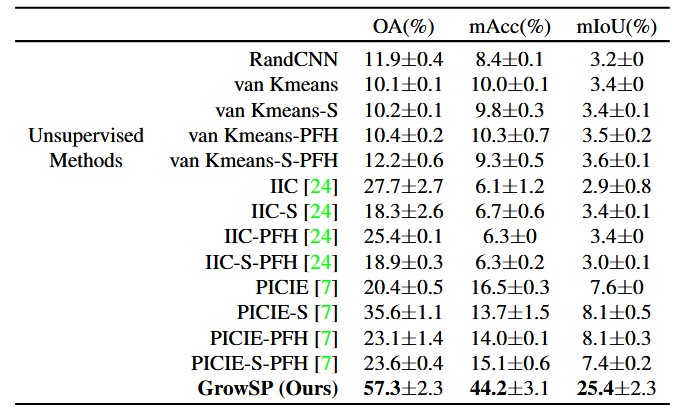
表3: ScanNet验证集数值结果对比
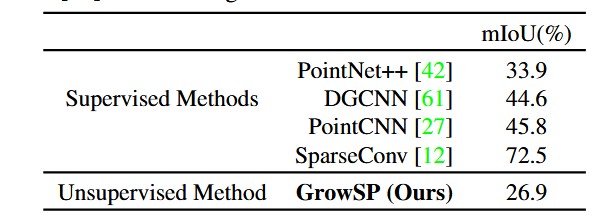
表4: ScanNet在线测试集数值结果对比
3.3 Evaluation on SemanticKITTI
随后本文评估了GrowSP在室外数据集SemanticKITTI上的表现,由于LiDAR数据的疏密不均问题,构建superpoints会比室内困难,最终还是取得了接近全监督PointNet的结果。
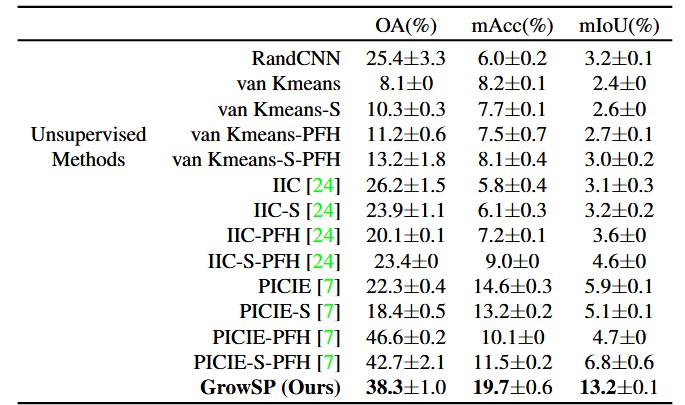
表5:SemanticKITTI验证集数值对比
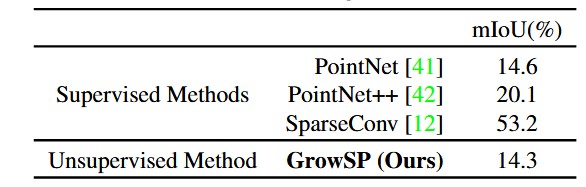
表6:SemanticKITTI在线测试集数值对比
3.4 Ablation Study
本文通过一系列的消融实验来评估GrowSP框架中每个组成部分的重要性,并进一步验证各模块对整体性能的贡献。分别去除了超点构建器,语义原始聚类模块和几何增强的PFH特征。此外,作者还对初始超点的体素大小、逐步生长超点的参数、以及聚类中语义原始数量(S)等超参数进行了分析。实验结果如表7所示:

表7:消融实验结果
4.结论
总而言之,我们证明通过纯无监督方法可以从现实世界的点云数据中自动发现多个3D语义类别。通过采用渐进式增长策略逐步生成越来越大的超点,我们的方法能够成功学习到有意义的语义元素。大量实验验证了我们方法的有效性。


















 2779
2779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









