



论文题目:Position-aware Guided Point Cloud Completion with CLIP Model
发表会议:AAAI 2025 (Association for the Advancement of Artificial Intelligence)
作者: Feng Zhou1, Qi Zhang1, Ju Dai2*, Lei Li3,4, Qing Fan5, Junliang Xing6
地址:https://arxiv.org/abs/2412.08271
1. 引言:几何推断的尽头是语义
在 3D 视觉领域,点云补全(Point Cloud Completion)一直是连接感知与应用的桥梁。然而,受限于传感器(如 LiDAR)的视角和遮挡,我们获取的数据往往是残缺不全的。
1. 现有挑战:几何信息的“盲猜”
主流的补全算法(如 PCN, PoinTr, SeedFormer)通常遵循“几何推断”的范式:通过观察现有的点,利用局部几何的相关性去预测缺失的点。
痛点:这种方法在缺失较少时有效,但在极端缺失情况下(例如:一把椅子只剩下靠背,底座完全消失),几何方法就失效了。因为从纯几何角度看,那一团点可能是一个屏风,也可能是一扇门。
核心矛盾:模型不知道“这是什么(What)”,所以它不知道该“补在哪里(Where)”。只有引入语义(Semantics)——即告诉模型“这是一把椅子”,它才能根据先验知识合理地补出四条腿。
2. 破局思路:CLIP 大模型的跨界援助
既然 3D 数据稀缺且语义匮乏,为何不借用 2D 领域的“最强大脑”? 本论文的核心思想非常直接:利用预训练的 CLIP 模型(Contrastive Language-Image Pre-training)作为语义导师。 通过将残缺点云转化为深度图和文本标签,利用 CLIP 强大的跨模态对齐能力,为 3D 网络注入丰富的语义先验,指导模型从“盲猜”进化为“有识之士”。
2. 模型架构详解
该模型的架构设计跳出了传统“Encoder-Decoder”的单一维度,构建了一个 “三流合一(Tri-stream)” 的多模态融合框架。
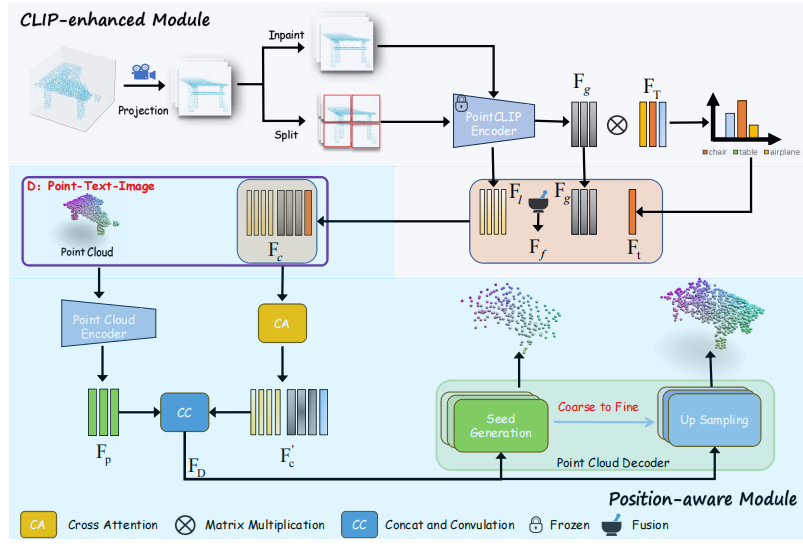
图 1:我们方法的整体架构由两个主要部分组成:CLIP 增强模块(CLIP-enhanced module)和位置感知模块(Position-aware module)。
• 在 CLIP 增强模块中FgF_gFg、FlF_lFl、FTF_TFT 和 FtF_tFt分别表示:全局尺度特征、局部尺度特征、来自 CLIP 的文本特征以及处理后的文本特征(即处理后的 )。
•FcF_cFc、Fc′F'_cFc′、FpF_pFp 和 FDF_DFD 分别表示:CLIP 特征、处理后的 CLIP 特征、点云特征以及输入(馈入)解码器的融合特征。。
2.1整体流程:多模态特征提取
模型的输入被分为三条并行支路,分别提取不同维度的特征:
视觉流 (Visual Branch):六视图正交投影:
为了全方位捕捉 3D 信息,模型并没有使用随机视角的截图,而是采用了严格的 6 视图正交投影 (6 Orthogonal Projections)。
操作:将残缺点云的 (x,y,z)(x, y, z)(x,y,z) 坐标投影到立方体的 6 个面上,并将深度值归一化为像素值,得到 6 张深度图像 I={I1,...,I6}I = \{I_1, ..., I_6\}I={I1,...,I6} 10。
特征提取:利用 6 个共享参数的 CLIP Image Encoder 并行处理这 6 张图像,提取特征后进行拼接。这意味着模型拥有了围绕物体的“全景语义视角” 。
文本流 (Text Branch):语言的指引:
Prompt Engineering:作者并没有只用单词(如 “Chair”),而是构建了更具描述性的 Prompt,例如 “A partial point cloud of a [CLASS]” 或 “A 3D model of a [CLASS]”。
特征提取:输入冻结参数的 CLIP Text Encoder。
作用:提供类别级的强先验。即使图像模糊不清,文本也能告诉网络:“别猜了,这肯定是一架飞机”,从而约束生成形状的拓扑结构。
几何流 (Geometry Branch):本体特征:
使用轻量级的点云编码器(基于 Transformer 或 PointNet++)提取残缺点云的原始几何特征。这是补全任务的“骨架”。
这三股信息流最终通过 Cross-Attention 机制汇聚,让几何特征去“查询”CLIP 中的语义知识。
2.2 核心创新:位置感知模块 (Position-Aware Module, PAM)
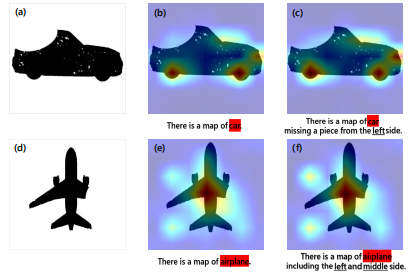
图 2:我们设计位置感知模块的出发点如下:(a) 一张从残缺汽车点云投影得到的投影图像;(b) 文本“这是一张汽车的图”与投影图之间的相关性;© 文本“这是一张左侧缺了一块的汽车图”与投影图之间的相关性。(d) 一张源自残缺飞机点云的投影图。为了阐明文本在捕捉缺失部分方面的潜在局限性,我们提供了 (e) 和 (f) 进行公平的对比 。
失败的尝试:为什么“告诉”模型位置没用?
在介绍最终架构之前,非常有必要提一下作者在探索阶段的一次失败尝试,这直接导向了核心模块 PAM 的诞生。
为了解决补全位置的问题,作者最初的想法非常直观:既然缺了某个角,我能不能直接写在 Prompt 里告诉 CLIP? 他们尝试设计了带有位置信息的文本,例如:
“The projection of this chair is missing a piece in the Top Right corner.” (这把椅子的投影在右上角缺了一块)
然而,通过可视化注意力热力图(Attention Map),作者惊讶地发现:CLIP 根本“听不懂”位置指令
即便文本里强调了“Left Side Missing”,CLIP 关注的图像区域依然是发散的,并没有聚焦到缺失部位 。
结论:CLIP 的文本编码器对空间位置极不敏感。单纯靠 Prompt Engineering 无法解决 3D 补全中的定位问题,必须从视觉和几何层面设计专门的位置感知机制
鉴于“文本引导位置”的失败,作者设计了 PAM 模块,从视觉特征内部解决空间对齐问题。
1. 分块与自适应权重 (Block Division & Adaptive Weights)
为了让 CLIP 特征具有局部感知能力,作者参考了细粒度视觉任务的做法:
分块:将投影得到的深度图像切分为 2×22 \times 22×2 的非重叠块(Blocks) 。
学习机制:模型在训练中学习每个块的权重参数。这使得网络能够区分哪些块是“空的”(缺失部分),哪些块是“实的”(现有部分),从而提取出具有位置信息的局部特征 FlF_lFl 。
2. 全局“脑补”引导 (Inpainting for Global Guidance)
仅仅知道局部哪里缺了还不够,还需要知道“缺了的部分原本长什么样”。
Inpainting:作者引入了一个图像修复网络(Inpainting Network, Nazeri et al.),对残缺的投影图进行预处理,生成一张完整的幻觉图像 。
特征融合:将这张“脑补”出的完整图像特征作为 Global Feature (FgF_gFg),去指导上述的 Local Feature (FlF_lFl)。Cross-Attention:通过 Cross-Attention 机制,让局部特征查询全局特征,最终生成这就既包含细节位置、又包含完整形状语义的融合特征 FfF_fFf 。
这一步实际上是用数学手段强制 CLIP 的语义特征与 3D 空间坐标进行“硬绑定”,填补了 CLIP 这种 2D 图文模型在空间感知上的天然缺陷。
3. 实验结果与分析 (Experiments)
作者在 PCN 和 MVP 数据集上进行了广泛测试,并基于新提出的方法构建了 PCN-TI 和 MVP-TI(包含文本-图像-点云三元组)数据集 。
3.1 定量分析:全面超越 SOTA
在 PCN 数据集上,该方法在 Chamfer Distance (CD) 指标上取得了最佳性能,特别是在 Lamp (灯具) 和 Chair (椅子) 等结构复杂的类别上提升显著 。
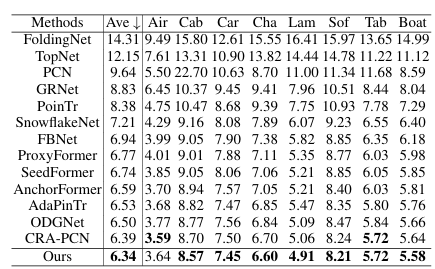
表1:基于L1 CD × 10^3(数值越小越好)的 PCN 数据集结果(采用 SOTA 方法)。
鲁棒性:在对比 PoinTr, SnowflakeNet, CRA-PCN 等强力 Baseline 时,加入该模块均带来了性能提升 。

表2:作者在 KITTI 自动驾驶数据集上进行了测试。KITTI 是真实的激光雷达扫描数据,相比于合成数据集(PCN),它具有极高的稀疏性和噪声
3.2 视觉效果:细节的胜利
可视化结果显示了语义先验的威力:
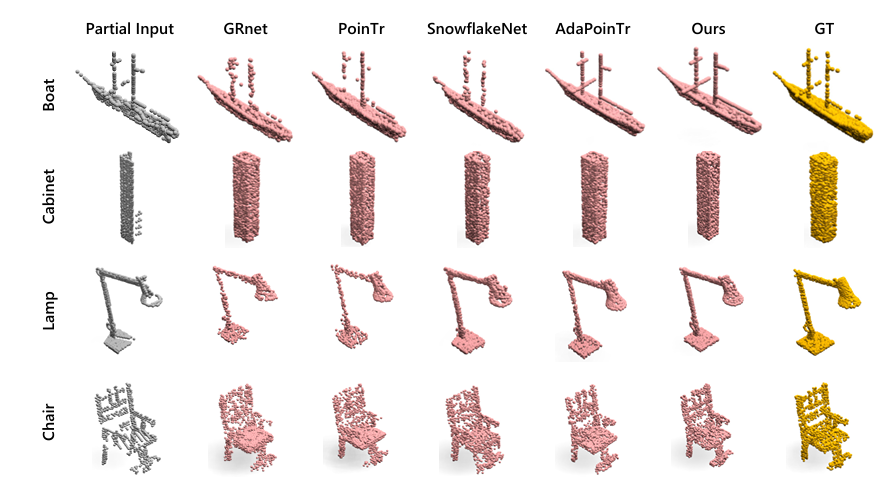
图三:PCN 数据集上的点云补全结果。从左至右依次为:部分输入、GRNet、PoinTr、SnowflakeNet、AdaPoinTr、我们的模型及真实数据。建议以彩色模式查看并放大查看。
椅子靠背:传统方法生成的靠背往往点分布不均,而本方法生成的点云均匀且完整 。
灯具线圈:对于灯具中常丢失的线圈细节,本方法能精准还原,没有出现断裂或噪点 。
3.3 消融实验:缺一不可
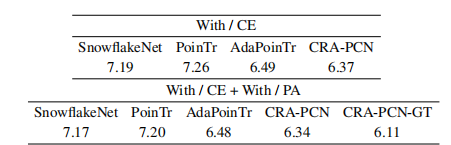
1. 证明了框架的“即插即用”通用性 (Superiority & Generalizability)
现象:表格列出了四个不同的基线模型(Baselines):SnowflakeNet, PoinTr, AdaPoinTr, CRA-PCN 。
结论:作者将提出的两个模块(CE 和 PA)分别加到这四个完全不同的网络架构上,结果显示所有模型的误差(L1 CD)都下降了(数值越低越好)。
意义:这证明了作者提出的 CLIP 增强策略不是只能用在特定模型上的“特调补丁”,而是一个通用的框架,可以像插件一样提升各种现有 SOTA 模型的性能 。
2. 验证了位置感知模块 (PA) 的必要性
现象:表格分为上下两部分。
上半部分 (With / CE):只加了 CLIP 增强模块。
下半部分 (With / CE + With / PA):同时加了 CLIP 增强模块 和 位置感知模块。
对比:对比上下两行数据,例如 CRA-PCN 模型:
只加 CE 时,误差是 6.37。
加上 PA 后,误差进一步降到了 6.34 。
结论:这直接证明了 Position-Aware (PA) 模块是有效的。单纯引入 CLIP (CE) 虽然有用,但配合 PA 模块解决“位置对齐”问题后,性能会进一步提升 。
4. 总结与思考
这篇 AAAI 2025 的工作为我们展示了 Small Setup, Big Impact 的设计哲学:
极简文本:证明了不需要复杂的 LLM,简单的 Prompt 就能激活语义 。
几何先验:证明了 6 视图投影 + 分块机制 是解决 2D-3D 空间对齐的高效手段
对开发者的启示:
拥抱多模态:纯几何的深度学习已接近天花板,引入 Image/Text/Video 等跨模态信息是突破瓶颈的关键。
关注对齐技术:如何将 2D 基础模型的强大能力无损地迁移到 3D 任务(即解决 Position-Aware 问题),将是未来两年的核心研究热点。

















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









