




论文题目:Intent-Guided Reasoning for Sequential Recommendation
作者:Yifan Shao, Peilin Zhou (香港中文大学)
发布时间:2025 (arXiv:2512.14034) https://arxiv.org/pdf/2512.14034
关键词:序列推荐、推理时计算 (Inference-time Reasoning)、意图解耦、对比学习
1. 引言:现有“推理式推荐”的困境
序列推荐(Sequential Recommendation, SR)的核心挑战在于从用户历史交互中捕捉动态变化的偏好。近年来,受到大语言模型(LLM)中 Chain-of-Thought (CoT) 的启发,研究者们开始探索“推理增强(Reasoning-enhanced)”的推荐范式(如 ReaRec, LARES)。
与直接将历史行为映射为预测结果的传统方法(如 SASRec)不同,推理增强模型试图模拟一个“深思熟虑”的过程,生成中间推理步骤。然而,作者指出这种范式存在两个核心痛点:
- 推理不稳定性 (Reasoning Instability):
现有的推理过程仅由“下一个目标物品”作为监督信号。这使得推理过程对近期的交互极其敏感。例如,用户的一次误触(Accidental Click)可能导致推理路径发生剧烈偏移,从而产生错误的推荐。 - 表层推理 (Surface-level Reasoning):
模型往往只是死记硬背了物品间的跳转概率(例如“买了A之后大概率买B”),而没有真正理解行为背后的内在意图(例如“用户正在探索户外活动”)。这种推理缺乏泛化能力,难以应对复杂的行为模式。
为了解决上述问题,本文提出了 IGR-SR (Intent-Guided Reasoning for Sequential Recommendation)。其核心思想是:显式提取高层的用户意图(High-level Intents),并将其作为锚点来引导每一步的推理过程。
2. 模型架构详解 (Methodology)
IGR-SR 的整体架构如下图所示,包含三个核心组件:潜在意图蒸馏器 (LID)、意图感知审慎推理机 (IDR) 以及 意图一致性正则化 (ICR)。
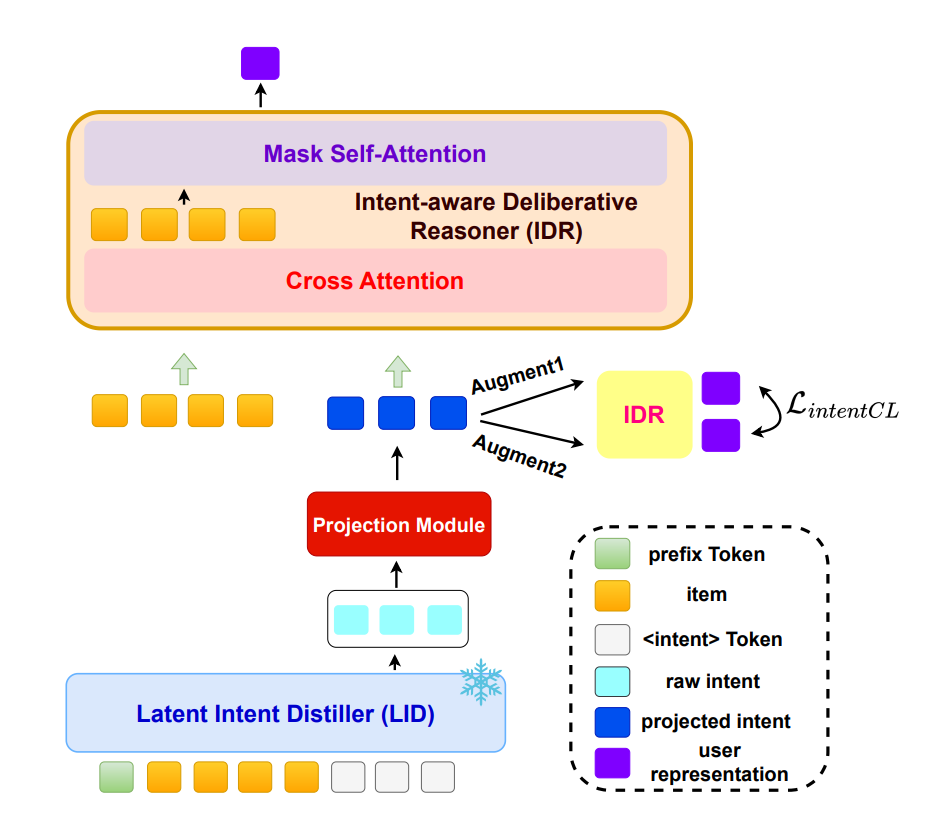
图 1:模型首先通过冻结参数的 LID 提取意图 Token,经过 MLP 投影后,输入到 IDR 中进行双阶段推理(Cross-Attention 融合意图 + Self-Attention 序列建模),最后辅以对比学习损失。
2.1 潜在意图蒸馏器 (Latent Intent Distiller, LID)
如何在不引入巨大计算开销的前提下提取用户意图?作者借鉴了 LLM 中的 Prompt Tuning 和 SoftCoT 技术,设计了一个轻量级的蒸馏模块。
-
输入序列构建:
为了激发预训练模型提取意图的能力,作者在原始用户序列 S u S^u Su 的前端添加 k k k 个可学习的 Prefix Tokens ( P P P),在末端添加 m m m 个<intent>Tokens ( I I I):
S a u g u = Concat ( P , S u , I ) S_{aug}^{u} = \text{Concat}(P, S^{u}, I) Saugu=Concat(P,Su,I)
其中 P P P 充当任务特定的指令(Instruction),引导模型关注意图信息; I I I 则作为意图信息的聚合容器。 -
冻结编码器 (Frozen Encoder):
将 S a u g u S_{aug}^{u} Saugu 输入到一个预训练好且参数冻结的 SASRec 编码器中。
H 1 = LID ( S a u g u ) H_1 = \text{LID}(S_{aug}^{u}) H1=LID(Saugu)
关键点:在训练过程中,梯度的反向传播只更新 P P P 和 I I I 的 Embedding,编码器参数保持不变。这使得 LID 模块极其高效。 -
意图提取与投影:
最终的意图表示 T I T_I TI 取自序列末尾对应<intent>tokens 的输出状态。为了解决 LID 与主模型(IDR)之间的维度和语义空间差异,引入了一个 MLP 投影层:
T D = f θ ( T I ) ∈ R m × d T_D = f_{\theta}(T_I) \in \mathbb{R}^{m \times d} TD=fθ(TI)∈Rm×d
2.2 意图感知审慎推理机 (Intent-aware Deliberative Reasoner, IDR)
这是模型的主体,负责执行“意图引导”的推理。作者认为,简单的拼接(Concatenation)会导致位置编码污染(Positional Encoding Contamination),因此提出了一种双重注意力架构 (Dual-Attention Architecture),将推理显式解耦为两个阶段。
阶段一:意图审思 (Intent Deliberation)
在此阶段,模型利用全局意图来丰富局部物品的上下文表示。使用 Cross-Attention 机制,让序列中的每个 item 动态“检索”相关的意图信息:
- Query ( Q Q Q): 上一层的序列表示 H ( l − 1 ) H^{(l-1)} H(l−1)
- Key ( K K K) / Value ( V V V): 投影后的意图向量 T D T_D TD
H
c
r
o
s
s
(
l
)
=
H
(
l
−
1
)
+
CrossAttn
(
Q
=
H
(
l
−
1
)
,
K
=
T
D
,
V
=
T
D
)
H_{cross}^{(l)} = H^{(l-1)} + \text{CrossAttn}(Q=H^{(l-1)}, K=T_D, V=T_D)
Hcross(l)=H(l−1)+CrossAttn(Q=H(l−1),K=TD,V=TD)
通过这种方式,模型能够根据当前的上下文,有选择性地吸收最相关的全局意图,从而纠正局部的噪声偏差。
阶段二:决策制定 (Decision-Making)
在融合了意图信息后,模型回归到经典的序列建模任务。使用标准的 Masked Self-Attention 来捕捉序列内部的时间依赖性:
H
s
e
l
f
(
l
)
=
H
c
r
o
s
s
(
l
)
+
MaskedSelfAttn
(
H
c
r
o
s
s
(
l
)
)
H_{self}^{(l)} = H_{cross}^{(l)} + \text{MaskedSelfAttn}(H_{cross}^{(l)})
Hself(l)=Hcross(l)+MaskedSelfAttn(Hcross(l))
最终输出经过前馈网络(FFN)和层归一化(LayerNorm)得到。
2.3 意图一致性正则化 (Intent Consistency Regularization, ICR)
为了增强模型对意图引导的鲁棒性,防止模型“过度依赖”某一个特定的意图维度(可能会导致过拟合),作者引入了基于对比学习的正则化目标。
-
掩码意图增强 (Masked Intent Augmentation):
对投影后的意图向量 T D T_D TD 进行两次独立的随机 Mask(Dropout),生成两个视图 T D ( 1 ) T_D^{(1)} TD(1) 和 T D ( 2 ) T_D^{(2)} TD(2):
T D ( 1 ) = T D ⊙ M ( 1 ) , T D ( 2 ) = T D ⊙ M ( 2 ) T_D^{(1)} = T_D \odot M^{(1)}, \quad T_D^{(2)} = T_D \odot M^{(2)} TD(1)=TD⊙M(1),TD(2)=TD⊙M(2)
其中 M M M 是服从伯努利分布的掩码矩阵。 -
对比损失 (InfoNCE Loss):
将这两个视图分别输入 IDR,得到两个用户表示 h u ( 1 ) h_u^{(1)} hu(1) 和 h u ( 2 ) h_u^{(2)} hu(2)。目标是最大化同一用户在不同掩码视图下的一致性:
L IntentCL = − log exp ( sim ( h u ( 1 ) , h u ( 2 ) ) / τ ) ∑ v ∈ U exp ( sim ( h u ( 1 ) , h v ( 2 ) ) / τ ) \mathcal{L}_{\text{IntentCL}} = -\log \frac{\exp(\text{sim}(h_u^{(1)}, h_u^{(2)}) / \tau)}{\sum_{v \in \mathcal{U}} \exp(\text{sim}(h_u^{(1)}, h_v^{(2)}) / \tau)} LIntentCL=−log∑v∈Uexp(sim(hu(1),hv(2))/τ)exp(sim(hu(1),hu(2))/τ)
最终的总损失由推荐任务损失(Cross-Entropy)和对比学习损失加权求和而成。
3. 实验结果与深度分析 (Experiments)
3.1 核心性能对比 (Main Results)
实验在 Toys, Instrument, CDs_and_Vinyl 三个亚马逊数据集上进行。
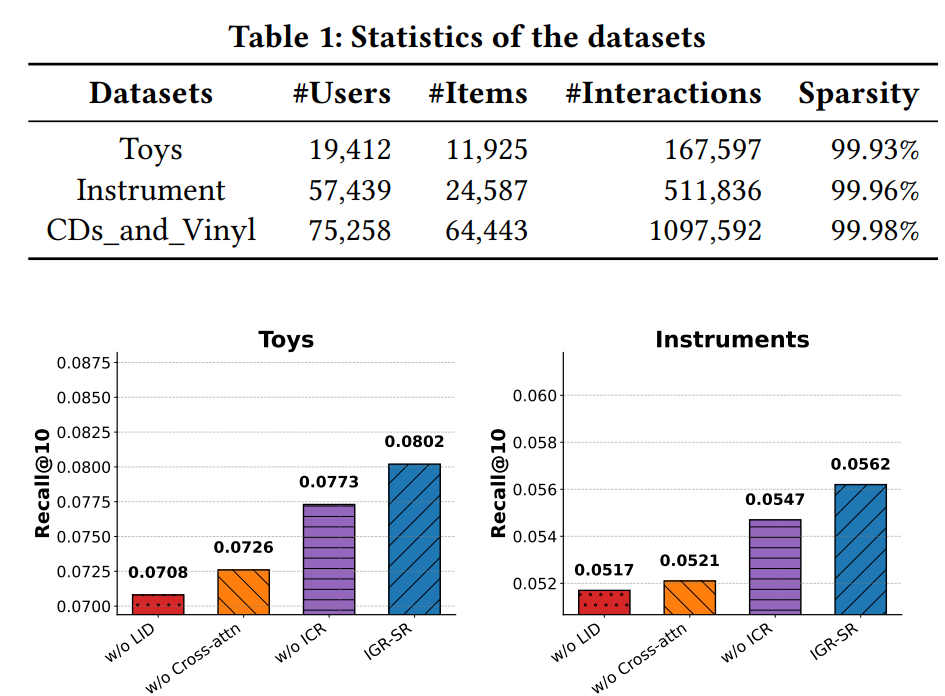
主要对比结果如下表所示(Recall@10):
| 模型类别 | 模型名称 | Toys | Instrument | CDs_and_Vinyl |
|---|---|---|---|---|
| 基础模型 | SASRec | 0.0708 | 0.0517 | 0.0855 |
| 推理增强 | ReaRec | 0.0723 | 0.0531 | 0.0852 |
| 本文模型 | IGR-SR | 0.0802 | 0.0562 | 0.0921 |
| 提升幅度 | vs. Best Baseline | +10.9% | +5.8% | +5.4% |
分析:
- 推理有效:ReaRec 和 LARES 等推理增强方法普遍优于基础的 SASRec,证明了“Think-before-action”范式的有效性。
- 引导更关键:IGR-SR 显著超越了 ReaRec,说明仅仅引入推理步骤是不够的,必须要有高层的意图作为锚点,才能发挥推理的最大潜力。
3.2 鲁棒性分析:对抗噪声 (Noise Robustness)
作者通过随机替换 20% 的历史交互来模拟真实场景中的“误触”或噪声行为。结果极具说服力:
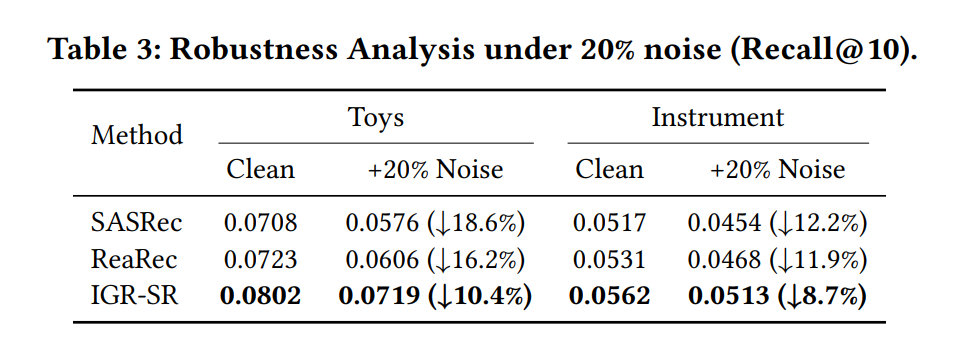
- SASRec 性能下降了 18.6% (Toys 数据集)。
- ReaRec 性能下降了 16.2%,说明未受引导的推理依然对噪声敏感。
- IGR-SR 性能仅下降了 10.4%。
这证明了 IGR-SR 提取的意图具有很强的稳定性,能够帮助模型识别并忽略序列中的虚假动作(Spurious Actions)。
3.3 参数敏感性分析 (Hyperparameter Sensitivity)
作者还研究了 LID 中 Prefix Tokens (
k
k
k) 和 <intent> Tokens (
m
m
m) 数量对性能的影响(如下图):
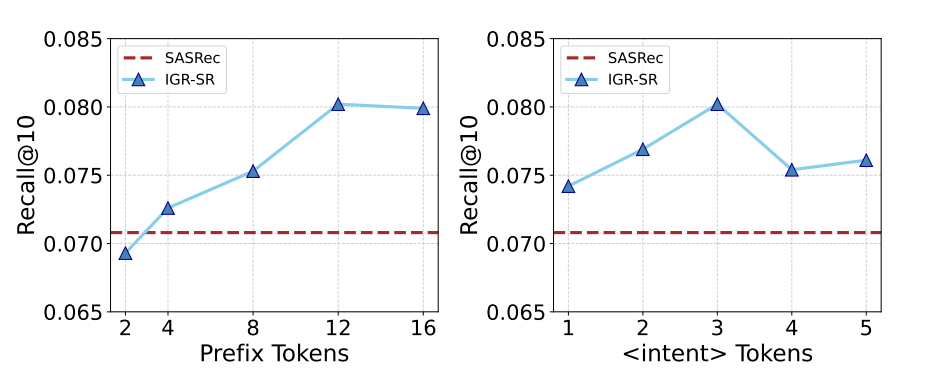
- Prefix Tokens ( k k k):当 k k k 从 2 增加到 12 时,性能稳步提升。这说明更多的 Prefix 能提供更丰富的上下文指令,帮助冻结的编码器更好地理解任务。但超过 12 后性能趋于饱和。
- Intent Tokens (
m
m
m):增加
<intent>token 的数量(从 1 到 3)能捕捉更多样化的意图,但过多的意图槽位(如 5 个)可能引入冗余噪声。
4. 总结与展望 (Conclusion)
IGR-SR 提出了一种全新的“意图引导推理”范式,直击当前推理式推荐系统“不稳定性”和“表层化”的痛点。
核心创新点回顾:
- LID (蒸馏):利用 Prompt Tuning 思想,低成本地从冻结模型中“榨取”用户意图。
- IDR (双重注意力):巧妙地利用 Cross-Attention 将意图作为 Query 检索对象,实现了全局意图与局部序列的动态融合。
- ICR (正则化):利用对比学习确保意图表示的鲁棒性,防止过拟合。
该工作不仅在性能上刷新了 SOTA,更重要的是为序列推荐提供了一种增强鲁棒性的新思路——在推理之前,先明确意图。

















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









