




GPU结构和通信速度
GPU结构
速度
- Global memory << shared memory < register (local memory)

- share_memory 在chip上,在block中共享
,local memory 在board上 , global_memroy 在板子上


Shared Memory:
- 静态分配:
_ shared__ int s[64]; - 动态分配:
dynamicKernel<<<1, n, n*sizeof(int)>>>(d_ d, n);然后再kernel内部extern __shared__ int s[];
shared-memory 例子
共享内存是按线程块分配的,因此块中的所有线程都可以访问相同的共享内存。线程可以访问由同一线程块内的其他线程从全局内存加载的共享内存中的数据。此功能(与线程同步相结合)有多种用途,例如用户管理的数据缓存、高性能协作并行算法(例如并行缩减),以及在无法实现全局内存合并的情况下促进全局内存合并。可能的。
__global__ void argmax_kernel(float* input, int* output) {
// 共享内存是按线程块分配的,因此块中的所有线程都可以访问相同的共享内存
__shared__ float shared_data[32][32];
shared_data[threadIdx.y][threadIdx.x] = blockIdx.x;
// Synchronize all threads in the block
__syncthreads();
float max_val = shared_data[threadIdx.y][0];
int max_idx = shared_data[0][0];//blockIdx.x;
// Store maximum value index in global memory
if (threadIdx.x == 0) {
output[blockIdx.x] = max_idx;
}
}
void function_mm(float* c,
int* a,
float* b,
int n) {
dim3 dimBlock(32, 32);
dim3 dimGrid(32, 1);
argmax_kernel<<<dimGrid, dimBlock>>>(b,a);// AFTER a tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31],
}
CG
- http://dlsys.cs.washington.edu/pdf/lecture5.pdf
- CUDA:何时使用共享内存,何时依赖 L1 缓存?
- https://gpgpu.io/2020/01/18/cuda-shared-memory/
- https://www.researchgate.net/figure/Overview-Exemplary-architecture-of-a-system-with-a-graphics-card_fig1_264856041
Tiling
-
英文翻译:平铺;贴砖;瓦面;盖瓦;平铺次数,瓷砖面;地砖面;瓦屋顶
-
矩阵乘法中,Tiling方法将常用数据放在shared memory而非global memory,以降低访问latency。图片来自:https://ecatue.gitlab.io/GPU2016/cookbook/matrix_multiplication_cuda/#4
-
https://www.cstechera.com/2016/03/tiled-matrix-multiplication-using-shared-memory-in-cuda.html
例子
-
一个简单的矩阵乘法例子
A 32 × 32 ∗ B 32 × 32 = C 32 × 32 C i , j = ∑ k A i , k ∗ B k , j ( A 的第 i 行和 B 的第 j 列 ) A_{32\times 32}*B_{32\times 32}=C_{32\times 32}\\ C_{i,j}=\sum_k A_{i,k}*B_{k,j} (A的第i行和B的第j列) A32×32∗B32×32=C32×32Ci,j=k∑Ai,k∗Bk,j(A的第i行和B的第j列) -
一个 C i , j C_{i,j} Ci,j计算的函数和图解如下
/* Codes running on GPU */
__global__ void matrixMul(A_gpu,B_gpu,C_gpu,K){
temp <= 0
i <= blockIdx.y * blockDim.y + threadIdx.y // Row i of matrix C
j <= blockIdx.x * blockDim.x + threadIdx.x // Column j of matrix C
for k = 0 to K-1 do
accu <= accu + A_gpu(i,k) * B_gpu(k,j)
end
C_gpu(i,j) <= accu
}
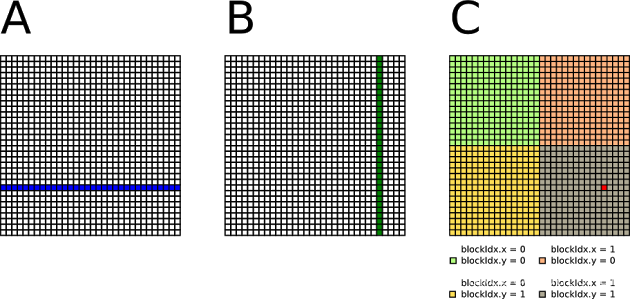
计算的次数
- 总计算量为 2 x 32 x 32 x 32 flop (floating point operation)
dim3 dimBlock(16, 16)
dim3 dimGrid(32/dimBlock.x, 32/dimBlock.y)
matrixMul<<<dimGrid, dimBlock>>>(A_gpu, B_gpu, C_gpu)
-
2 * 2 * 16 * 16个线程,一个线程计算(2 x 32 x 32 x 32)/(221616)=11622 = 32 * 2次,正好对应 C 中一个元素的 2 x 32 次计算 (一次相乘,一次相加)
-
Global memory 总访问量为 2 x 32 x 32 x 32。上述矩阵运算整个过程中对矩阵 A 和 矩阵 B 中的每一个元素都访问了 32 次。
-
可以将数据放在shared memory而非global memory,但是shared memory一般几十kb大小,所以用以下的分片方法计算。
-
该图显示了一个 32 x 32 矩阵,分为四个 16 x 16 块。为了计算这个,可以创建四个线程块,每个线程块有 16 x 16 个线程。
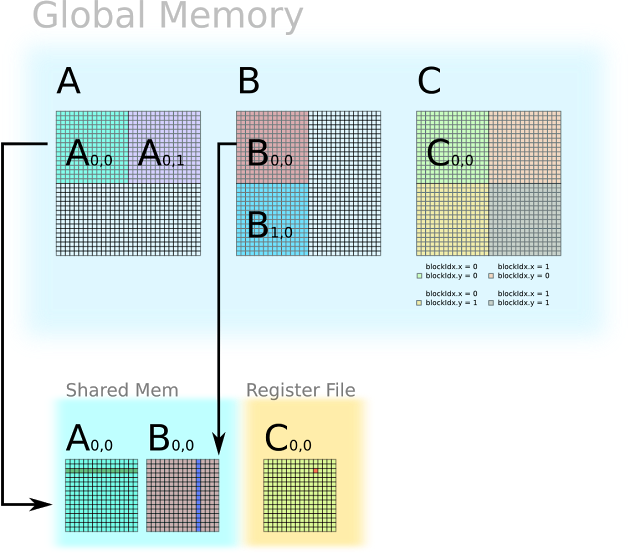
-
得到的代码如下:
/* Codes running on GPU */
__global__ void matrixMul(A_gpu,B_gpu,C_gpu,K){// A_gpu、B_gpu和C_gpu是指向在设备上分配的内存空间的指针,用于存储输入和输出矩阵的数据;K表示矩阵维度。
__shared__ float A_tile(blockDim.y, blockDim.x)//共享内存数组,用于存储每个线程块中的部分输入矩阵A的数据。blockDim.y和blockDim.x表示线程块的维度。
__shared__ float B_tile(blockDim.x, blockDim.y)//共享内存数组,用于存储每个线程块中的部分输入矩阵B的数据。它的维度与A_tile相反,以便进行矩阵乘法时的正确访问。
accu <= 0 // 定义一个变量accu,并将其初始化为0,用于累积计算结果
/* Accumulate C tile by tile. */
//循环遍历所有的矩阵块。tileIdx表示当前处理的矩阵块的索引,K/blockDim.x表示矩阵块的数量。
for tileIdx = 0 to (K/blockDim.x - 1) do
/* Load one tile of A and one tile of B into shared mem */
// Row i of matrix A 计算当前线程处理的元素在矩阵C中的行索引。blockIdx.y * blockDim.y表示线程块的起始行索引,threadIdx.y表示线程在线程块中的行索引。
i <= blockIdx.y * blockDim.y + threadIdx.y
// Column j of matrix A 计算当前线程处理的元素在矩阵C中的列索引。tileIdx * blockDim.x表示当前矩阵块的起始列索引,threadIdx.x表示线程在线程块中的列索引。
j <= tileIdx * blockDim.x + threadIdx.x
// Load A(i,j) to shared mem 将矩阵A中对应位置的元素加载到共享内存数组A_tile中。threadIdx.y和threadIdx.x表示当前线程在线程块中的坐标。
A_tile(threadIdx.y, threadIdx.x) <= A_gpu(i,j)
// Load B(j,i) to shared mem 将矩阵B中对应位置的元素加载到共享内存数组B_tile中。这里的访问是非连续的,可能会导致全局内存访问不规则。
B_tile(threadIdx.x, threadIdx.y) <= B_gpu(j,i) // Global Mem Not coalesced
// Synchronize before computation 在进行计算之前,使用此同步函数确保所有线程都已加载所需的数据。
__sync()
/* Accumulate one tile of C from tiles of A and B in shared mem */
// 循环遍历当前线程块中的所有列,threadDim.x = 16为一个块的线程个数,用于累积计算每个元素的乘积和。
for k = 0 to threadDim.x do
// Accumulate for matrix C 将当前线程在共享内存中加载的A_tile和B_tile的元素进行乘法运算,并将结果累积到变量accu中。
accu <= accu + A_tile(threadIdx.y,k) * B_tile(k,threadIdx.x)
end
// Synchronize在进行下一次矩阵块的计算之前,使用此同步函数确保所有线程都已完成当前矩阵块的计算。
__sync()
end
//将累积的结果存储到输出矩阵C_gpu中的对应位置。
// Row i of matrix C
i <= blockIdx.y * blockDim.y + threadIdx.y
// Column j of matrix C
j <= blockIdx.x * blockDim.x + threadIdx.x
// Store accumulated value to C(i,j)
C_gpu(i,j) <= accu
}
dim3 dimBlock(16, 16)
dim3 dimGrid(32/dimBlock.x, 32/dimBlock.y)
matrixMul<<<dimGrid, dimBlock>>>(A_gpu, B_gpu, C_gpu)
CG
- https://arxiv.org/ftp/arxiv/papers/1001/1001.1718.pdf

















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









