 DeepSeek大模型私有化部署成本解析
DeepSeek大模型私有化部署成本解析




DeepSeek 热度持续,大家都在探索DeepSeek的使用场景,拓宽它的使用边界。在一些数据安全敏感的场景私有化部署是企业落地LLM的重要选项。本文将详细的讨论如何才能高性价比的完成DeepSeek的私有化部署,下面将以两个章节来讨论这个问题:第一章节定义一些大模型服务的性能指标,第二个章节评估私有化部署大模型的成本情况。
一,大模型的性能指标:
我们把评估大模型服务的指标体系分为两类: 一类是系统级别的指标,一类是个人用户体验的指标。
系统级别指标主要评估LLM服务的整体性能,这些指标都和成本相关。
吞吐量(Throughput): 推理服务器每秒可为所有用户和请求生成的输出token数量。吞吐越高则单token成本越低。
并发数(Concurrency) :系统在同一时间正在处理的请求数量,单台设备同一时间能服务的请求越多,单请求的成本越低。
个人用户体验的指标主要评估LLM服务的个人体验情况,可以视做SLO。
首token生成时间(Time To First Token,TTFT):用户提交提示词(prompt)后开始看到模型输出的速度。较短的响应等待时间对于实时交互至关重要,但在离线工作负载中则不那么重要。该指标由处理提示词(prompt)并生成第一个输出令牌所需的时间决定。
单token 生成时间(Time Per Output Token,TPOT):为每个用户生成单个token所需的时间。该指标直接影响用户对模型"速度"的感知。例如,100毫秒/token 的TPOT相当于每秒每个用户生成10个令牌,或约450词/分钟,这比普通人阅读速度更快。
从成本优化的角度看,我们希望吞吐量越大越好,从用户体验的角度看TTFT和TPOT 越小越好。这两个方向往往不能同时达到, 当并发增加时吞吐量提高,但是TPOT也会随之变大。所以实际部署中为了满足一定的TPOT,需要控制系统的并发上限,这个时候的吞吐量就是这个系统不触发SLA情况下能达到的系统吞吐量。
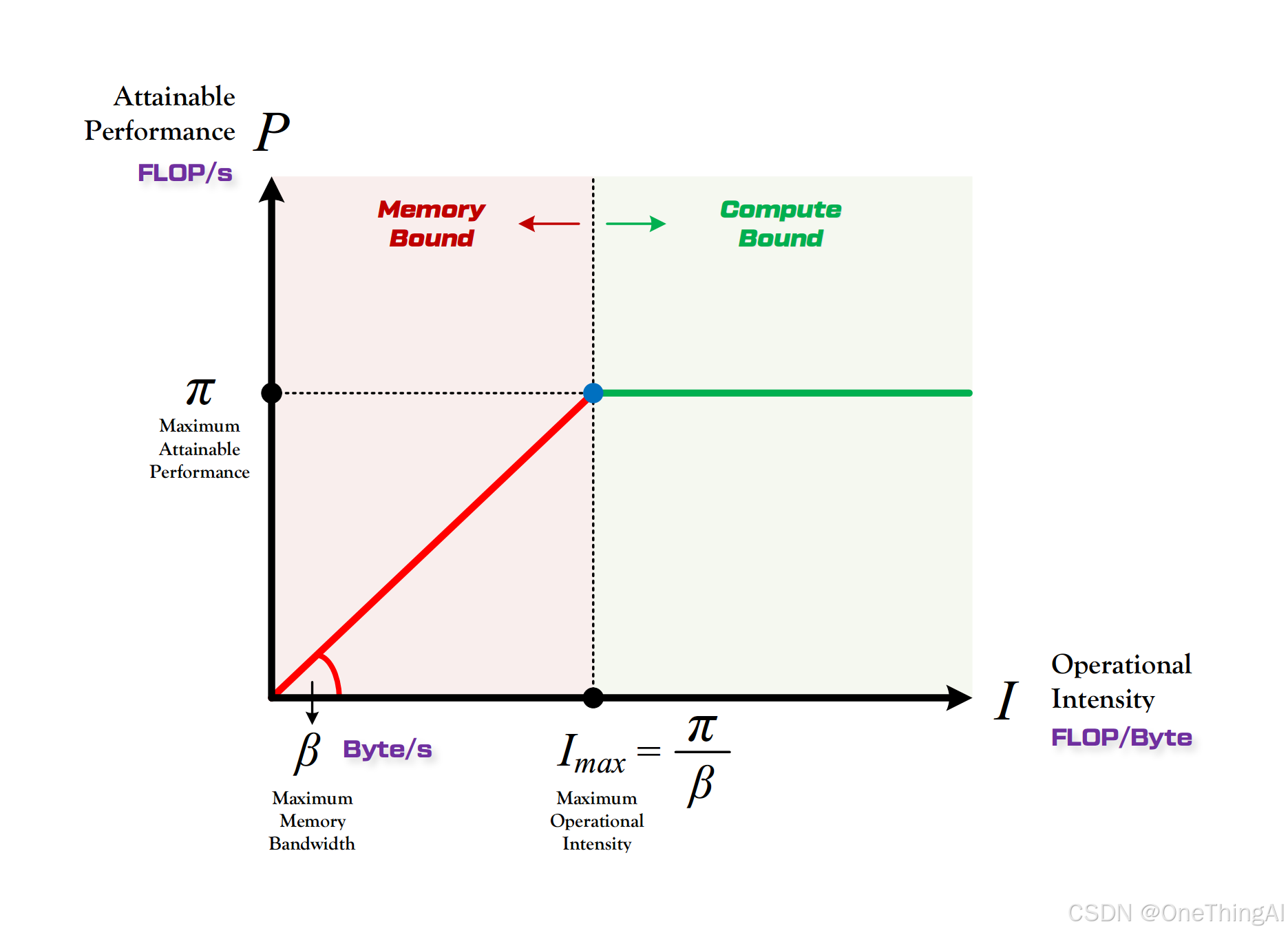
这里的性能分析使用roofline模型进行分析,我们也把roofline的分析指标分为两类:一类是算力平台指标,一类是模型相关的指标。
算力平台的指标主要评估的算力平台处理模型计算任务的能力,这些指标和系统瓶颈在哪里相关
算力 π :为GPU一秒可以完成的浮点数计算量,是计算平台的性能上限,如 H100 FP16 是 989 FLOP/s
带宽 β :为GPU一秒最大可以完成的内存交换量,是计算平台的带宽上限。如H100 是3.35 TB/s
计算强度上限 Imax :GPU上单位内存交换最多可以完成多少次运算,以上两个指标相除即可得到计算强度。 比如H100 的计算强度就是 295。
模型相关的指标主要评估的是模型解码过程中需要计算资源,这些指标和模型如何部署相关
计算量:模型生成一个token所需要的浮点数运算个数,单机部署的模型参数越多,处理的序列越长计算量越大。
访存量:模型生成一个token所需要发生的内存交换总量,单机部署服务的请求越多,处理的序列越长访存量越大。
二,部署大模型的成本情况
为了确认大模型的成本我们首先需要根据业务场景的复杂程度来确认到底使用哪个模型,DeepSeek 最新发布的系列模型简要列于下表
| 模型 | 特点 | 备注 |
| DeepSeek-V3 671B | 擅长语文,聊天 | 综合能力强 成本高 |
| DeepSeek-R1 671B | 擅长写代码,做数学 | 综合能力强 成本高 |
| DeepSeek-R1-Distill-Qwen-32B | 擅长写代码,做数学,基于Qwen蒸馏,中文比较好 | 成本低 适合专项场景 |
| DeepSeek-R1-Distill-Llama-70B | 擅长写代码,做数学,基于Llama蒸馏,中文略差于Qwen | 成本低 适合专项场景 |
根据DeepSeek的论文, 使用R1模型SFT的Distill模型,继续使用RL还可以增强其能力,阿里最新的QwQ 32B模型也证明了这个研究方向,在客观的benchmark评测中得分很高。

(deepseek 论文)
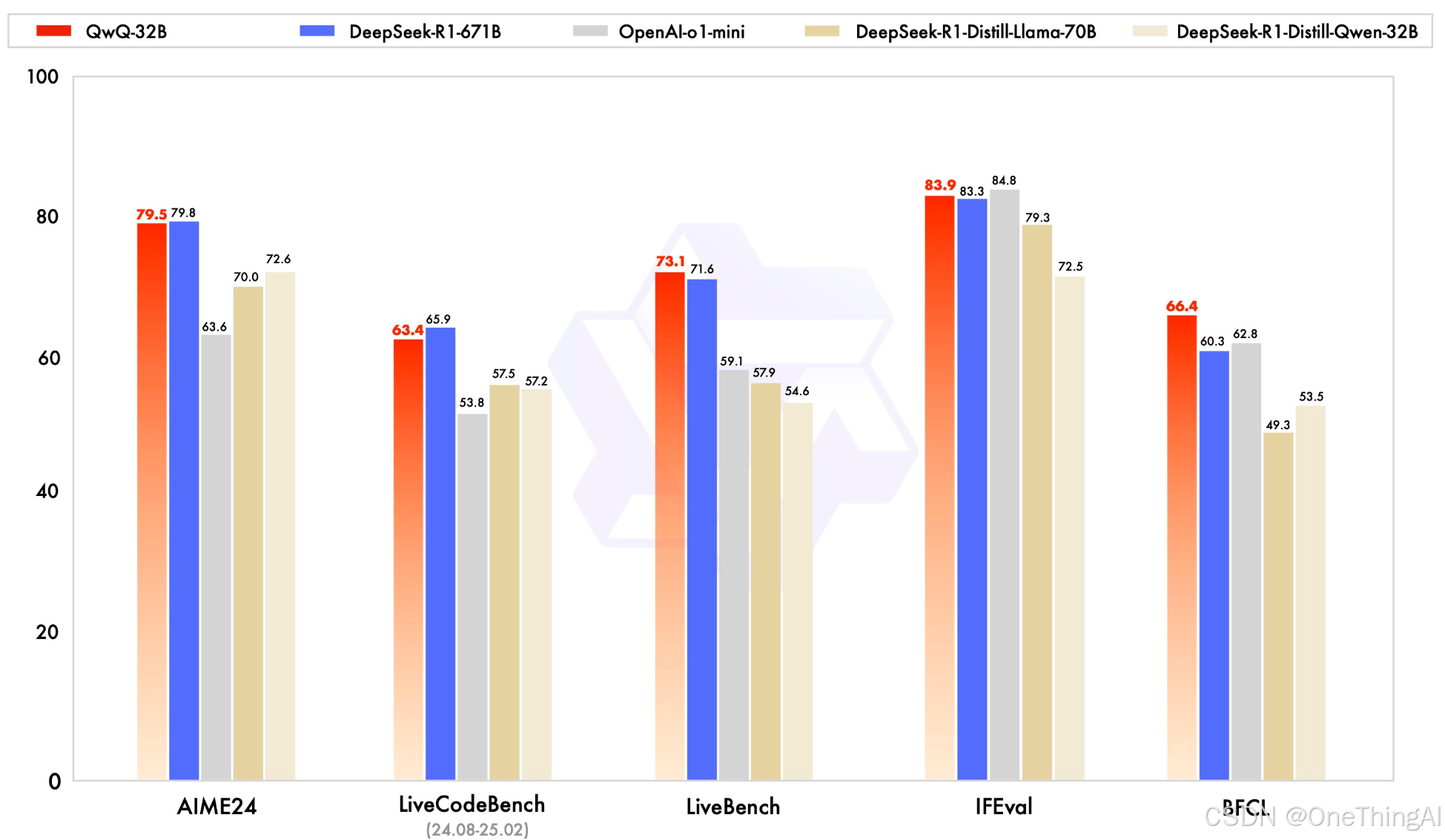
(QwQ-32B 评测结果)
整体来看小模型能力弱于大模型,但某些场景下小模型回答的准确性足够,比如简单一些的客服场景,某个领域的专业模型。
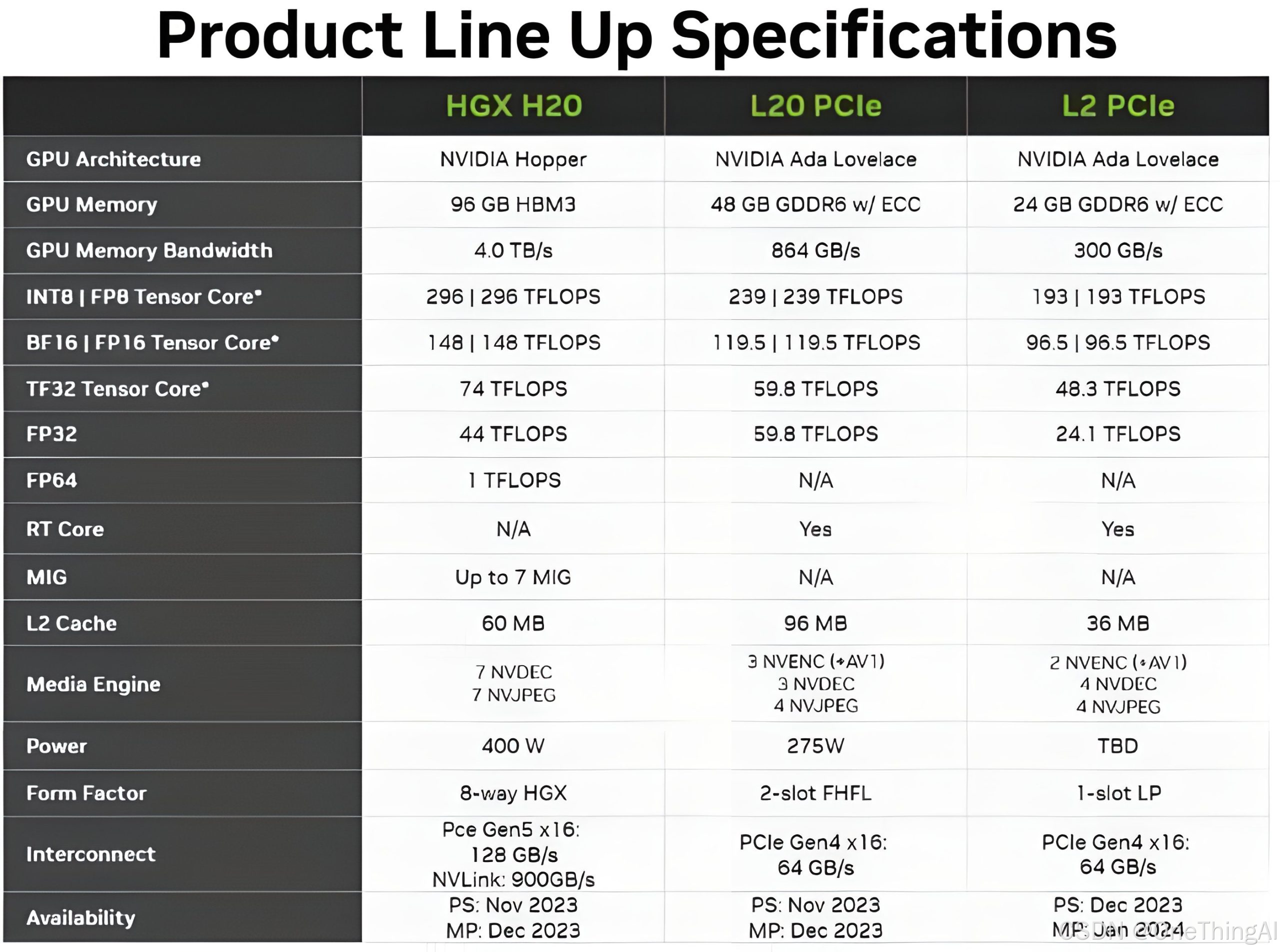
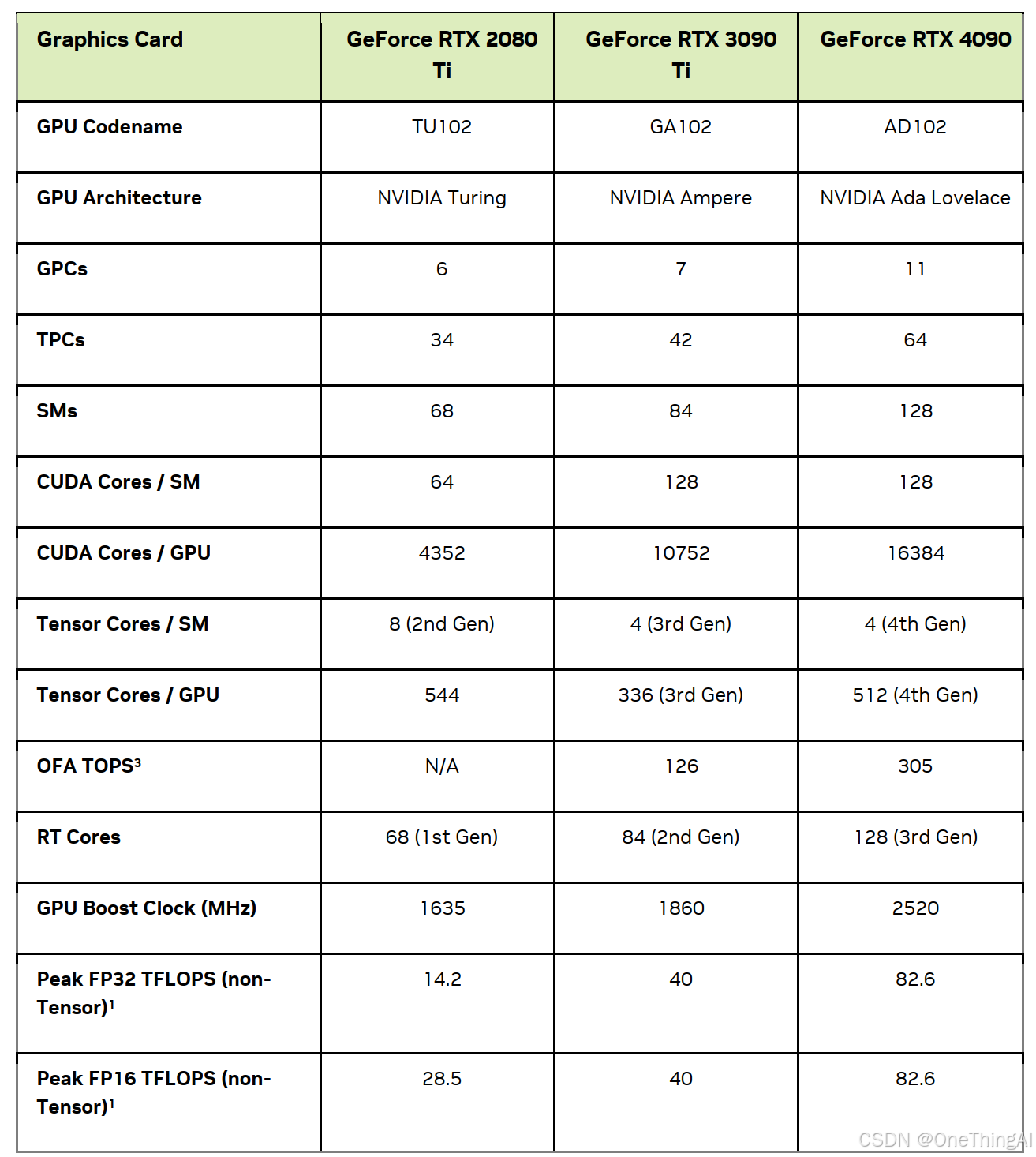
下面会以4090,H20 做为主要的加速卡来进行讨论,H20 明显的特征是:显存大;显存带宽高;GPU互联带宽大。非常适合做为LLM推理的加速卡。4090 受互联能力限制,单机8卡性价比超高(可根据第一章节来做推导)。
H20 参数如下:
RTX 4090 参数:
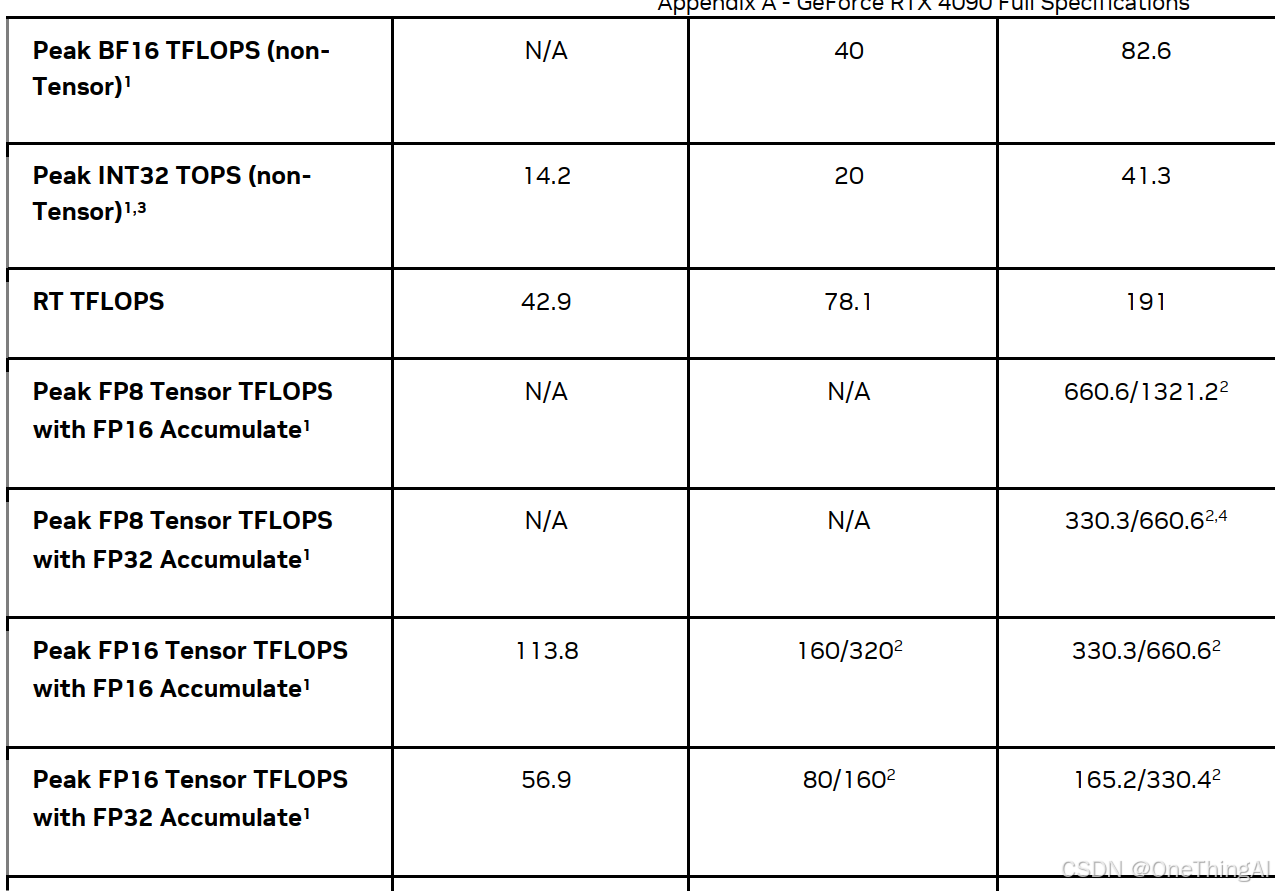
下表是价格评估(政策等原因,价格会随市场发生变化)
| 模型 | 显存要求 | 高性价比硬件配置 | 价格预估 | 并发估算 |
| DeepSeek-V3 671B | 基础:700GB kv cache:5k上下文,约2.5GB | H20 141GB 1台/ H20 96GB 2台 | 本地私有化部署: H20 2台,约300万 | 可支持约50人并发(即同一时刻使用),假设总人数的10%会同时使用,可支持约500人使用 |
| 云端私有化部署: H20 2台,约6万/月 | ||||
| DeepSeek-R1 671B | 基础:700GB kv cache:5k上下文,约 2.5 GB | H20 141GB 1台/ H20 96GB 2台 | 本地私有化部署: H20 2台,约300万 | |
| 云端私有化部署: H20 2台,约6万/月 | ||||
| DeepSeek-R1-Distill-Qwen-32B | 基础:70GB kv cache:5k上下文,约8 GB | 4 张4090/8张4090 1台 | 本地私有化部署: 1台8卡4090,约25万 | 小模型+短上下文的情况下,并发可达满血的3-4倍 |
| 云端私有化部署: 1台8卡4090,约1w/月 | ||||
| DeepSeek-R1-Distill-Llama-70B | 基础:150GB kv cache 5k上下文,~10 GB | 8张4090 1台/A800 80GB 台/H20 96GB 1台 | 本地私有化部署: 1台8卡4090,约25万 | 小模型+短上下文的情况下,并发可达满血的2-3倍 |
| 云端私有化部署: 1台8卡4090,约1w/月 |
有私有化需求请戳解决方案 - OneThingAI算力云 - 热门GPU算力平台
参考文献:

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









