




刚刚,阿里图像编辑大杀器Qwen-Image-Edit上线,横扫像素与语义编辑,网友:再见PS今天凌晨,阿里推出了最新图像编辑模型 Qwen-Image-Edit!
Qwen-Image-Edit基于我们20B的Qwen-Image模型进⼀步训练,成功将Qwen-Image的独特的文本渲染能力延展至图像编辑领域,实现了对图片中文字的精准编辑。此外,Qwen-Image-Edit将输⼊图像同时输⼊到Qwen2.5-VL(实现视觉语义控制)和VAE Encoder(实现视觉外观控制),从而兼具语义与外观的双重编辑能⼒。
Qwen-Image-Edit的主要特性包括:
语义与外观双重编辑: Qwen-Image-Edit不仅⽀持low-level的视觉外观编辑(如元素的添加、删除、修改等,要求图片其他区域完全不变),也支持 high-level 的视觉语义编辑(如 IP 创作、物体旋转、风格迁移等,允许整体像素变化但保持语义一致)。
精准⽂字编辑: Qwen-Image-Edit 支持中英文双语文字编辑,可在保留原有字体、字号、风格的前提下,直接对图片中的文字进行增、删、改等操作。
强⼤的基准性能: 在多个公开基准测试中的评估表明,Qwen-Image-Edit 在图像编辑任务上具备SOTA性能,是一个强大的图像编辑基础模型。
地址:
ModelScope:
Hugging Face:
Qwen/Qwen-Image-Edit · Hugging Face
AIGC算力云:
示例展示
Qwen-Image-Edit的一大亮点在于其强大的语义与外观双重编辑能力。所谓语义编辑,是指在保持原始图像视觉语义不变的前提下,对图像内容进行修改。
原创IP编辑
我们以Qwen的吉祥物——卡皮巴拉为例,来直观展示这一能力:
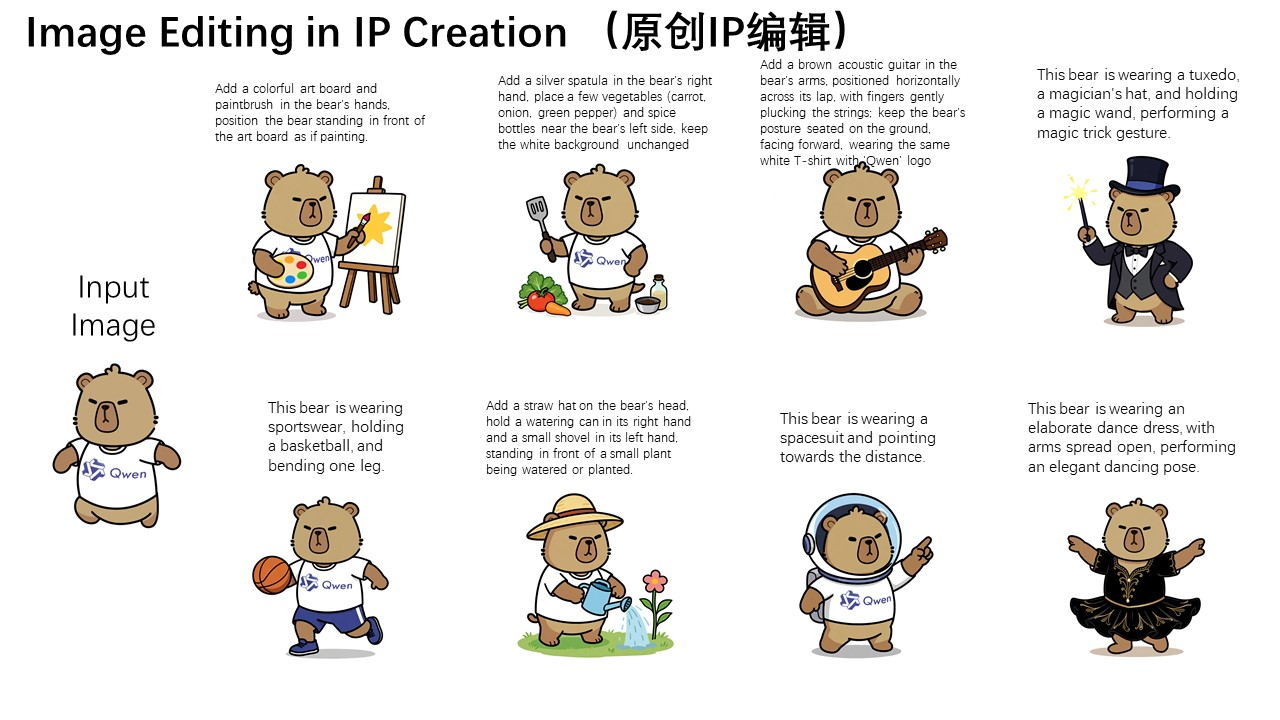
可以看到,虽然编辑后的图像大多数像素与输入图像(最左侧的图)都不一样,但依然完美地保持了卡皮巴拉的角色一致性。Qwen-Image的强大的语义编辑能力使其能够轻松地进行原创IP的多样化创作。
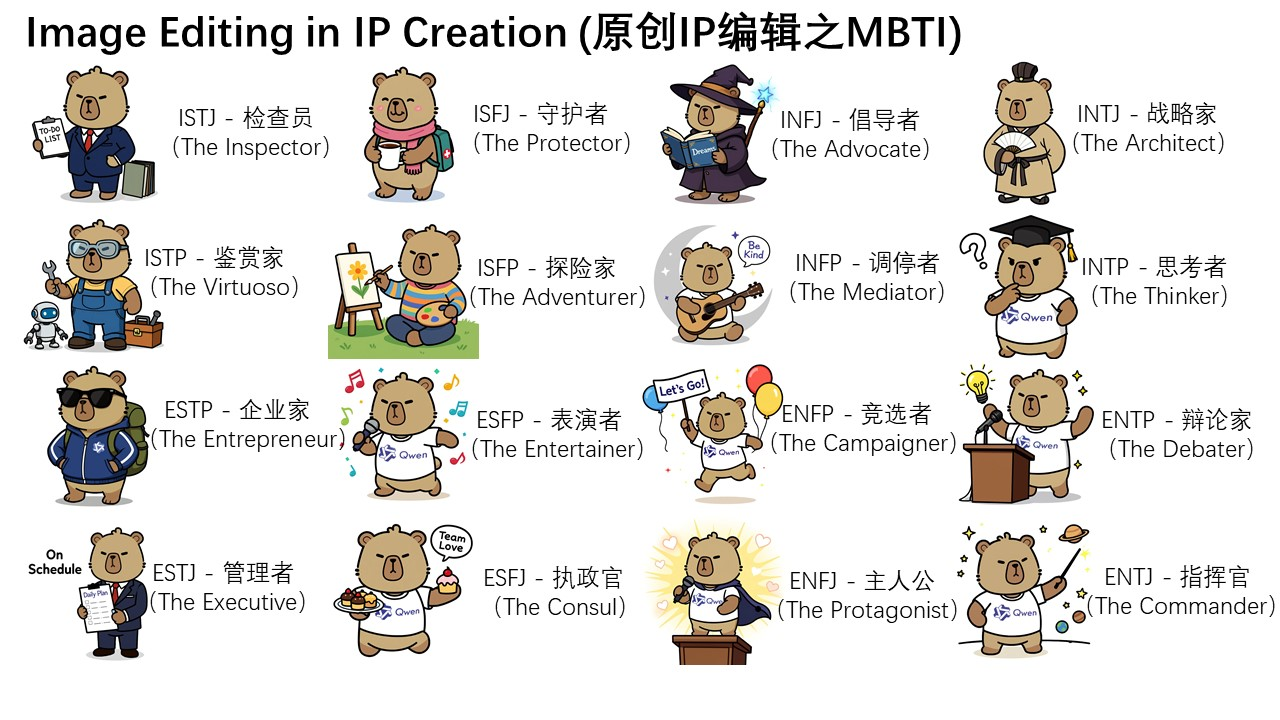
更进一步的,我们在Qwen Chat上围绕MBTI十六型人格,设计了一系列编辑prompt,成功地基于吉祥物卡皮巴拉,完成了MBTI表情包的制作,轻松地拓展了IP。
视角转换
此外,视角转换同样是语义编辑中的一个重要应用场景。如下方两张示例图所示,Qwen-Image-Edit不仅能够实现物体的90度旋转,还可以完成180度旋转,让我们直接看到物体的背面:


风格迁移
语义编辑的另一个典型应用是风格迁移。例如,输入一张人物头像,Qwen-Image-Edit可以轻松将其转换为吉卜力等多种风格,这在虚拟形象创作等场景中极具价值:

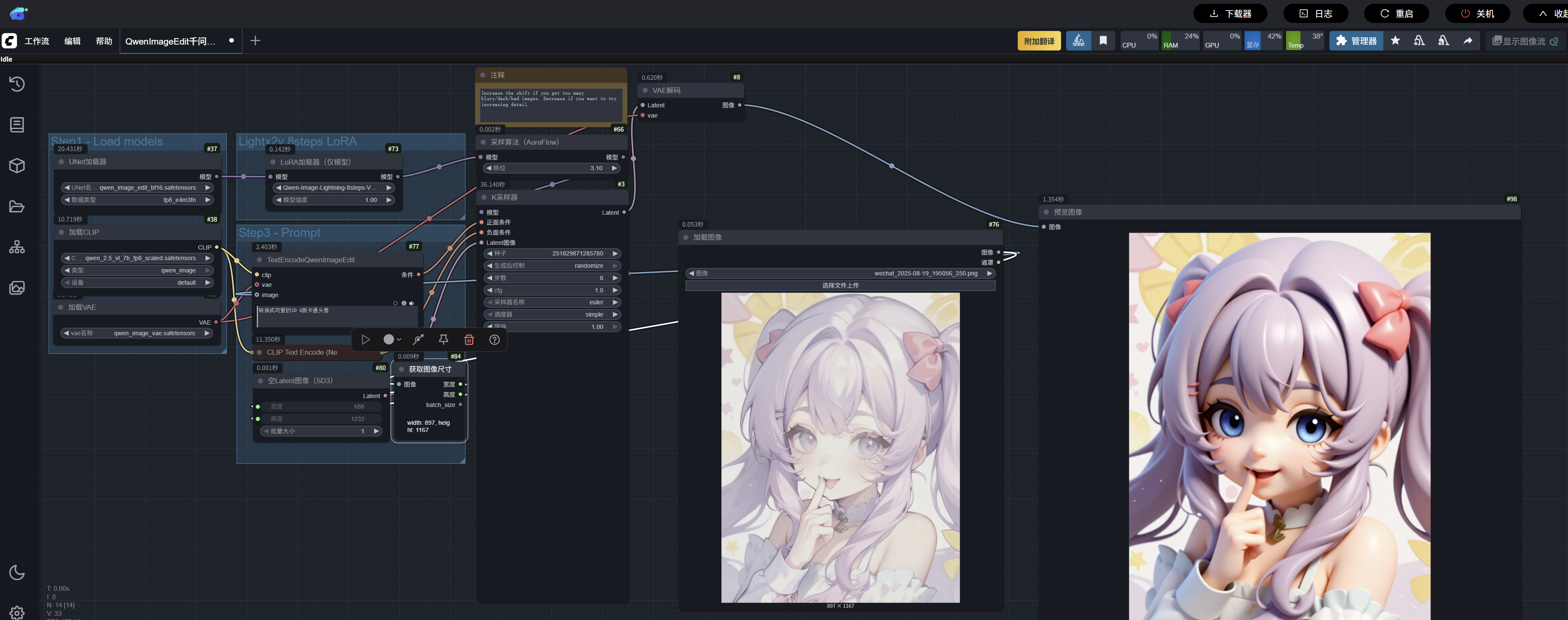
ComfyUI中,转换3D风格
新增、消除、重绘
除了语义编辑,外观编辑也是常见的图像编辑需求。外观编辑强调在编辑过程中保持图像的部分区域完全不变,实现元素的增、删、改。下图展示了在图片中添加指示牌的案例,可以看到Qwen-Image-Edit不仅成功添加了指示牌,还生成了相应的倒影,细节处理十分到位。

下方是另一个有趣的例子,展示了如何在图片中删除细小的头发丝等微小物体。

此外,图像中特定字母“n”的颜色可以更改为蓝色,从而实现对特定元素的精确编辑。

⼈物背景调整、服装修改
外观编辑在人物背景调整、服装更换等场景中同样有着广泛的应用,下面三张图片分别展示了这些实际应用场景。


英文文字编辑
Qwen-Image-Edit的另一大亮点在于其准确的的文字编辑能力,这得益于Qwen-Image在文字渲染方面的深厚积累。如下所示,以下两个案例直观展示了Qwen-Image-Edit在英文文字编辑上的强大表现:


中文海报编辑
Qwen-Image-Edit同样能够直接对中文海报进行编辑,不仅可以修改海报中的大字,连细小的文字也能精准调整。

链式编辑
最后,让我们通过一个具体的图像编辑案例,演示如何利用链式编辑的方式,逐步修正Qwen-Image生成的书法作品中的错误:
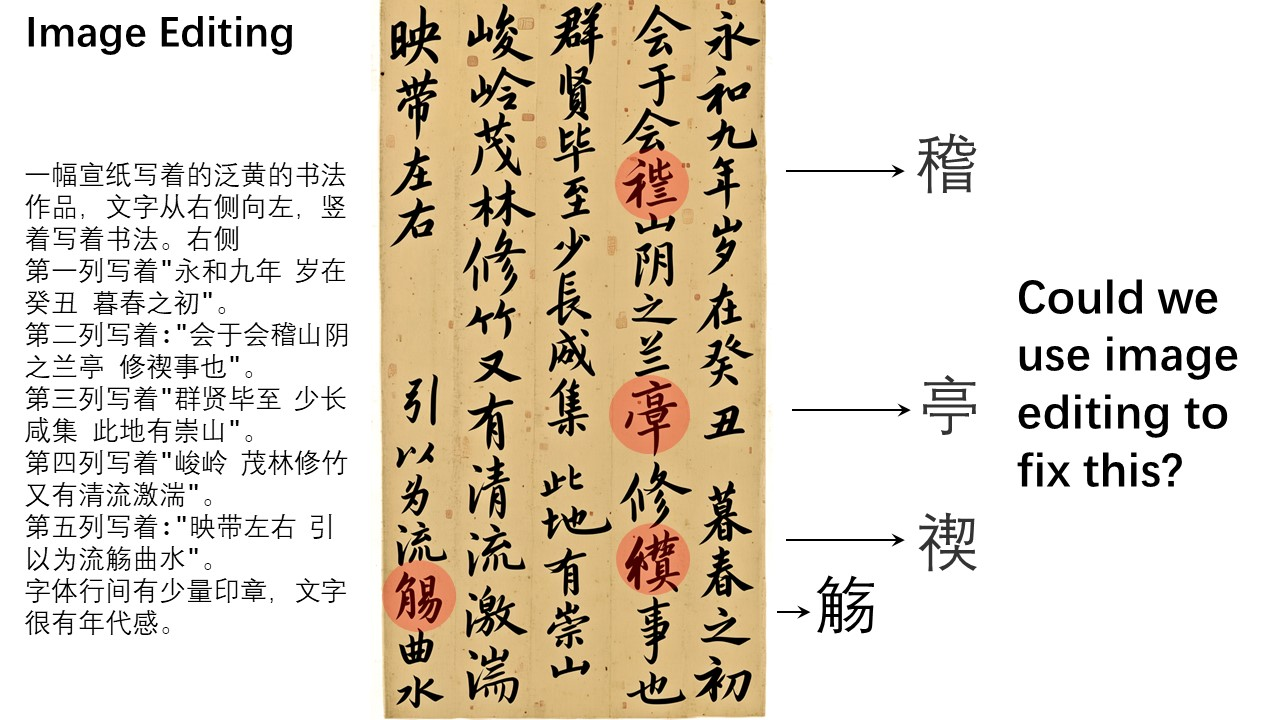
在这幅作品中,有不少汉字存在生成错误。我们可以借助Qwen-Image-Edit,逐步修复它们。例如,可以在原图中用方框标注出需要修改的区域,指示Qwen-Image-Edit针对这些部分进行修正。这里,我们希望红框内正确地写出“稽”字,蓝色区域正确地写出“亭”字。

但实际操作中,“稽”字较为生僻,模型未能一次性完成修改。“稽”的右下角应为“旨”而非“日”。此时,我们可以进一步用红框圈出“日”的部分,让Qwen-Image-Edit对该细节进行微调,将其改为“旨”。

是不是很神奇?通过这种链式、逐步的编辑方式,我们可以持续修正错字,直至获得理想的最终效果。





最后,成功获得了一版完全正确的《兰亭集序》书法作品!总之,我们希望通义万相 - 图像编辑能够进一步推动图像生成领域的发展,真正降低视觉内容创作的技术门槛,并激发出更多创新应用。


















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









