




 本文详细介绍了注意力机制在深度学习,特别是Seq2Seq模型中的应用。通过对比Luong和Vaswani的注意力机制,重点解释了Scaled Dot-Product Attention的工作原理,包括Attention Score的计算、Attention Distribution的softmax转换以及Attention Output的生成过程。文中还提供了矩阵运算的表示,帮助读者理解各个步骤,并给出了PyTorch实现的关键代码片段。
本文详细介绍了注意力机制在深度学习,特别是Seq2Seq模型中的应用。通过对比Luong和Vaswani的注意力机制,重点解释了Scaled Dot-Product Attention的工作原理,包括Attention Score的计算、Attention Distribution的softmax转换以及Attention Output的生成过程。文中还提供了矩阵运算的表示,帮助读者理解各个步骤,并给出了PyTorch实现的关键代码片段。
Attention两篇文章链接:其中一个是Luong,提的dot product attention, 另一个是Vaswali的scaled dot product attention , 也就是大名鼎鼎的attention is all you need。
说到attention不再过多赘述,论文中的公式推导感觉比较简单,结合自己的理解写一下矩阵层面的表示。数学好的可以跳过。
在attention is all you need这篇文章中,他是这么写的:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V,而Luong那篇文章中,公式比较多且分散。
但无论如何,大致总结是(看下图),先算attention score(Q,K相乘),再用softmax算distribution,再把distribution和hidden state相乘获得attention output(最上面那个MatMul),再把output和另一个hidden相加(concat)。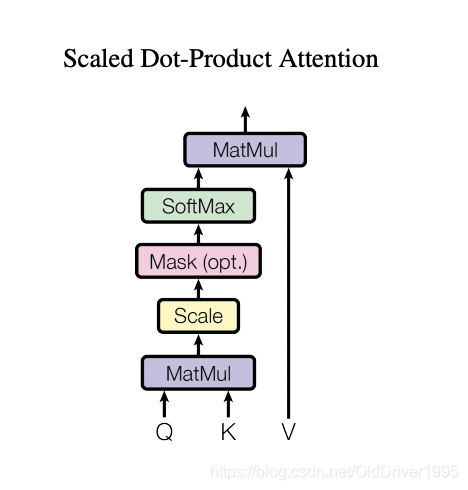
这里以seq2seq模型中的attention为例。
首先我们有encoder hidden state的一个序列: H = [ h 1 , h 2 , . . . h N ] H =[h_1, h_2, ...h_N] H=[h1,h2,...hN]
然后有 t t t 时刻的decoder state s t s^t st, 所有时刻的decoder state就是 S = [ s 1 , s 2 , . . . , s t ] S=[s^1, s^2, ..., s^t] S=[s1,s2,...,st]。
每次用所有的encoder hidden state去和当前时刻的decoder state相乘(dot product)
对于 t t t时刻而言的attention score就是用 e t = [ h 1 T s t , h 2 T s t , . . . , h N T s t ] e^t = [h_1^Ts^t, h_2^Ts^t, ..., h_N^Ts^t] et=[h1Tst,h2Tst,...,hNTst],
但实际在计算中,我们是把整个decoder hidden state和encoder hidden state乘起来,而不是像循环一样对每个时刻都依次计算
E = [ h 1 T s 1 h 2 T s 1 , . . . , h N T s 1 ⋮ ⋮ ⋱ ⋮ h 1 T s t − 1 h 2 T s t − 1 , . . . , h N T s t − 1 h 1 T s t h 2 T s t , . . . , h N T s t ] = [ s 1 s 2 ⋮ s t ] ⋅ [ h 1 T h 2 T ⋯ h N T ] ( 1 ) E = \left[ \begin{matrix} h_1^Ts^1 & h_2^Ts^1, &..., &h_N^Ts^1 \\ \vdots & \vdots &\ddots &\vdots\\ h_1^Ts^{t-1} & h_2^Ts^{t-1}, &..., &h_N^Ts^{t-1}\\ h_1^Ts^t & h_2^Ts^t, &..., &h_N^Ts^t \end{matrix} \right] = \left[ \begin{matrix}s^1\\ s^2\\ \vdots\\ s^t \end{matrix} \right] \cdot \left[ \begin{matrix} h_1^T & h_2^T & \cdots & & h_N^T \end{matrix} \right] \ (1) E=⎣⎢⎢⎢⎡h1Ts1⋮h1Tst−1h1Tsth
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2906
2906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









