




论文名称:AgentBench: Evaluating LLMs as Agents
论文链接:https://arxiv.org/abs/2308.03688
机构:清华 ChatGLM 团队
Github 链接:https://github.com/THUDM/AgentBench
官方界面:https://llmbench.ai/agent
简介
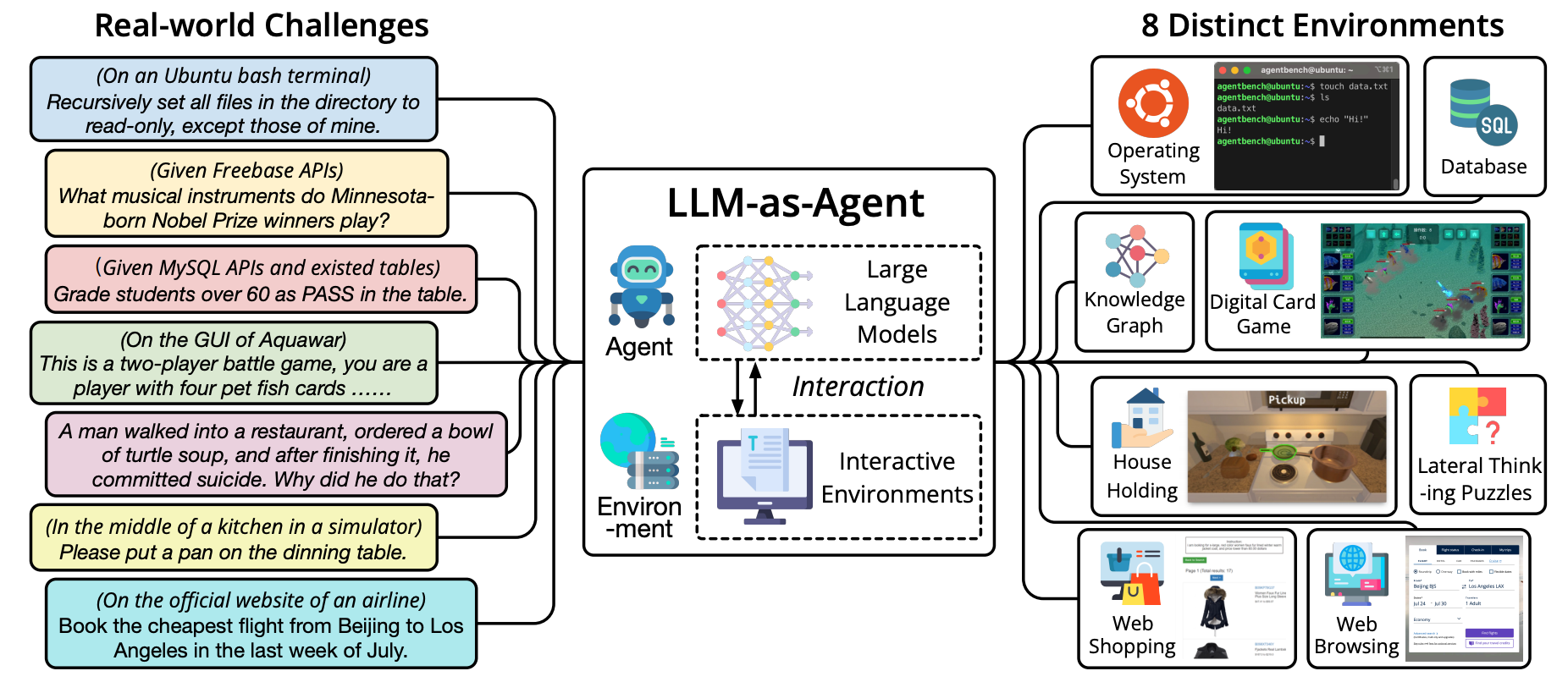
AgentBench是由清华大学KEG与数据挖掘团队提出的综合性基准测试,旨在系统评估AIAgent在复杂交互环境中的综合能力,也是第一个在不同环境中评估LLM as Agent的Benchmark。
评估维度
团队认为Agent能力主要包含八个部分:① 理解人类意图并执行指令;② 编码能力;③ 知识获取和推理;④ 策略决策;⑤ 多轮一致性;⑥ 逻辑推理;⑦ 自主探索;⑧ 可解释的推理。
只有LLM能完成上述具体任务,才可能承担好 AI Agent的工作。为了达成上述评估目标,作者首先新创建了5个环境,评估LLM as Agent的能力:
① 操作系统(OS):评估LLM在Linux系统的bash环境中的操作能力,如文件操作、用户管理等。
② 数据库(DB):考察LLM利用SQL操作给定的数据库完成查询、修改等任务。
③ 知识图谱(KG):需要LLM利用给定的工具查询知识图谱,完成复杂的知识获取任务。
④ 卡牌游戏(DCG):将LLM视为玩家,根据规则和状态进行数字卡牌游戏,评估策略决策能力。
⑤ 横向思维难题(LTP):提供难题故事,LLM需要进行问答来推理得到真相,检查横向思维能力。
以及从已发布的数据集重新编译的3个环境数据:
⑥ 家庭环境(HH):在模拟的家中场景下,LLM需要自主完成日常任务,如搬移物品等。
⑦ 网络购物(WS):按照要求在模拟购物网站上浏览和购买商品,评估自主探索决策能力。
⑧ 网页浏览(WB):在真实网页环境中,根据高级指令实现操作序列,完成网页任务。
使用方法
官方的 Github 界面已经给出详细的操作指南,主要分为四步:环境配置 -> 配置Agent -> 启动任务服务器 -> 启动任务测试。因为涉及到多个任务,所以需要分别起服务评测,资源消耗情况大致如下::

评价指标
核心指标
- 综合得分(Overall Score)
各场景得分的加权平均,反映模型作为Agent的综合能力。

辅助指标
- 分场景成功率(Success Rate)
各任务独立计算完成率,揭示模型能力短板。
- 失败模式分布(Failure Mode Analysis)
统计10类失败原因(如错误工具调用、逻辑推理错误),指导针对性优化。
- 效率指标(Steps&Time Cost)
评估任务完成所需交互轮次与耗时,衡量Agent决策效率。

总结
评测集设计比较全面,但聚焦的评测维度是LLM As Agent所具备的原子能力,对于Agent能否顺利且完整的完成一个现实任务的过程并没有做评测,与GAIA能形成互补的局面。



















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











