




论文名称:Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use
论文链接:https://arxiv.org/abs/2504.04736
机构:斯坦福大学计算机科学系 + Google DeepMind
简介
这篇论文提出一个逐步强化学习(SWiRL)方法,用来解决LLM在处理如多跳问答、数学解题等需要多步推理和工具使用的复杂任务时面临的挑战,这些任务要求模型分解问题、适时调用工具并合成结果,而传统RL方法(如RLHF、RLAIF)聚焦单步优化无法有效应对。所以SWiRL通过合成数据和离线RL优化的策略,能够提升模型多步推理和工具使用能力。
Stage-1:Synthetic Data Generation
流程概述
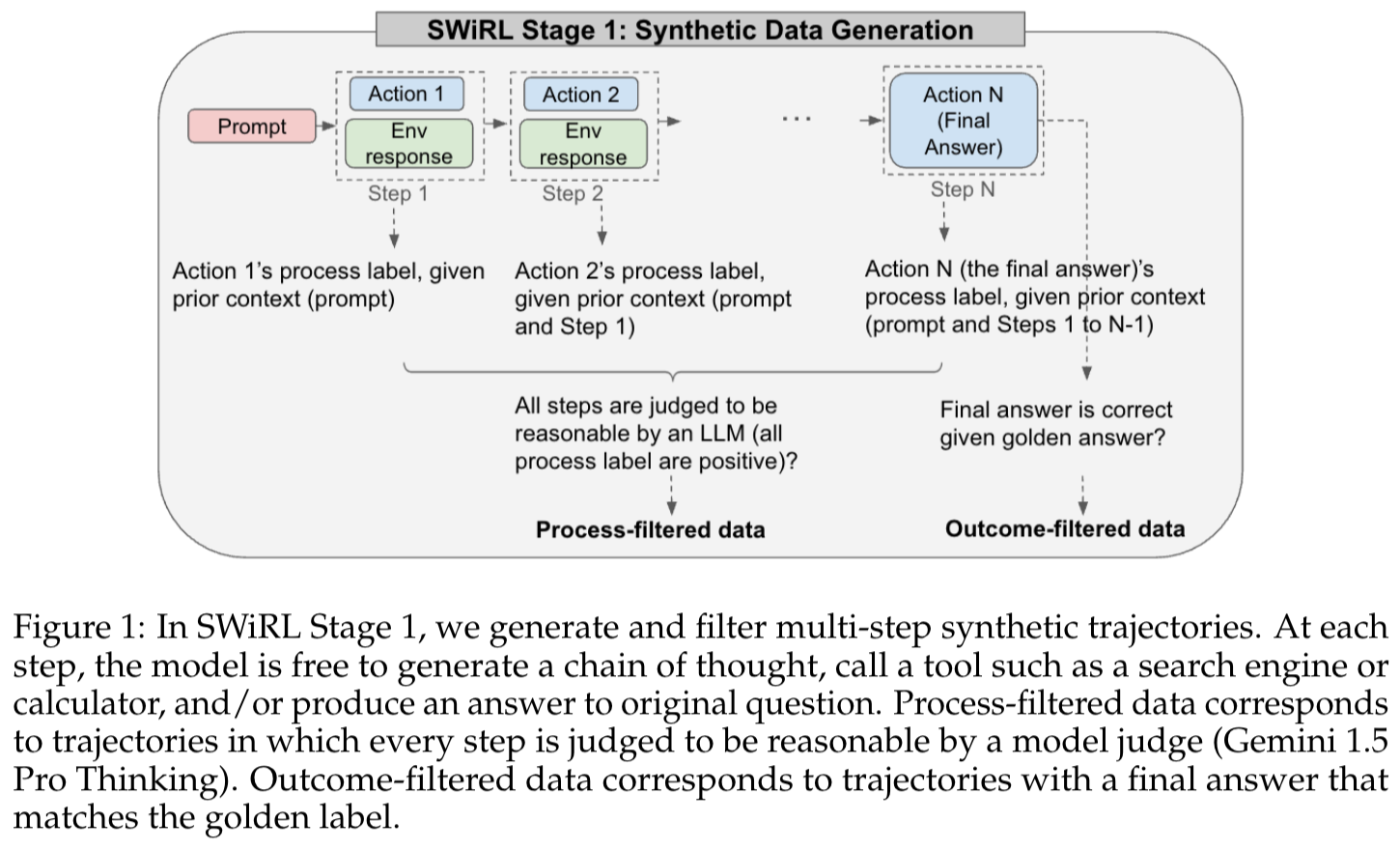
图1展示的是SWiRL的第一阶段:合成数据生成 。流程如下:
-
一开始有个“Prompt”(粉红色框 ),这相当于给模型的一个起始提问或者任务指示。
-
然后进入多个步骤(从左到右 ),每个步骤都包含“Action”(浅蓝色框 )和“Env response”(绿色框 )。“Action”可以理解为模型采取的操作,“Env response”就是环境(比如调用工具等操作后得到的反馈 )给出的响应。从“Step 1”到“Step N”,一步步推进,直到最后“Action N”得到“Final Answer”(最终答案 )。
-
在每个步骤中,会根据前面的上下文(比如第一步依据“Prompt” ,第二步依据“Prompt和Step 1” ,第N步依据“Prompt和Steps 1到N - 1” ),给出该步骤操作的“process label”(过程标签 )。
-
接下来有两种过滤方式:
① 过程过滤:用LLM判断所有步骤的“process label”是不是都是正向的(合理的 ),如果是,这些数据就成为“Process - filtered data”(过程过滤后的数据 )。
② 结果过滤:判断最终答案“Final Answer”和“golden answer”(标准答案 )相比是不是正确的,如果正确,这些数据就成为“Outcome - filtered data”(结果过滤后的数据 )。
实现细节
- Step-1:合成轨迹生成
① 通过为语言模型配备工具(如搜索引擎、计算器 ),迭
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











