




视频讲解1:https://www.bilibili.com/video/BV15B1QBEEbH/?pop_share=1&vd_source=b2eaaddb2c69bf42517a2553af8444ab
视频讲解2:https://www.douyin.com/video/7570320008614612243
论文下载链接:P2PNet论文下载链接
代码下载链接:https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet
人群计数数据集详解:人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
本文提出P2PNet,一种基于点预测的人群计数与定位新框架。针对现有密度图方法定位模糊和检测方法依赖伪标注的缺陷,该方法直接预测个体位置点,实现精确计数定位。创新点包括:1)纯点预测框架;2)密度归一化平均精度新指标;3)双分支网络结构。实验表明,P2PNet在计数精度和定位性能上达到最优,为人群分析任务提供了更实用的解决方案。相关代码和数据集已在GitHub开源。
目录

现有方法局限性
在人群分析任务中,仅仅给出总人数(计数)往往无法满足后续高级任务(如跟踪、行为识别)的需求,精确定位每个个体的位置(定位)更具实用价值。然而,当时的主流方法存在固有缺陷:
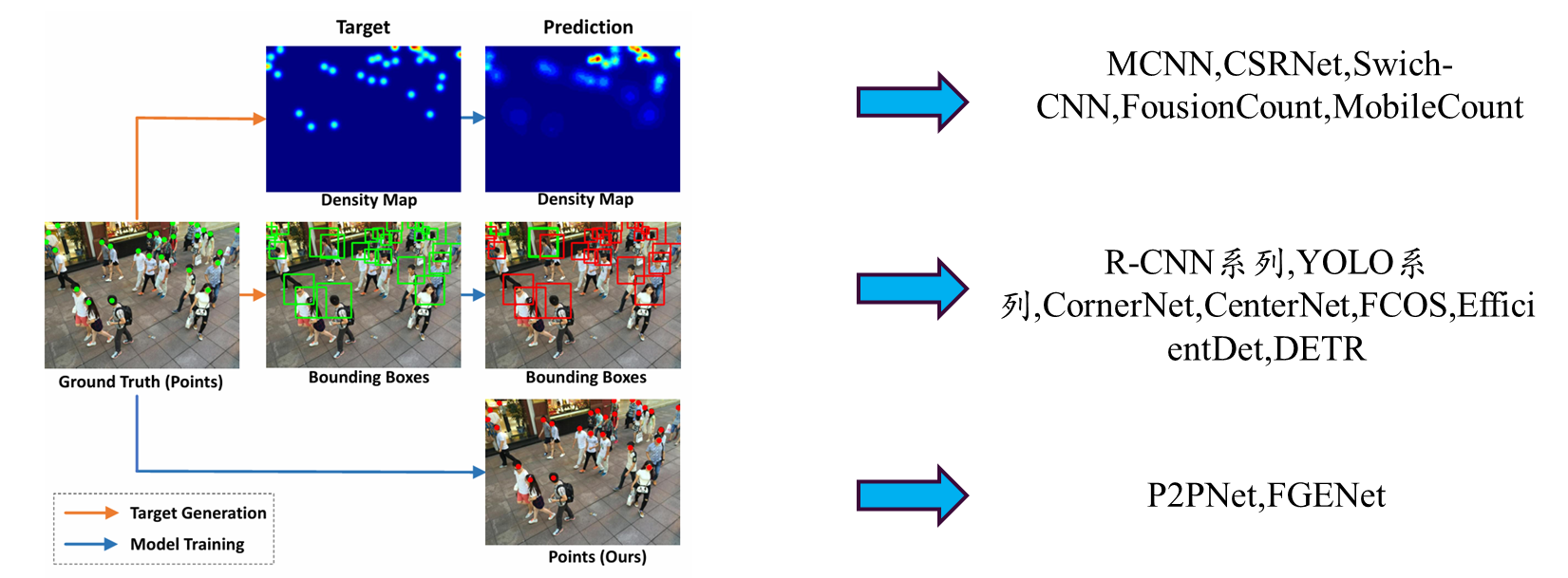
- 密度图回归方法:主流的计数方法通过预测密度图再求和得到总人数。但这种方法无法提供个体的精确位置,且密度图本身存在模糊性和回归误差。
检测框方法:一些方法尝试将计数视为头部检测问题。但这类方法需要启发式地生成伪边界框作为学习目标(因为标注通常只有中心点),这既不准确,又会使非极大值抑制(NMS)等后处理步骤在密集场景中失效。
其他定位方法:一些直接定位个体的方法则需要在后处理中费力地抑制或拆分过度接近的候选目标,在尺度变化极大的密集区域容易出错。
方法对比
如图所示: 提出的方法流程与现有方法的对比示意图。图中红色标记表示预测结果,绿色标记表示真实标注。
顶部流程:基于密度图学习的主流方法无法提供个体的精确位置。
中部流程:估计不准确的真实标注边界框使得基于检测的方法容易出错(如图中标注的漏检示例),在类NMS(非极大值抑制)处理过程中尤为明显。
底部流程:提出的流程直接预测一组代表个体位置的点(如演示所示),该方法简洁直观且具有竞争力,成功规避了前述易错步骤。建议彩色查看以获得最佳效果。
提出方法
2.提出了一种称为密度归一化平均精度(density Normalized Average Precision)的新评估指标,作为新框架下兼顾定位与计数评估的综合指标。
3.提出了P2PNet作为这一概念简洁框架的直观解决方案。该方法实现了最先进的计数精度和优异的定位性能,并可能为其他依赖点预测的任务提供启发。
模型整体框架
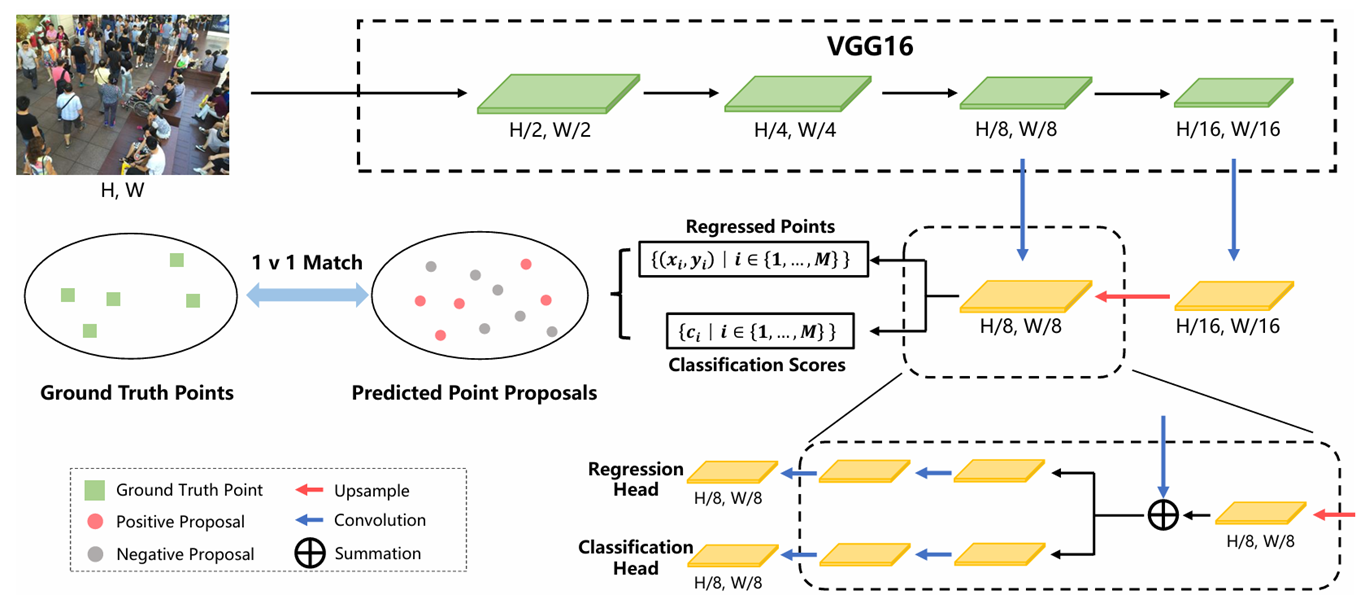
该模型基于VGG16构建,首先引入上采样路径以获得细粒度深度特征图,随后通过双分支结构同步预测点候选集及其置信度分数。流程中的关键步骤是确保点候选与真实标注点之间实现一对一匹配,这一机制决定了各候选点的学习目标。
密度归一化平均精度

点对点的匹配方案
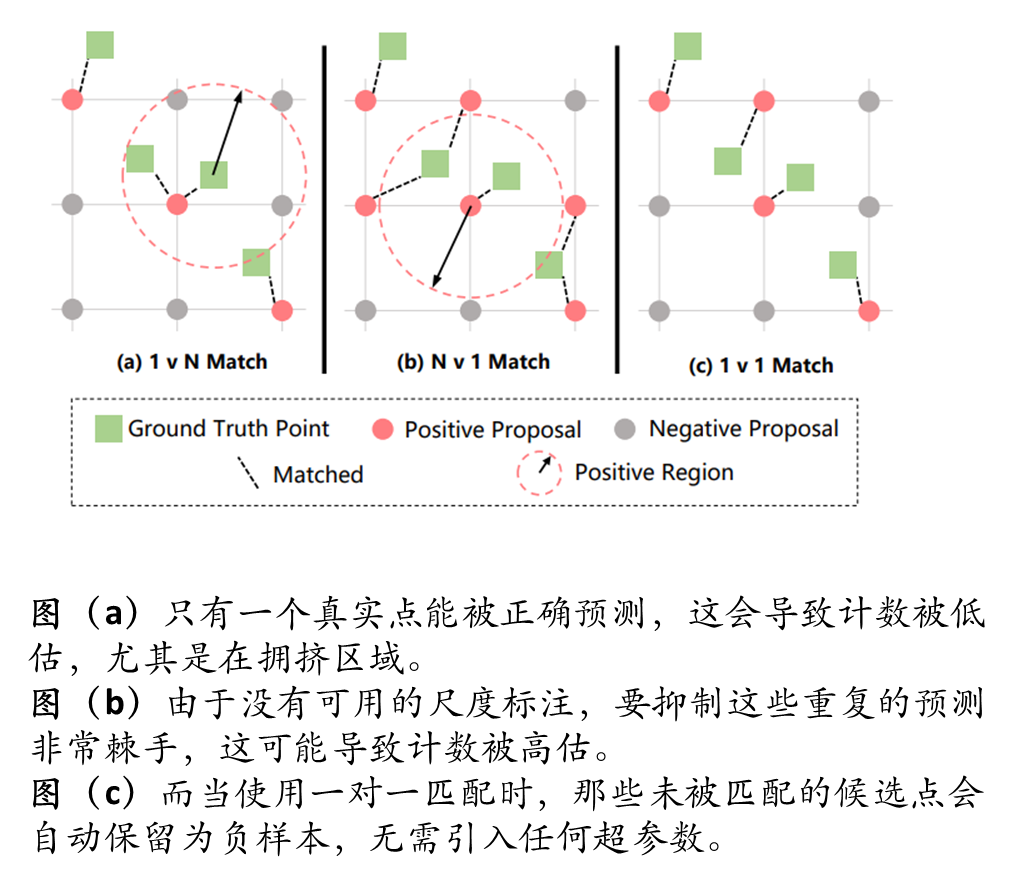
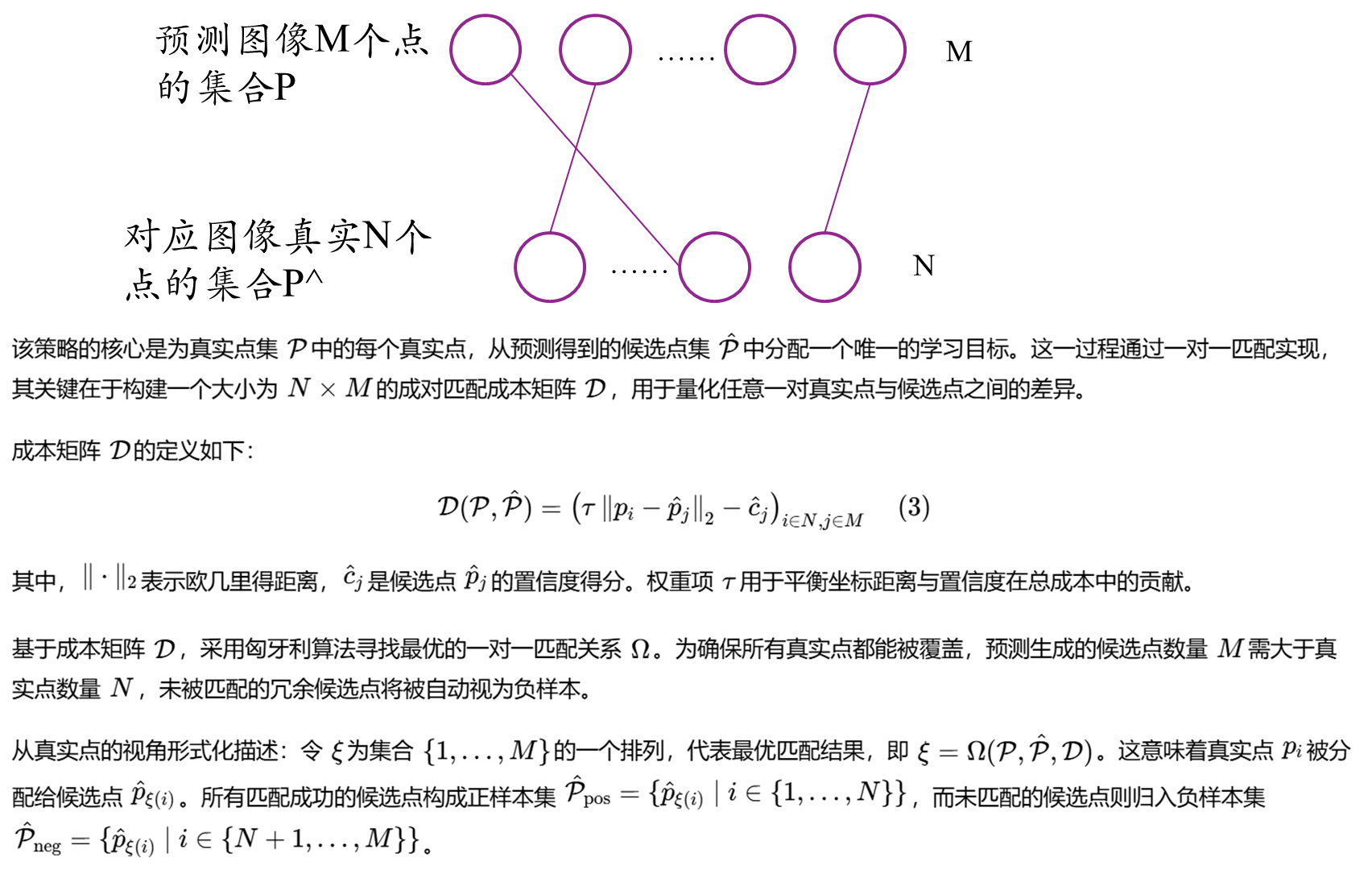
匹配规则优化:
•等置信度场景:当多个候选点具备相同置信度时,优先匹配空间距离更接近真实标注点 pi的样本作为正样本,通过训练激励其达成更高定位精度;其余候选点则作为负样本监督学习以降低其置信度,减少在后续训练迭代中的错误匹配概率。
•等距离场景:当多个候选点与 pi的距离相同时,优先选择置信度更高的样本进行匹配,并通过强化学习使其进一步逼近真实标注点并提升置信度。
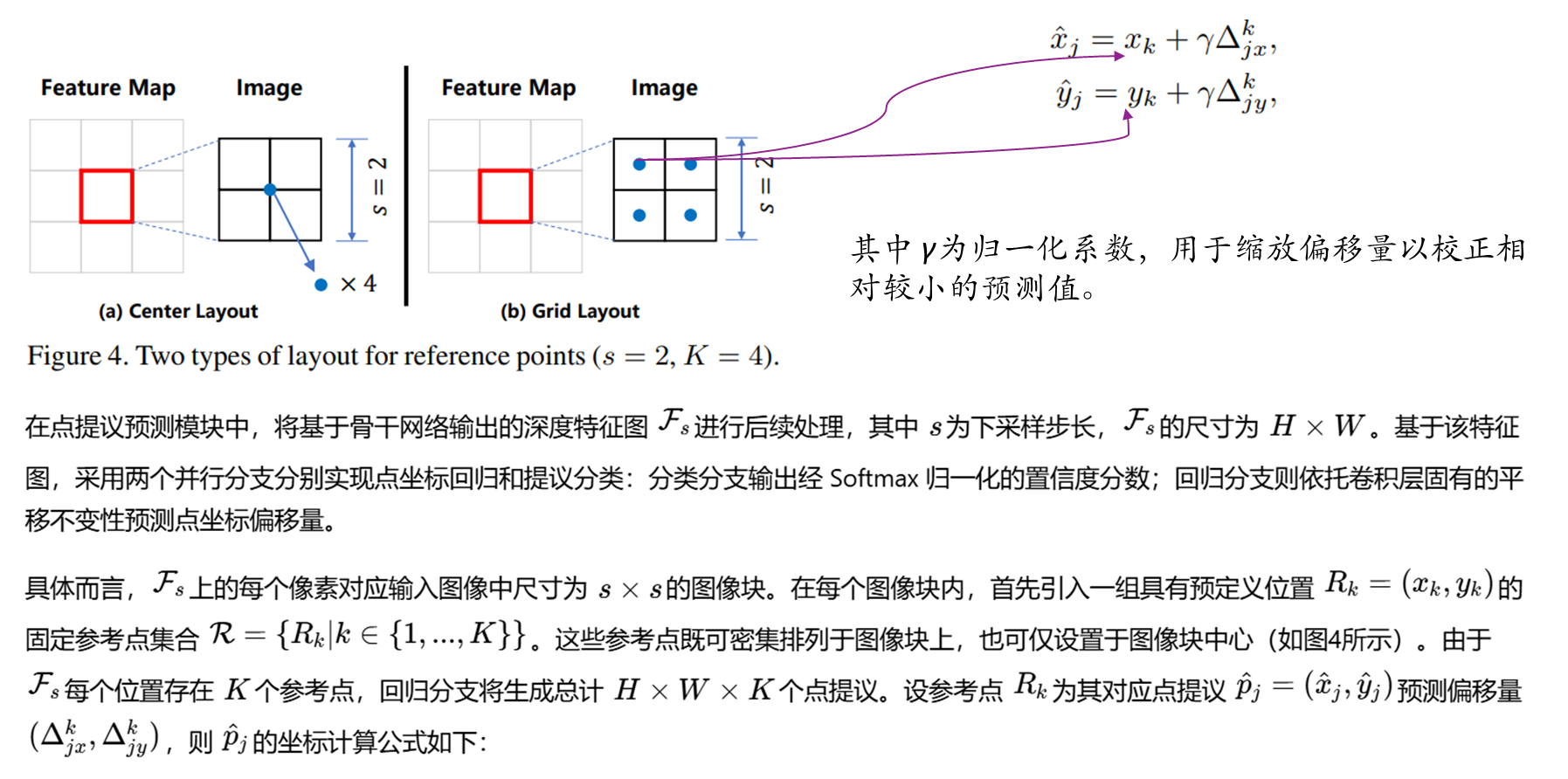
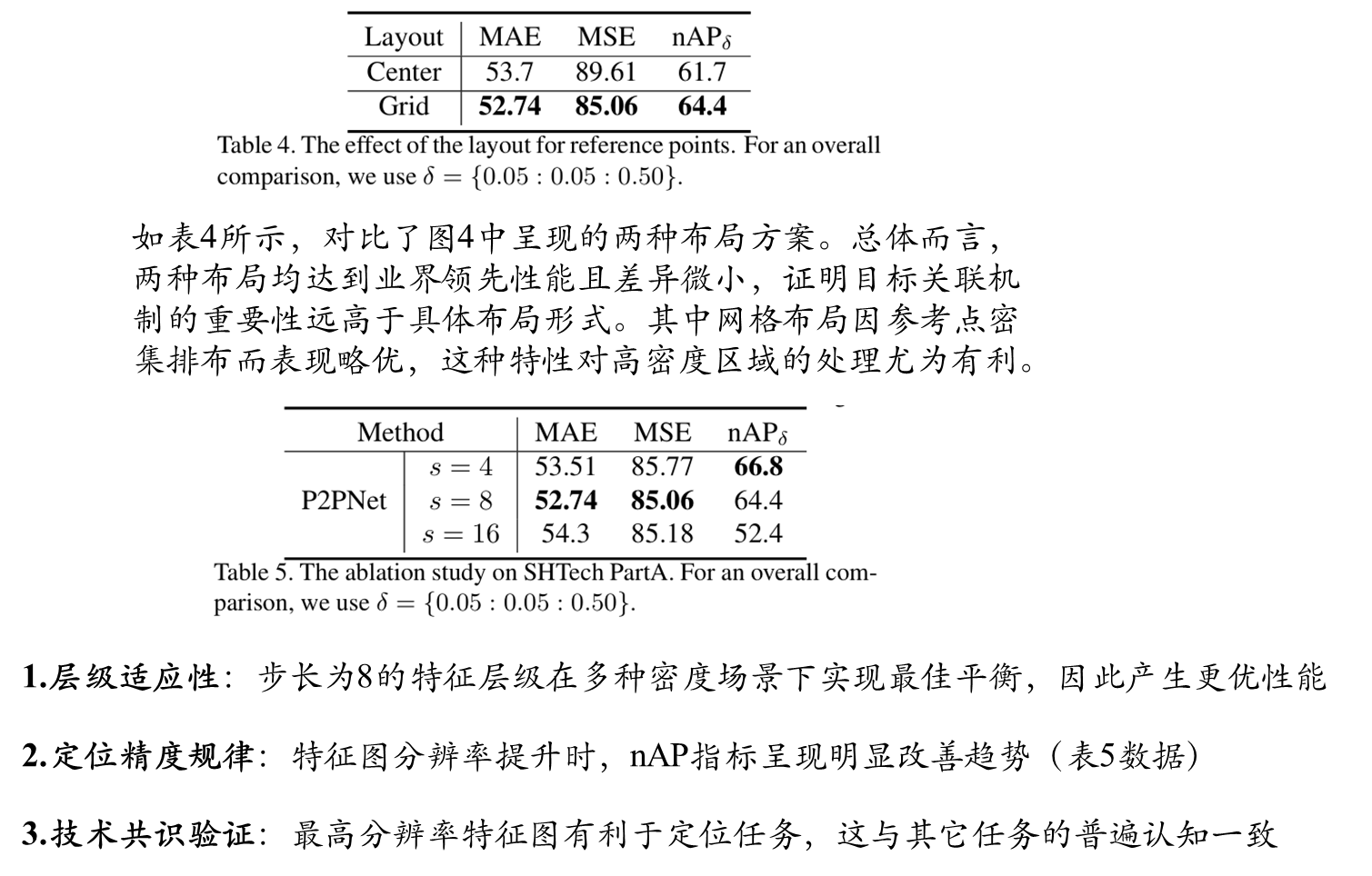
参考点网格和中心布局方案
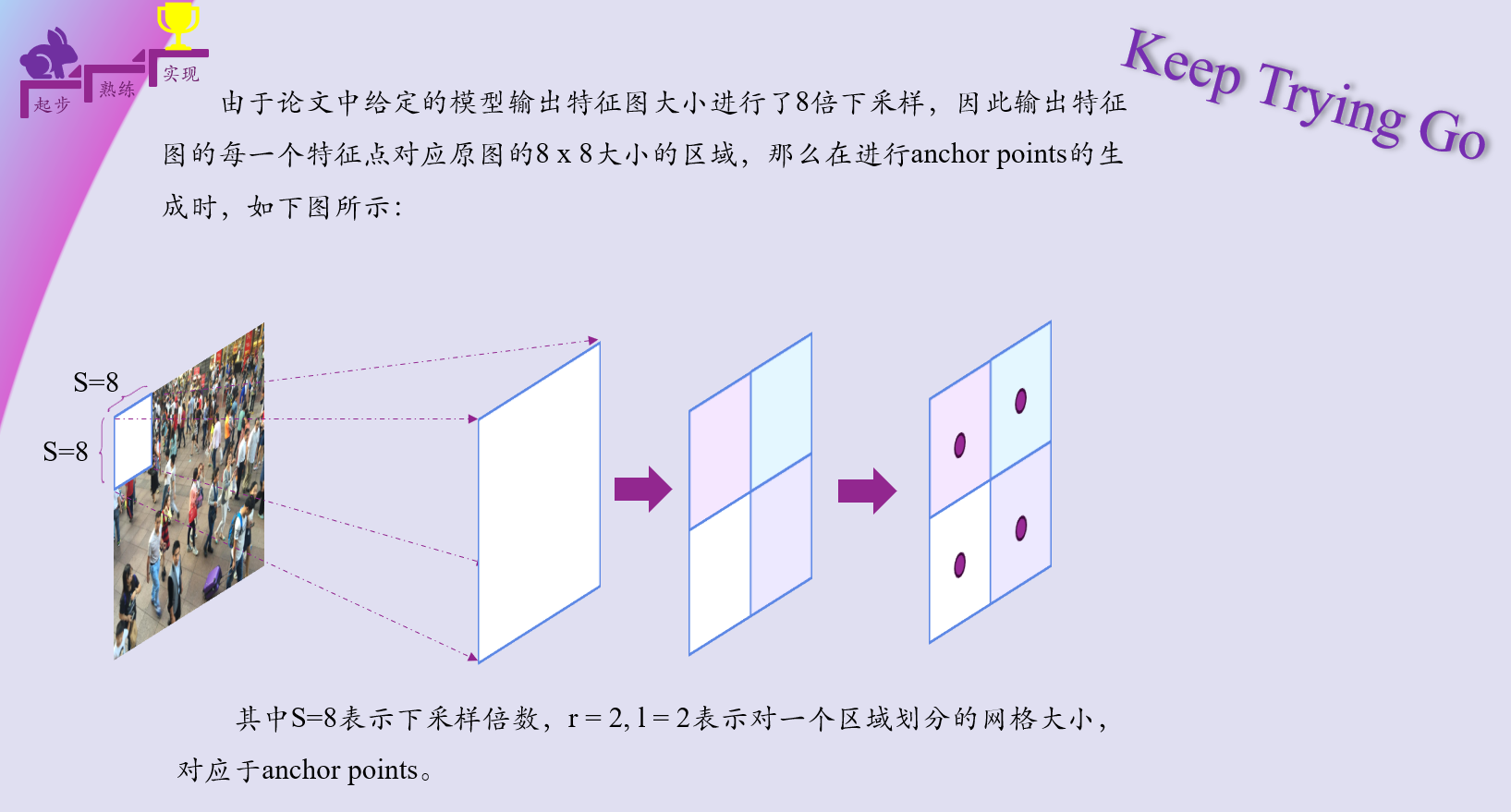
anchor points生成
分类和定位损失函数

综合实验
定位和统计实验
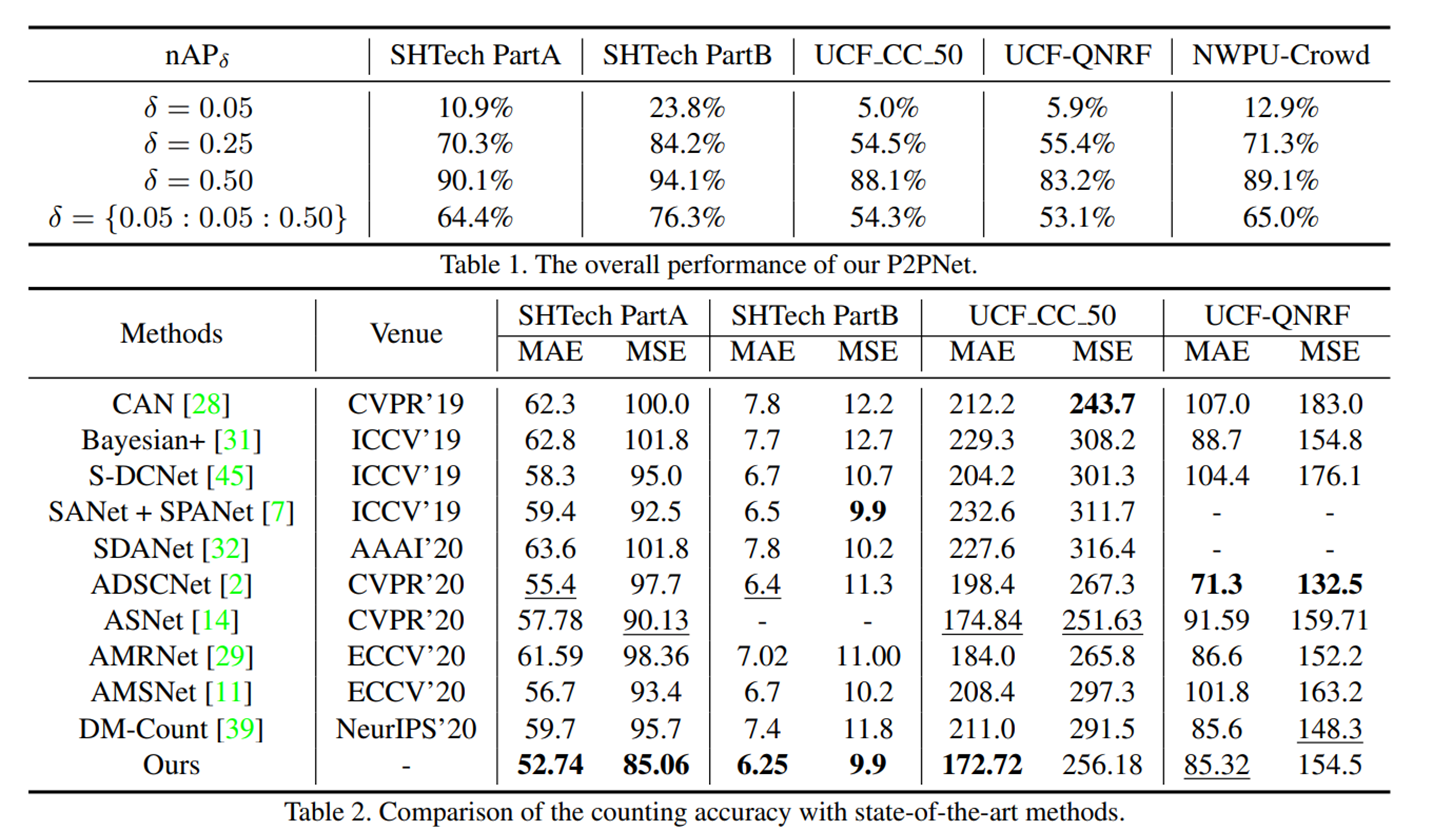
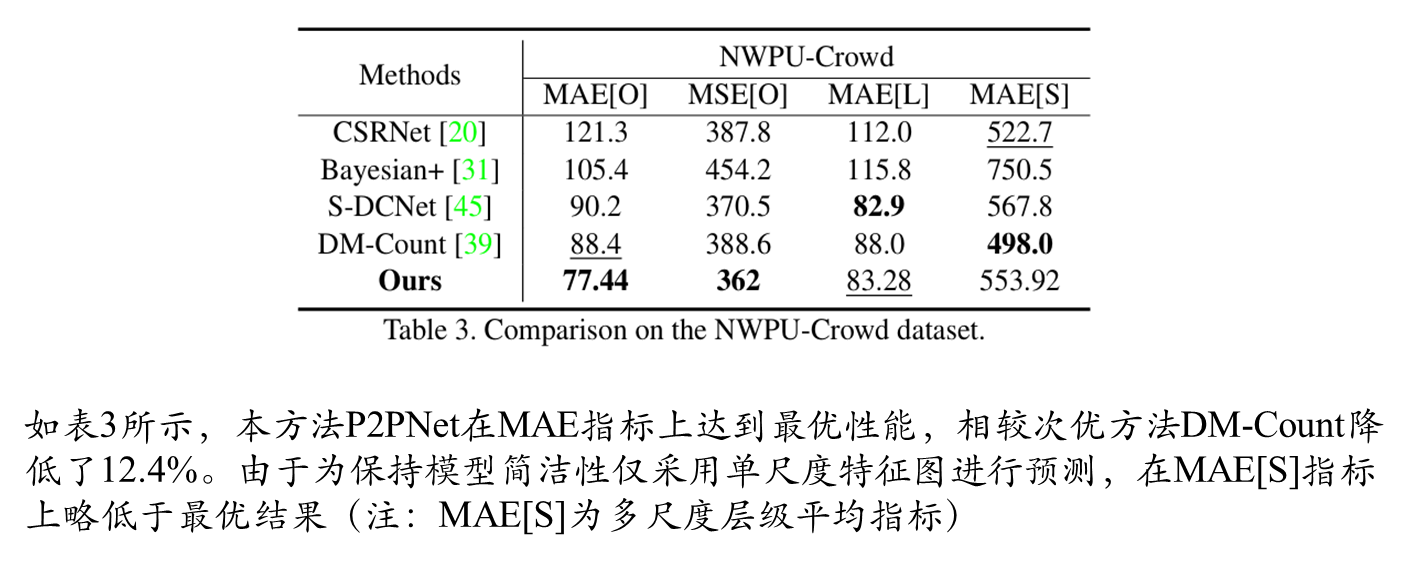
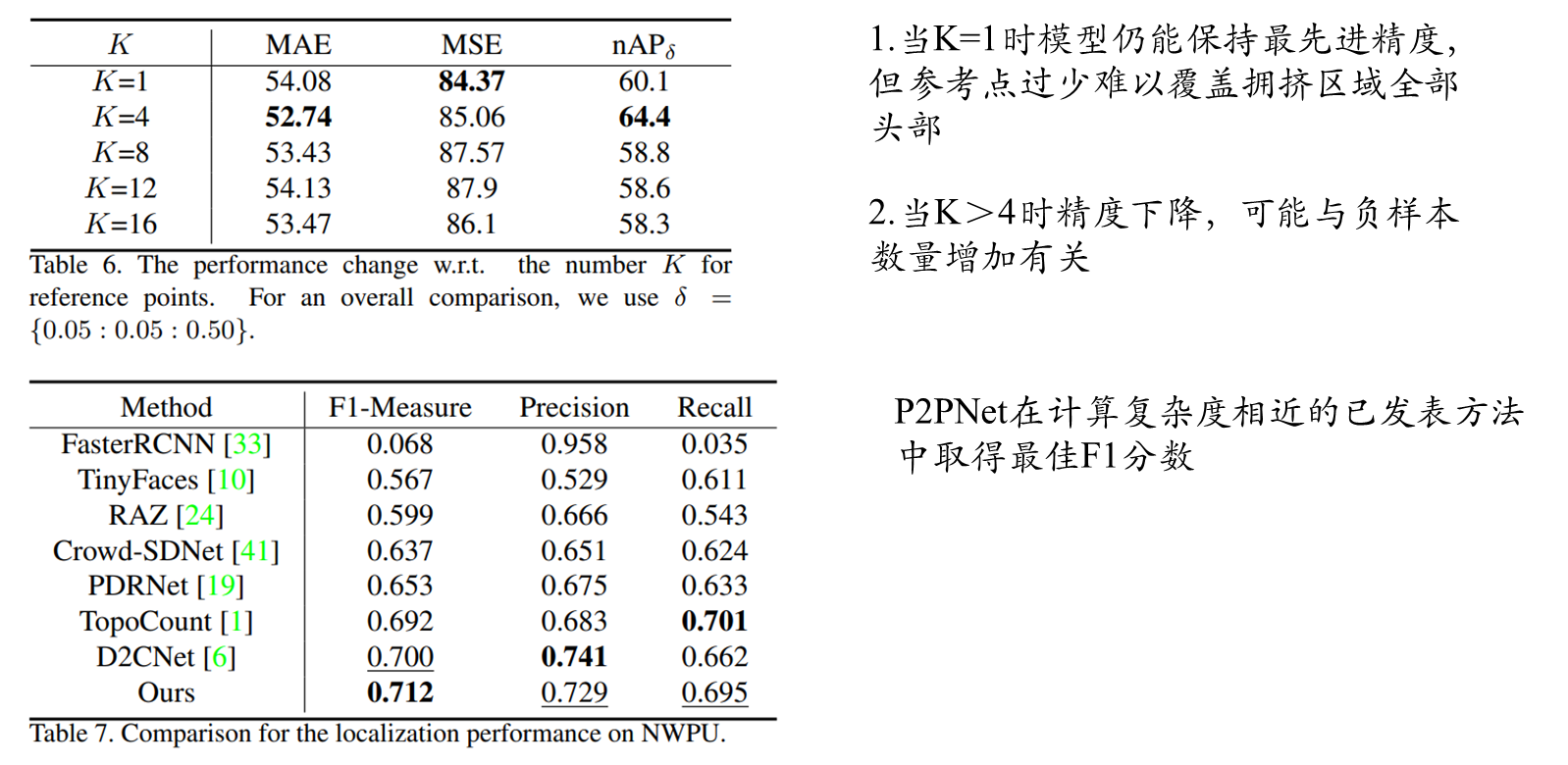
NWPU实验结果
消融实验结果
附加实验

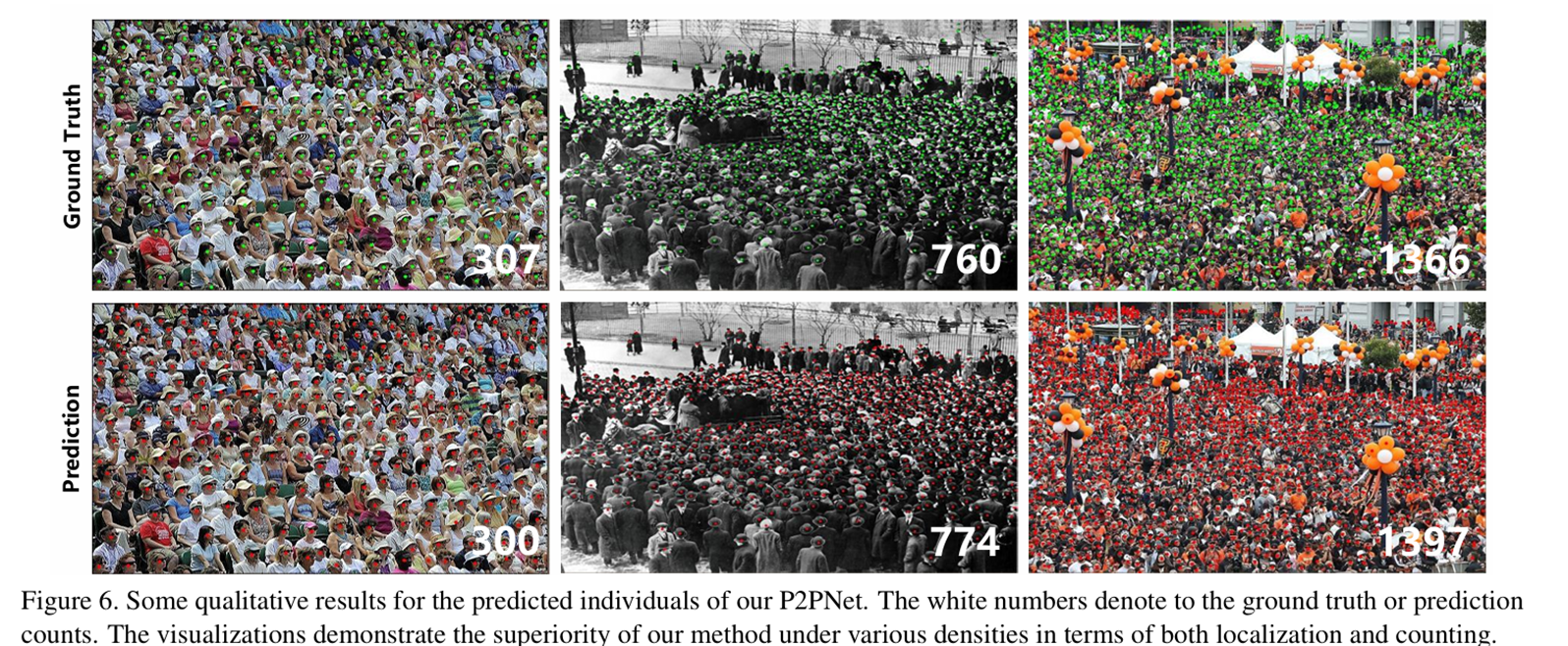
可视化结果分析






















 9551
9551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









