






论文下载:https://arxiv.org/pdf/2503.17984v1.pdf(https://arxiv.org/html/2503.17984v1#S4)
代码下载:https://github.com/syhien/taste_more_taste_better
论文下载:Segmentation Assisted U-shaped Multi-scale Transformer for Crowd Counting
论文下载:VMamba: Visual State Space Model
论文Distribution Matching for Crowd Counting中人群统计损失(C Loss),最优化传输损失(OT Loss)以及总的变化损失(TV Loss)
论文CrowdCLIP(基于CLIP的无监督人群计数模型)详解(PyTorch,Pytorch_Lighting)
MRC-Crowd论文下载:Semi-supervised crowd counting with contextual modeling: Facilitating holistic un derstanding of crowd scenes
抗造分类头参考论文Uniformity in heterogeneity: Diving deep into count interval partition for crowd counting:
人群计数数据集使用:人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
目录
精确回归头(Regression Head)和CUT损失函数
结构相似性损失(Structural Similarity Loss,SSIM Loss)
抗噪分类头(Anti-Noise Classification Head)
前置
全监督,半监督以及无监督在人群计数中都有所研究,但是相关的研究并不太多,大部分都是基于全监督并且是基于密度图的人群统计,当然还有很多其他的研究,这里就不一一例举出来了。本文要讲的是刚刚发表出来的基于半监督来做的,作者主要是从修复增强以及引入了新的网络架构mamba在人群计数中,mamba也是我目前第一次在人群计数中使用,当然作者也不是直接拿来用,而是基于mamba的骨干网络(backbone)来进行改进的,从实验的效果来看,这篇论文得到效果再大部分数据集上的效果还是可以的。

一 目的和方法
提出目的
半监督人群计数技术对于降低高密度场景下的标注成本至关重要。尽管已有若干基于伪标签的方法被提出,但如何高效精准地利用未标注数据仍具挑战性。
提出方法
本文提出名为“Taste More ,Taste Better"(TMTB)的创新框架,该框架从数据和模型双重视角进行优化:首先,开发了专为人群计数任务设计的背景区域修复数据增强技术,该方法在保持场景真实性的同时显著提升数据多样性;其次,引入视觉状态空间模型作为主干网络,以捕捉人群场景的全局上下文信息——这对极端拥挤、低光照及恶劣天气场景尤为重要。除传统的精确回归头外,还创新性地采用抗噪分类头提供相对宽松但更可靠的监督信号,以缓解回归头对人工标注噪声敏感的问题。
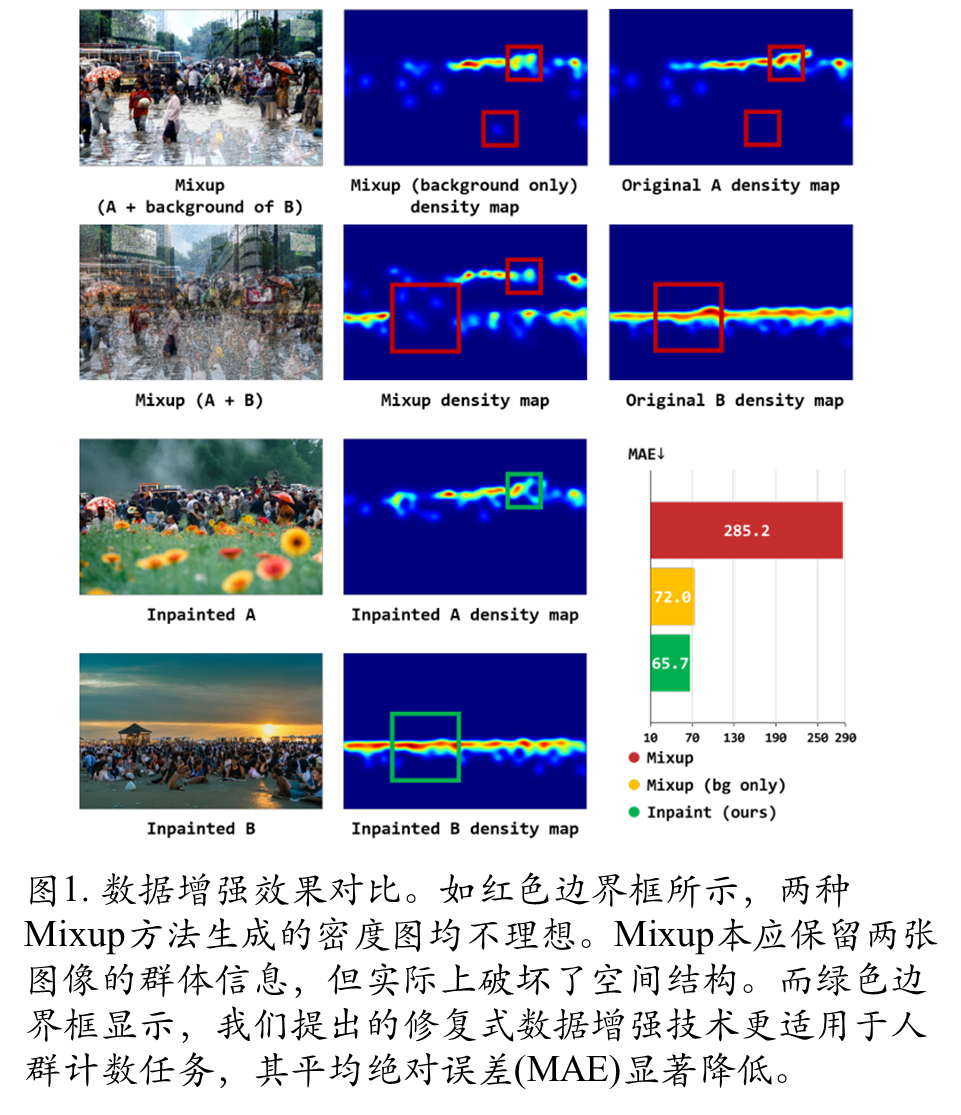
研究发现,引入相似但多样的训练样本能有效提升模型性能。现有数据增强技术虽然普遍有效,但会破坏人群场景的空间结构,导致密度图失真。专门设计了适用于人群计数的增强方法,同时发现传统卷积神经网络因过度关注局部细节而难以捕捉全局上下文,在极端拥挤或恶劣天气场景下表现不佳。基于这些发现,采用新型网络架构,配合优化的伪标签策略,显著提升了未标注数据的利用效率。
具体方法:本文提出了一种创新的半监督人群计数方法TMTB(多尝更优)。该方法设计了一种新颖的背景修复数据增强技术,在保持前景区域完整性的同时有效提升数据多样性。针对修复图像中存在的噪声干扰区域,采用视觉状态空间模型(VSSM)并引入抗噪分类分支,通过提供相对宽松但更精确的监督信号来优化数据利用效果。所提方法生成的密度图精度显著超越现有最优方法。实验结果表明,TMTB方法在多个基准数据集上取得突破性进展:在仅使用5%标注数据的JHU-Crowd数据集上,平均绝对误差降至67.0,这是该指标首次突破70.0大关。同时,该方法展现出卓越的泛化能力。
主要创新点包括:
- 首次指出现有数据增强方法会破坏人群场景空间结构,而传统CNN架构难以捕捉全局上下文,这是制约计数精度的关键瓶颈;
- 提出专为人群计数设计的背景修复增强技术,实现数据多样性与前景完整性的统一;
- 构建VSSM框架与抗噪分类分支的协同机制,通过“宽松但精确”的监督策略提升数据利用率;
- 在四项基准测试中全面超越现有方法,其中JHU-Crowd数据集在5%标注量下误差降低12.4%,并在跨数据集场景中展现出超越全监督方法的泛化性能
二 整体网络架构
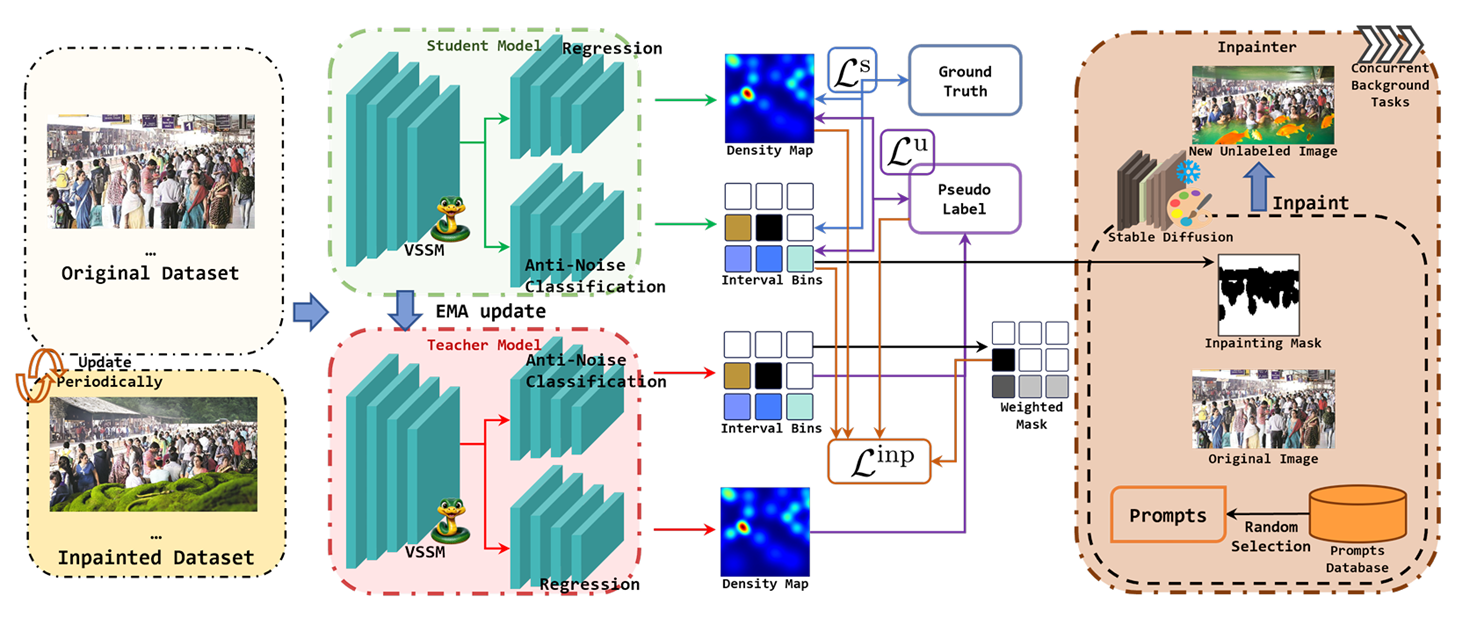
图2. TMTB方法的整体框架。该框架包含用于半监督学习的Mean Teacher结构、以VSSM为主干网络、用于预测掩码的分类分支以及用于修复增强的图像修复模块。修复过程会周期性执行,生成或更新修复后的图像。为过滤不可靠区域,教师模型根据修复图像的不一致性程度生成加权掩码,该掩码将应用于Linp。
教师模型为未标注数据(包括修复图像)生成伪标签,学生模型则对标注数据及经过强增强的未标注数据(包含修复图像)进行预测。 TMTB方法整体框架基于半监督学习领域广泛采用的Mean Teacher架构构建。教师模型与学生模型结构一致,其权重通过指数移动平均(EMA)策略根据学生模型权重进行更新。方法采用新型VSSM模型VMamba作为主干网络,替代传统CNN与Transformer架构。VMamba提取的图像特征将输入两个独立分支:用于预测图像密度图的计数分支,以及预测预定义计数区间索引的分类分支。
三 修复增强
核心思想是:利用图像修复技术生成具有挑战性的训练样本,通过修复区域的不确定性来提升模型的鲁棒性。



四 基于VSSM的抗噪分类方法
引入线性时间复杂度的VSSM模型,其特性包括:
通过状态空间机制在O(N)复杂度下建立全局依赖关系,克服传统Transformer的二次方计算瓶颈
动态调整状态转移矩阵,同步捕捉密集区域的细粒度特征与稀疏场景的宏观分布模式
时序状态传递特性可有效缓解因遮挡导致的局部信息丢失问题

精确回归头(Regression Head)和CUT损失函数

结构相似性损失(Structural Similarity Loss,SSIM Loss)
SSIM通过比较两幅图像在亮度(Luminance)、对比度(Contrast)和结构(Structure)三个方面的相似性,更符合人类视觉感知的评价指标。相比传统的MSE(均方误差),SSIM能更好地保留图像的结构信息。




import torch
import torch.nn.functional as F
from torch.autograd import Variable
import numpy as np
from math import exp
import pdb
def gaussian(window_size, sigma):
gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
return gauss/gauss.sum()
def create_window(window_size, channel):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
return window
def _ssim(img1, img2, window, window_size, channel, size_average = True, dilation=1):
kernel_size = window_size + (dilation - 1) * (window_size - 1) - 1
mu1 = F.conv2d(img1, window, padding = kernel_size//2, dilation = dilation, groups = channel)
mu2 = F.conv2d(img2, window, padding = kernel_size//2, dilation = dilation, groups = channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1*mu2
sigma1_sq = F.conv2d(img1*img1, window, padding = kernel_size//2, dilation = dilation, groups = channel) - mu1_sq
sigma2_sq = F.conv2d(img2*img2, window, padding = kernel_size//2, dilation = dilation, groups = channel) - mu2_sq
sigma12 = F.conv2d(img1*img2, window, padding = kernel_size//2, dilation = dilation, groups = channel) - mu1_mu2
C1 = 0.01**2
C2 = 0.03**2
ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
#print(ssim_map.shape)
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1).mean(1).mean(1)
class SSIM(torch.nn.Module):
def __init__(self, window_size = 11, size_average = True):
super(SSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.channel = 1
self.window = create_window(window_size, self.channel)
def forward(self, img1, img2):
# pdb.set_trace()
(_, channel, _, _) = img1.size()
if channel == self.channel and self.window.data.type() == img1.data.type():
window = self.window
else:
window = create_window(self.window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
self.window = window
self.channel = channel
return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
def cal_ssim(img1, img2, window_size = 11, size_average = True):
(_, channel, _, _) = img1.size()
window = create_window(window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
return _ssim(img1, img2, window, window_size, channel, size_average)
TV损失(Total Variation, TV)
论文Distribution Matching for Crowd Counting中人群统计损失(C Loss),最优化传输损失(OT Loss)以及总的变化损失(TV Loss)

注:这里的z表示向量二值map点标注,z_hat表示网络预测输出的密度图向量。

self.tv_loss = nn.L1Loss(reduction='none').to(self.device)
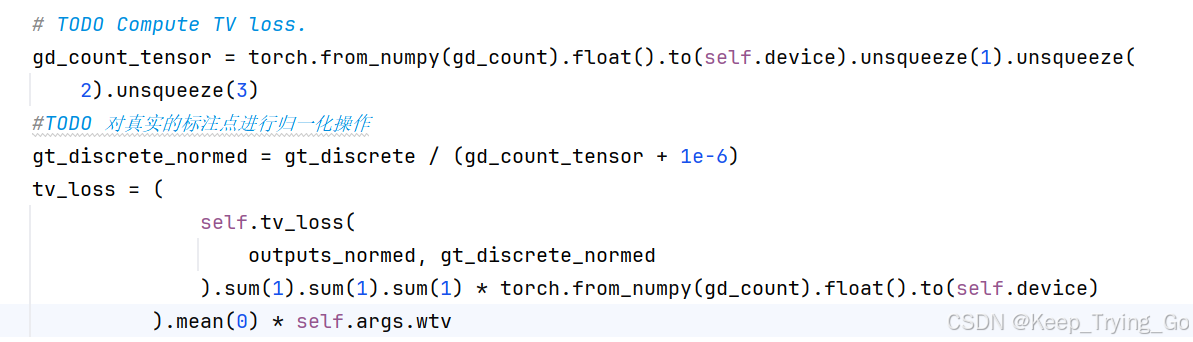
注:这里的代码实现和公式是对应的,并且其中的输出密度图和真实标注点都是经过归一化之后的,其中gd_count_tensor表示人群头部点标注信息,gt_discrete表示将人群头部的二维坐标点映射到一维表示的结果。
抗噪分类头(Anti-Noise Classification Head)

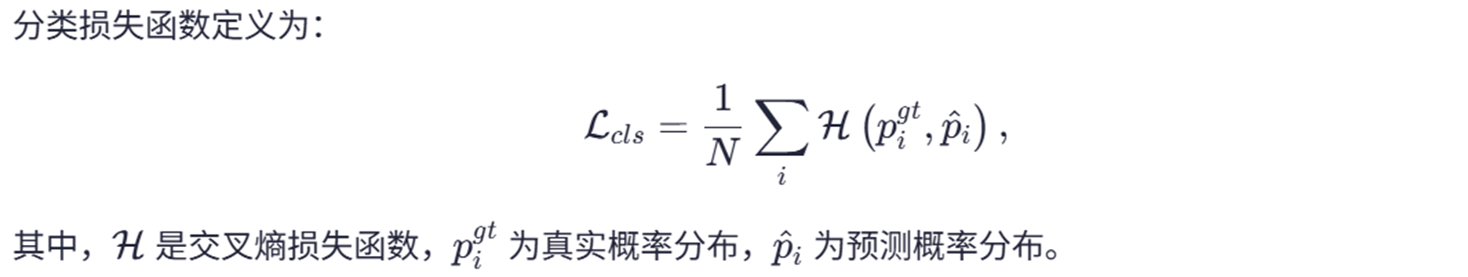
五 损失函数

六 整体训练流程



def train(self):
args = self.args
for epoch in range(self.start_epoch, args.epochs):
logging.info(
"-" * 50 + "Epoch:{}/{}".format(epoch, args.epochs - 1) + "-" * 50
)
self.epoch = epoch
self.update_inpaint_weight()
#TODO 训练
self.train_epoch()
#TODO 验证
if self.epoch >= args.start_val and self.epoch % args.val_epoch == 0:
self.val_epoch()
if (
self.epoch >= args.start_inpaint
and (self.epoch - args.start_inpaint) % args.inpaint_epoch == 0
):
logging.info("Start Inpainting at epoch {}".format(self.epoch))
self.inpaint_train()
# todo 使用 subprocess.Popen 启动新进程运行 inpainter.py 脚本
_ = subprocess.Popen(
[
"python",
"inpainter.py",
str(os.path.join(self.save_dir, "raw")),
str(os.path.join(self.save_dir, "inpaint")),
]
)
def inpaint_train(self):
self.inpaint_tasks = []
#TODO 无限循环遍历给定的序列
host_iter = itertools.cycle(self.inpaint_hosts)
for inputs, _, names in self.inpaint_dataloader:
name = names[0]
#TODO 针对每一张图像都要生成一个文件保存
os.makedirs(os.path.join(self.save_dir,"raw",name,),exist_ok=True,)
#TODO 判断当前的输入图像是否大于(2048. 2048),并进行等比例的缩放
if inputs.size(2) > 2048 or inputs.size(3) > 2048:
#TODO 大于的话就要进行同比率的缩放高宽了
resize_ratio = 2048 / max(inputs.size(2), inputs.size(3))
inputs = F.interpolate(
inputs,
size=(
int(inputs.size(2) * resize_ratio),
int(inputs.size(3) * resize_ratio),
),
mode="bilinear",
)
#TODO 获得当前图像的分类分数
with torch.no_grad():
inputs = inputs.to(self.device)
_, cls_score = self.model(inputs)
#TODO 获得最大预测类别对应索引,并且是等于0的索引,
# 将预测为类别0的区域标记为需要修复的区域(通常表示背景或低密度区域)
mask = torch.argmax(cls_score, dim=1, keepdim=True) == 0
#TODO 对掩码进行上采样
mask = F.interpolate(
mask.float(), size=(inputs.size(2), inputs.size(3)), mode="nearest"
)
#TODO mask转换为图像保存
mask = mask.squeeze(0).cpu().numpy() * 255
mask = Image.fromarray(mask.squeeze(0).astype(np.uint8), mode="L")
mask.save(os.path.join(self.save_dir, "raw", name, name + "_mask.jpg"))
#TODO 保存原图
img = tensorToImage(inputs)
img.save(os.path.join(self.save_dir, "raw", name, name + ".jpg"))
host = next(host_iter)
#todo 负面prompt
prompt = random.choice(self.inpaint_prompts)
neg_prompt = "disfigured face, broken limbs, deformed body parts"
json_data = {"host": host, "prompt": prompt, "negative_prompt": neg_prompt}
with open(
os.path.join(self.save_dir, "raw", name, "inpaint.json"), "w"
) as f:
json.dump(json_data, f)
def train_epoch(self):
epoch_reg_loss = AverageMeter()
epoch_cls_loss = AverageMeter()
epoch_unsupervised_loss = AverageMeter()
epoch_inpaint_loss = AverageMeter()
epoch_mae = AverageMeter()
epoch_mse = AverageMeter()
epoch_start = time.time()
self.model.train()
self.ema_model.train()
for _, (
w_inputs, # 图像的基本增强
s_inputs, # 图像的更强增强
den_map,
labels,
_,
w_inpaints, # 修复图像的基本增强
s_inpaints, # 修复图像的更强增强
inpaints, # 原始的修复图像
) in enumerate(self.train_loader):
w_inputs = w_inputs.to(self.device)
s_inputs = s_inputs.to(self.device)
gt_den_map = den_map.to(self.device)
# 把部分修复图像对应的索引设置为false
inpaints = limit_true_count(inpaints, 2)
w_inpaints = w_inpaints[inpaints].to(self.device)
s_inpaints = s_inpaints[inpaints].to(self.device)
# 显式控制在该代码块范围内是否计算梯度
with torch.set_grad_enabled(True):
self.global_step += 1
N = w_inputs.size(0)
#TODO 有标签图像数量
N_l = w_inputs[labels].size(0)
#TODO 无标签图像数量
N_u = w_inputs.size(0) - N_l
#TODO 有标签图像经过模型之后的预测结果以及分类结果
pred, cls_score = self.model(w_inputs[labels])
################Supervised Loss###############
reg_loss = get_reg_loss(pred, gt_den_map[labels])
epoch_reg_loss.update(reg_loss.item(), N_l)
#TODO 通过真实的密度图获得一个分类的掩码mask_map
gt_cls_map = den2cls(gt_den_map, self.label_count)
#TODO 计算分类损失
cls_loss = self.cls_loss(cls_score, gt_cls_map[labels]).mean()
epoch_cls_loss.update(cls_loss.item(), N_l)
loss = cls_loss + reg_loss
###############UnSupervised Loss#################
"""
稳定性:教师模型通过指数移动平均更新,参数变化更平滑
一致性:提供稳定的伪标签目标,减少训练震荡
抗过拟合:避免学生模型过度适应噪声数据
"""
self.update_ema_model(
model=self.model,
ema_model=self.ema_model,
alpha=self.args.ema_decay,
global_step=self.global_step
)
#TODO 用于生成掩码区域
masks = repeat_fun(N_u, self.mask_generator).to(self.device)
input_mask = (
1
- masks.repeat_interleave(8, 1) # 在高度维度重复8次
.repeat_interleave(8, 2)# 在宽度维度重复8次
.unsqueeze(1)
.contiguous()
) # TODO masked area=0, unmasked = 1
masks = masks.unsqueeze(1) # masked area =1, unmasked = 0
#TODO 对于强增强输入图片,无监督学生模型预测结果
u_s_reg, u_s_cls = self.model(s_inputs[labels == 0] * input_mask)
#TODO 教师模型预测输出,通过EMA教师模型检测不一致区域
with torch.no_grad():
u_t_reg, u_t_cls = self.ema_model(w_inputs[labels == 0])
u_t_cls = u_t_cls.detach()
u_t_reg = u_t_reg.detach()
# 如果当前使用了图像修复增强技术的话
if any(inpaints):
#使用eam model计算修复图像的弱增强和强增强版本的结果,并计算之间预测结果的差异来计算不一致性损失
i_w_t_reg, i_w_t_cls = self.ema_model(w_inpaints)
_, i_s_t_cls = self.ema_model(s_inpaints)
# 计算不一致性的分类层对应的索引
w_level = torch.argmax(i_w_t_cls, dim=1, keepdim=True)
s_level = torch.argmax(i_s_t_cls, dim=1, keepdim=True)
#TODO 这里对应论文的公式2,计算不同级别的不一致性掩码
t0_mask = (w_level == s_level).float() # 完全一致
t1_mask = (torch.abs(w_level - s_level) == 1).float() # 轻微不一致
t2_mask = (torch.abs(w_level - s_level) == 2).float() # 明显不一致
"""
w_t0:一致区域,权重最大(信任教师预测)
w_t1:轻微不一致,中等权重(需要进一步学习)
w_t2:明显不一致,权重最小(可能包含噪声)
"""
level_mask = (
t0_mask * self.w_t0
+ t1_mask * self.w_t1
+ t2_mask * self.w_t2
)
if any(inpaints):
i_s_s_reg, i_s_s_cls = self.model(s_inpaints)
# 教师模型预测弱增强的修复图片和学生模型预测强增强的修复图片计算正则化和分类损失
# 正则化损失和论文中指出的公式不太一致
i_reg_loss = (
nn.L1Loss(reduction="none")(i_s_s_reg, i_w_t_reg) * level_mask
).sum() / (level_mask.sum() + 1e-5)
i_cls_loss = (
nn.L1Loss(reduction="none")(
i_s_s_cls.softmax(dim=1), i_w_t_cls.softmax(dim=1)
)
* level_mask
).sum() / (level_mask.sum() + 1e-5)
i_loss = i_reg_loss + i_cls_loss
epoch_inpaint_loss.update(i_loss.item(), sum(inpaints))
# 利用学生模型预测强增强原始图片和教师模型预测弱增强的原始图片输出的预测密度图计算无监督损失
u_mreg_loss = (
nn.L1Loss(reduction="none")(u_s_reg, u_t_reg) * masks
).sum() / (masks.sum() + 1e-5)
u_mcls_loss = (
nn.L1Loss(reduction="none")(
u_s_cls.softmax(dim=1), u_t_cls.softmax(dim=1)
) * masks
).sum() / (masks.sum() + 1e-5)
cons_loss = u_mreg_loss + u_mcls_loss
epoch_unsupervised_loss.update(cons_loss.item(), N_u)
##################总损失 = 有监督损失 + 无监督一致性损失 + 修复增强损失 ################
loss += cons_loss * self.ramup(self.epoch)
loss += i_loss * self.ramup(self.epoch) if any(inpaints) else 0
#################思考: 为什么整个过程中学生模型输入的都是强增强版本的图像,而教师模型输入的都是弱增强版本的图像#########
"""
论文给出的答案:The EMA teacher model generates pseudo-labels
based on the prediction of unlabeled data with weak augmentation.
The student model makes predictions based on the strong augmentation version.
The error loss between the two predictions is calculated as the consistency loss.
"""
# 计算MAE和MSE
gt_counts = (
torch.sum(gt_den_map[labels].view(N_l, -1), dim=1)
.detach()
.cpu()
.numpy()
)
pred_counts = (
torch.sum(pred.view(N_l, -1), dim=1).detach().cpu().numpy()
)
diff = pred_counts - gt_counts
epoch_mae.update(np.mean(np.abs(diff)).item(), N)
epoch_mse.update(np.mean(diff * diff), N)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
logging.info(
"Epoch {} Train, reg:{:.4f}, cls:{:.4f}, unsupervised:{:.4f}, inpaint:{:.4f} mae:{:.2f}, mse:{:.2f}, Cost: {:.1f} sec ".format(
self.epoch,
epoch_reg_loss.getAvg(),
epoch_cls_loss.getAvg(),
epoch_unsupervised_loss.getAvg(),
epoch_inpaint_loss.getAvg(),
epoch_mae.getAvg(),
np.sqrt(epoch_mse.getAvg()),
(time.time() - epoch_start),
)
)
if self.epoch % 5 == 0:
model_state_dict = self.model.state_dict()
ema_model_state_dict = self.ema_model.state_dict()
save_path = os.path.join(self.save_dir, "{}_ckpt.tar".format(self.epoch))
torch.save(
{
"epoch": self.epoch,
"optimizer_state_dict": self.optimizer.state_dict(),
"model_state_dict": model_state_dict,
"ema_model_state_dict": ema_model_state_dict,
"global_step": self.global_step,
},
save_path,
)
self.save_list.append(save_path)
def val_epoch(self):
epoch_start = time.time()
self.model.eval()
epoch_res = []
for inputs, gt_counts, _ in self.val_loader:
inputs = inputs.to(self.device)
with torch.set_grad_enabled(False):
# TODO inputs are images with different sizes
b, c, h, w = inputs.shape
h, w = int(h), int(w)
assert b == 1, "the batch size should equal to 1 in validation mode"
input_list = []
c_size = 2048
#TODO 对原图划分为patch块输入到模型中
if h >= c_size or w >= c_size:
h_stride = int(ceil(1.0 * h / c_size))
w_stride = int(ceil(1.0 * w / c_size))
h_step = h // h_stride
w_step = w // w_stride
for i in range(h_stride):
for j in range(w_stride):
h_start = i * h_step
if i != h_stride - 1:
h_end = (i + 1) * h_step
else:
h_end = h
w_start = j * w_step
if j != w_stride - 1:
w_end = (j + 1) * w_step
else:
w_end = w
input_list.append(
inputs[:, :, h_start:h_end, w_start:w_end]
)
with torch.set_grad_enabled(False):
pre_count = 0.0
for _, input in enumerate(input_list):
output = self.model(input)[0]
pre_count += torch.sum(output)
res = gt_counts[0].item() - pre_count.item()
epoch_res.append(res)
else:
with torch.set_grad_enabled(False):
outputs = self.model(inputs)[0]
res = gt_counts[0].item() - torch.sum(outputs).item()
epoch_res.append(res)
epoch_res = np.array(epoch_res)
mse = np.sqrt(np.mean(np.square(epoch_res)))
mae = np.mean(np.abs(epoch_res))
logging.info(
"Epoch {} Val, MAE: {:.2f}, MSE: {:.2f} Cost {:.1f} sec".format(
self.epoch, mae, mse, (time.time() - epoch_start)
)
)
model_state_dict = self.model.state_dict()
if (mae + mse) < (self.best_mae + self.best_mse):
self.best_mae = mae
self.best_mse = mse
torch.save(
model_state_dict,
os.path.join(self.save_dir, "best_model_{}.pth".format(self.epoch)),
)
logging.info(
"Save best model: MAE: {:.2f} MSE:{:.2f} model epoch {}".format(
mae, mse, self.epoch
)
)
print(
"Best Result: MAE: {:.2f} MSE:{:.2f}".format(self.best_mae, self.best_mse)
)七 实验部分

综合实验结果分析
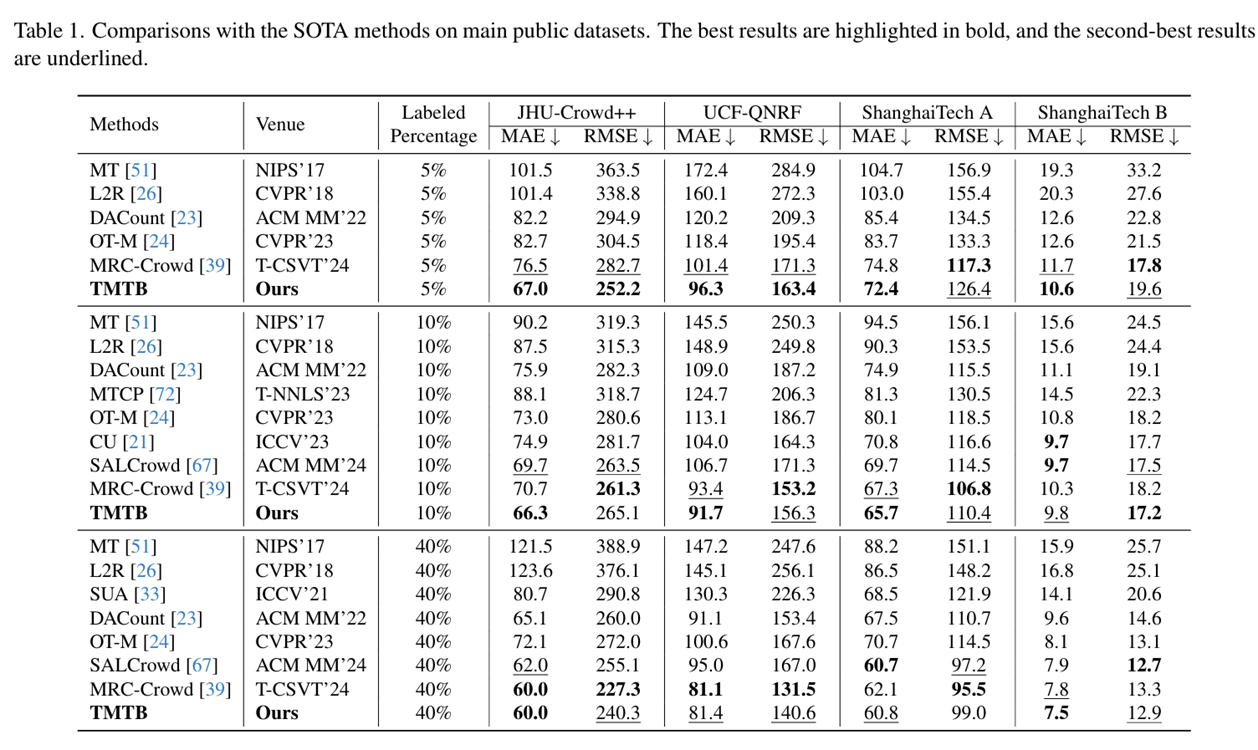
综合分析:仅使用5%有标注数据时,TMTB在JHU-Crowd++上取得最低平均绝对误差(MAE)67.0,在UCF-QNRF上为96.3,在ShanghaiTech A上为72.4,在ShanghaiTech B上为10.6,表现最佳。其在JHU-Crowd++上的结果不仅超过相同有标注数据量的最先进方法(SOTA),还表明在10%标注设置下TMTB仍具优势,凸显其高效利用标注数据和卓越准确性。10%有标注数据设置时,TMTB在JHU-Crowd++上MAE为66.3,在UCF-QNRF上为91.7,在ShanghaiTech A上为65.7,进一步展现泛化能力和有效性。40%有标注数据时,TMTB取得有竞争力结果,在JHU-Crowd++上匹配最低MAE 60.0,在ShanghaiTech B上将MAE降至最低7.5,在其他数据集上也保持强劲性能。
数据增强策略比较
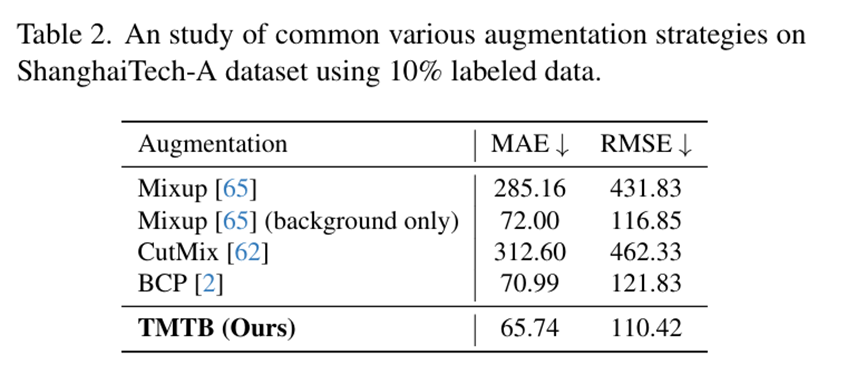
数据增强策略有效性研究通过对比实验验证了所提出的图像修复增强方法的优势。在仅含10%标注数据的ShanghaiTech A数据集上,该方法与Mixup、CutMix和BCP等现有增强策略进行了系统比较。实验结果表明,当Mixup和CutMix应用于整幅图像时会显著降低模型性能,主要原因是破坏了前景与背景区域的完整性,导致增强后的图像信息缺失且难以学习。这充分证明了在人群计数任务中保持区域完整性的重要性。值得注意的是,仅对背景区域应用Mixup时性能有所提升,该方式与图像修复增强策略类似,都能在保持前景区域完整的同时增强背景区域,但其背景区域采样自原始数据集,多样性可能不足。BCP作为最近提出的医学图像分割双向增强策略,在人群计数任务中虽能提升性能,但与最先进方法相比仍存在明显差距。这些对比结果凸显了所提图像修复增强策略在保持区域完整性和增强多样性方面的独特优势。
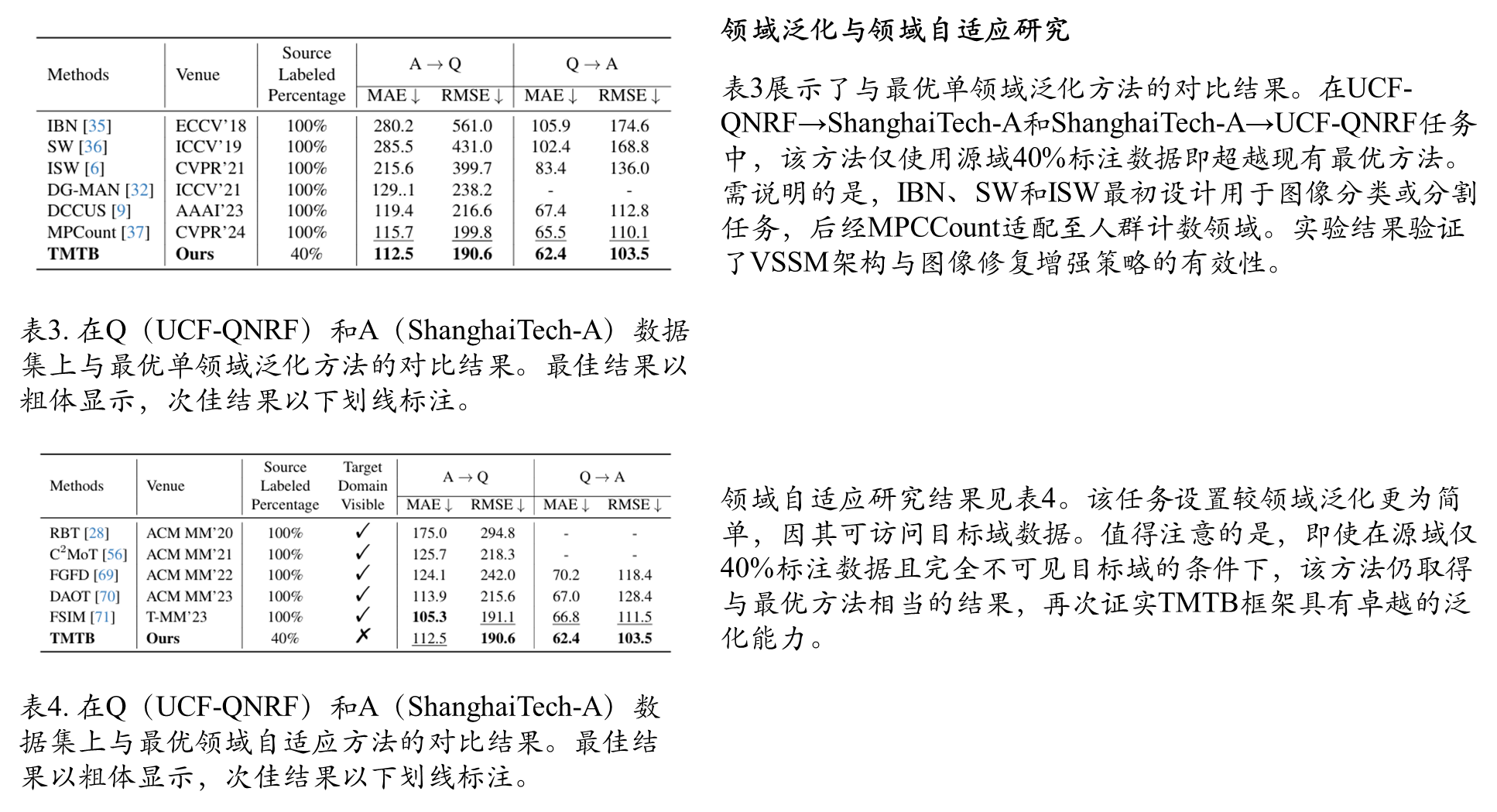
领域泛化和领域自适应比较
消融实验分析

可视化结果



















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









