




视频讲解1:Bilibili视频讲解
论文下载:https://arxiv.org/abs/2407.04619
代码下载:https://github.com/niki-amini-naieni/CountGD/
主页:https://www.robots.ox.ac.uk/~vgg/research/countgd/
https://github.com/KeepTryingTo
基于Zero-Shot的计数算法详解(T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting)
统一的人群计数训练框架(PyTorch)——基于主流的密度图模型训练框架
算法VLCount详解(VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting)
人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
基于Zero-Shot的目标计数算法详解(Open-world Text-specified Object Counting)
基于zero-shot目标计数方法详解(Zero-Shot Object Counting)
基于Transformer的目标统计方法(CounTR: Transformer-based Generalised Visual Counting)
基于zero-shot目标统计算法详解(Zero-shot Object Counting with Good Exemplars)
本文提出了一种新型多模态零样本目标计数框架,通过三重提示(文本/视觉/混合)解决现有方法提示方式单一的问题。创新性地采用基于Grounding DINO的增强架构,结合自注意力、交叉注意力和层注意力机制实现深度特征融合。实验表明,该方法在灵活性和准确性上均优于传统视觉示例或纯文本方法,特别是通过动态查询机制实现了输入内容自适应的区域关注。研究有效克服了现有技术在提示方式、架构设计和特征融合等方面的局限性,为零样本目标计数提供了更通用的解决方案。
目录

现有方法的局限性
1.提示方式单一化限制
视觉示例方法的局限性:虽然基于视觉示例的方法(如LOCA、CounTR)在准确性上领先,但需 要用户提供边界框标注,在实际应用中不够灵活仅限于图像内已有的视觉信息,无法利 用先验知识或语义理解
文本提示方法的局限性:文本描述往往不够精确,难以准确描述物体的视觉特征,当前文本方法 (如CounTX、CLIP-Count)的准确率显著低于视觉示例方法,无法充分利用图像特有的 视觉上下文(如光照、视角等)
2. 架构设计的局限性
两阶段方法的复杂性:如DAVE需要依赖另一个基于视觉示例的计数模型,流程复杂
特征融合不充分:现有方法对文本和视觉特征的融合较为简单,没有充分发挥多模态互补优势
基础模型限制:多数方法基于CLIP等模型,缺乏对检测任务的专门优化
提出的方法
1. 多模态提示统一架构
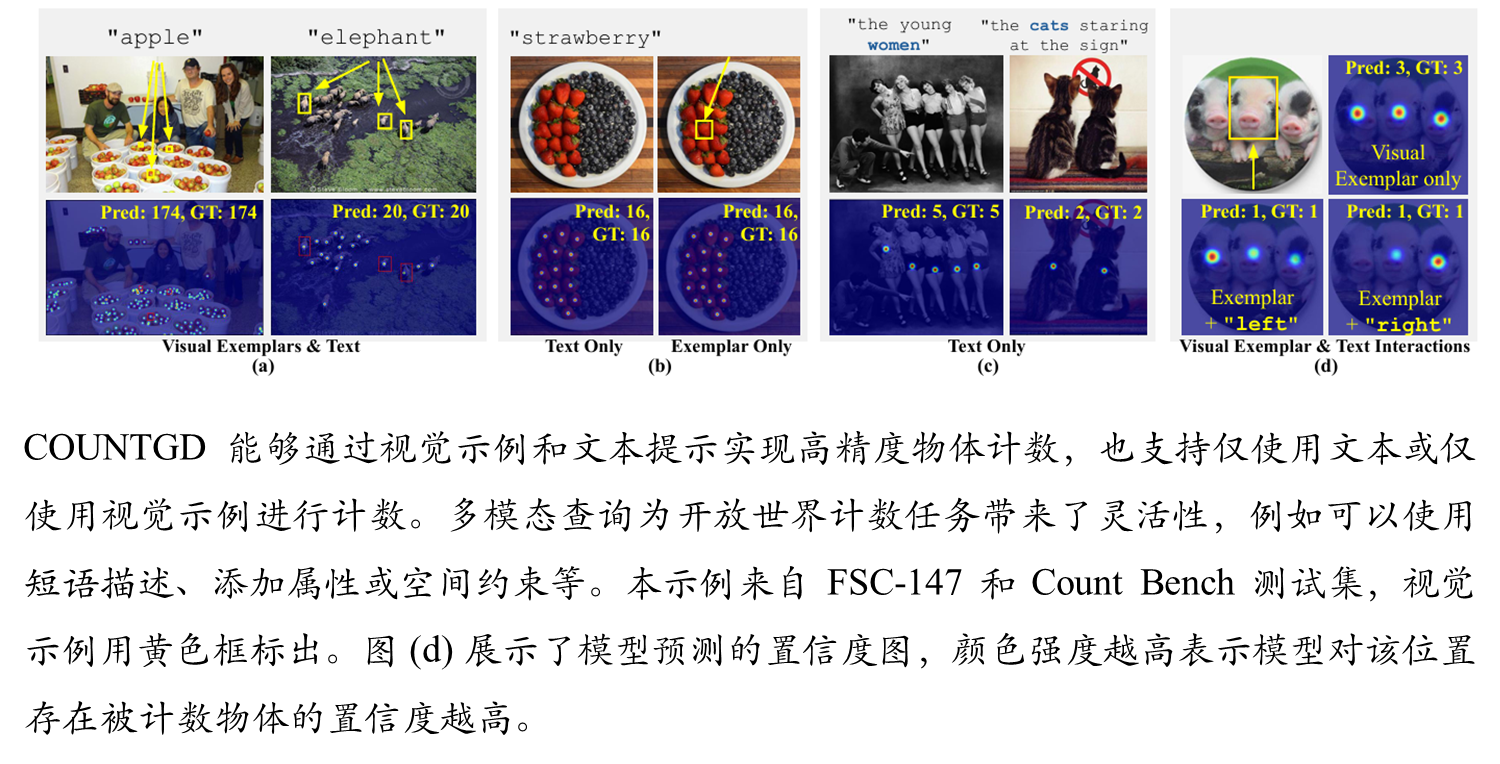
三重提示支持:支持文本提示、视觉示例提示以及两者结合的混合提示;灵活的应用场景:仅有文本描述时:使用类别名称或属性描述;仅有视觉示例时:提供边界框标注;两者兼具时:实现更精确的对象指定
2.基于Grounding DINO的增强架构
图像编码器:采用Swin-B Transformer,生成多尺度空间特征图;视觉示例编码:通过RoIAlign从图像特征中提取示例区域特征;文本编码器:基于BERT的文本Transformer
3. 特征增强器的创新设计
自注意力机制:在视觉示例token和文本token之间进行特征融合;交叉注意力机制:将融合后的特征与图像patch token进行交互;层注意力块:深度建模多模态关系
4. 语言与视觉引导的查询选择
相似度驱动的查询选择:选择与融合特征zv,t相似度最高的k个图像patch;动态查询机制:根据输入内容自适应调整关注区域
具体方法
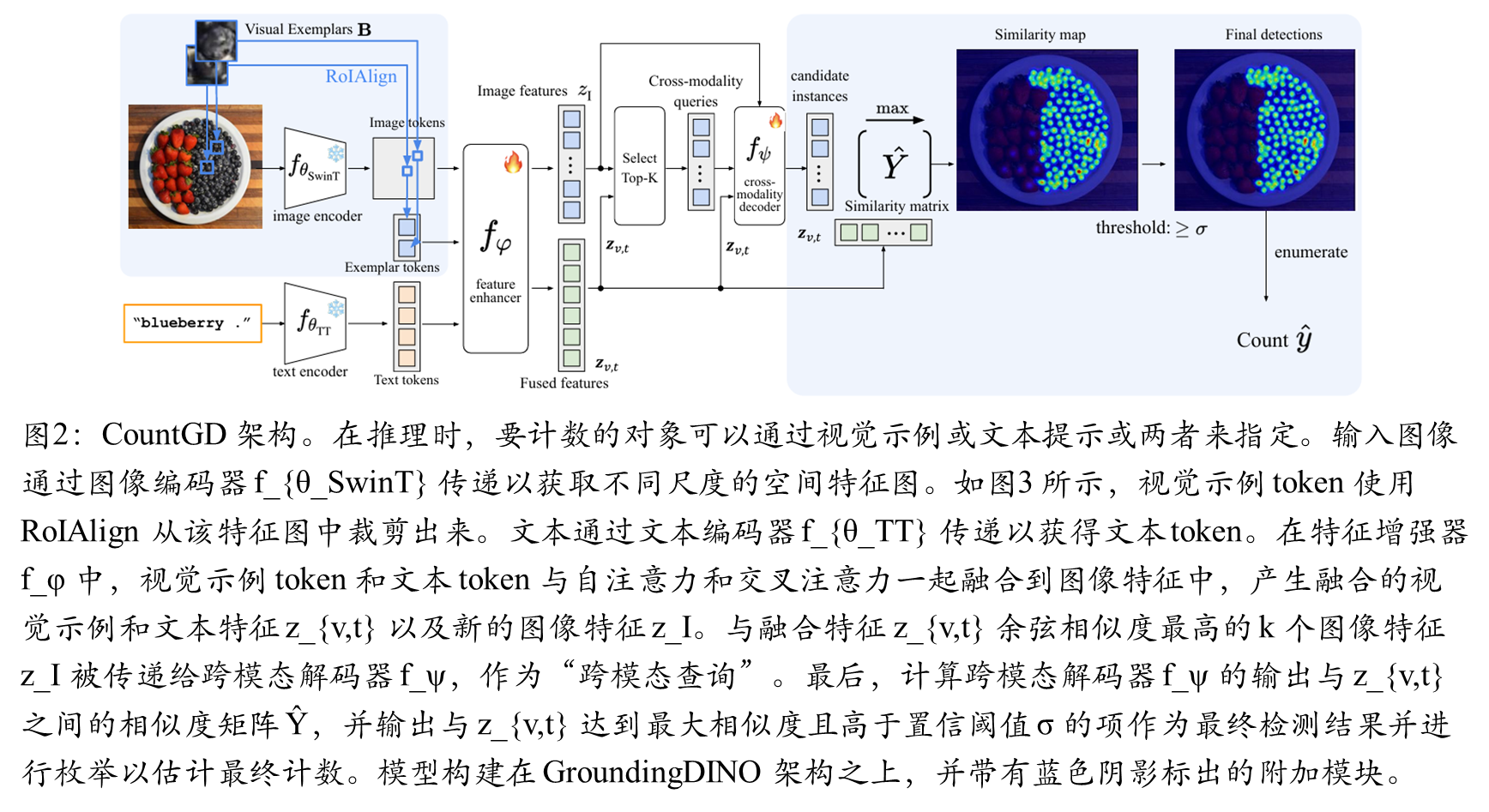
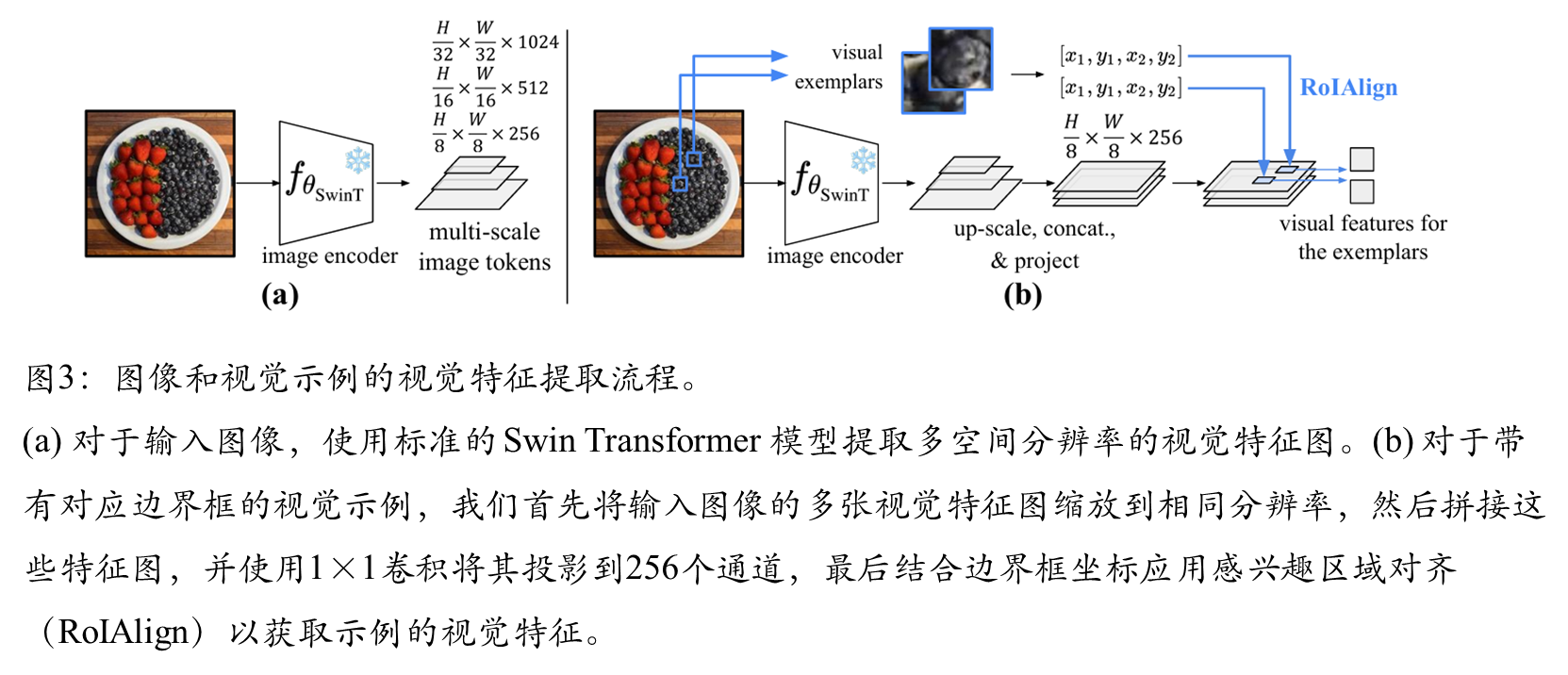
图像和文本编码器

特征增强

语言和视觉样例指导query选择

跨模态解码器


训练和推理阶段

实验结果
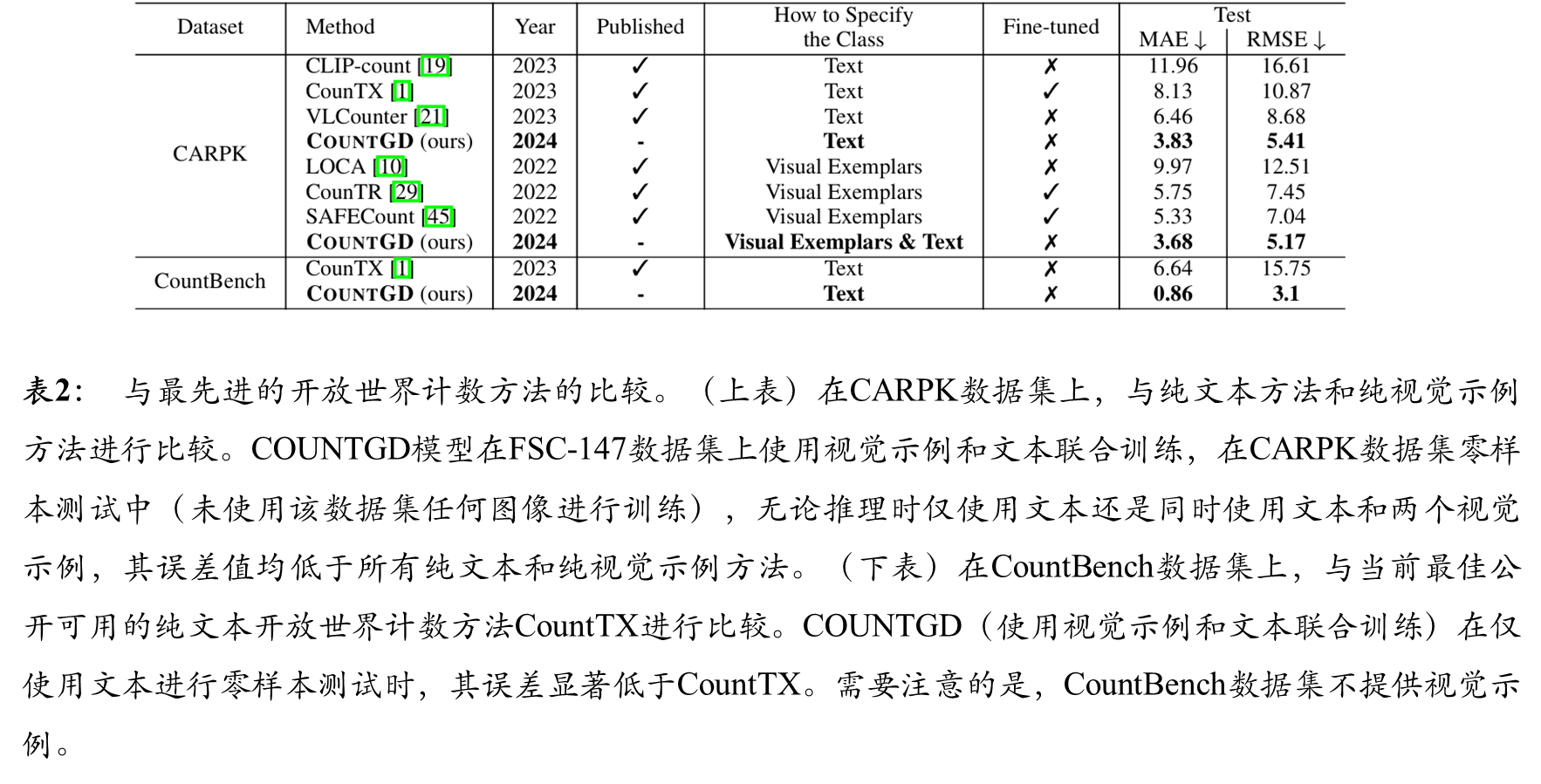
综合结果
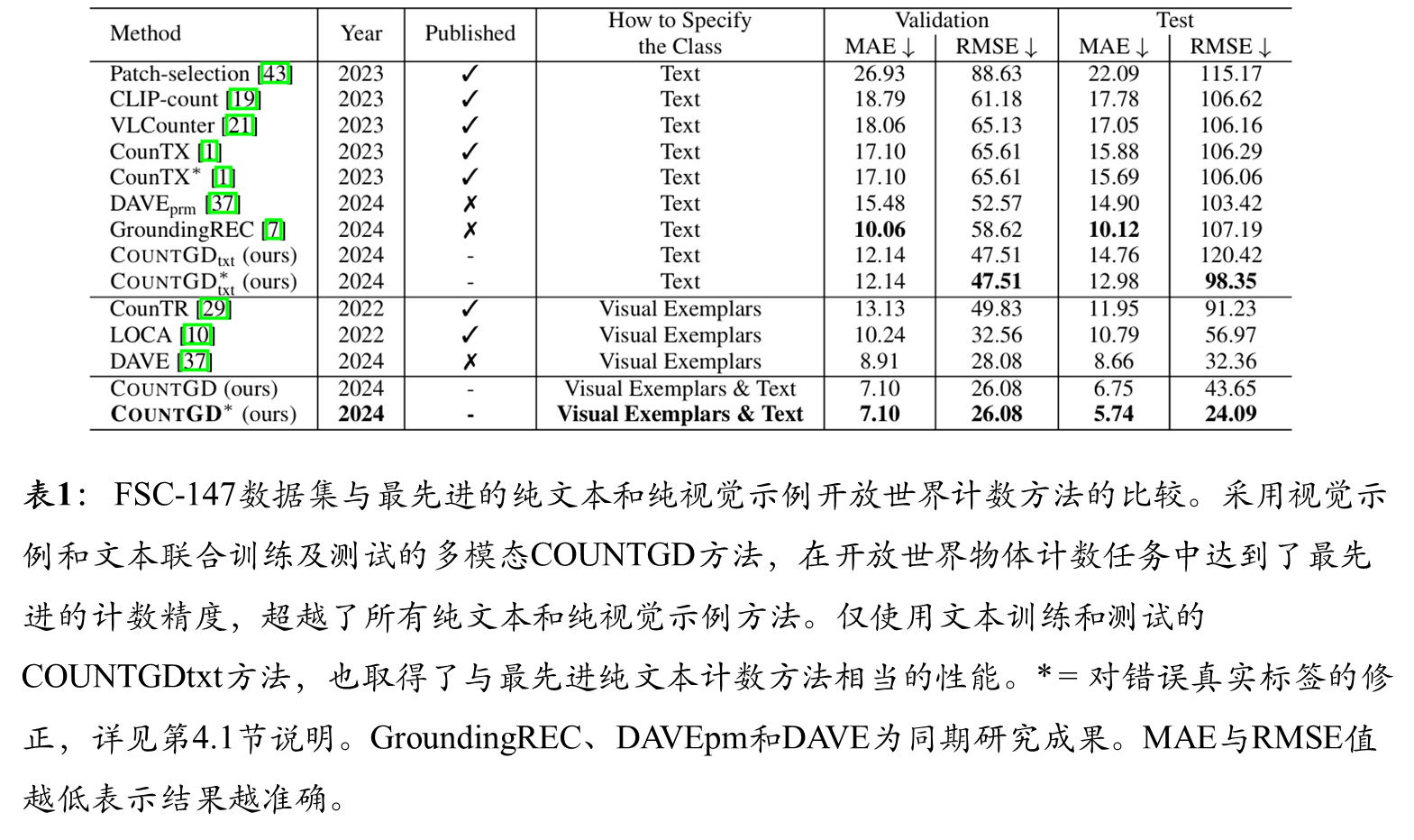
消融结果

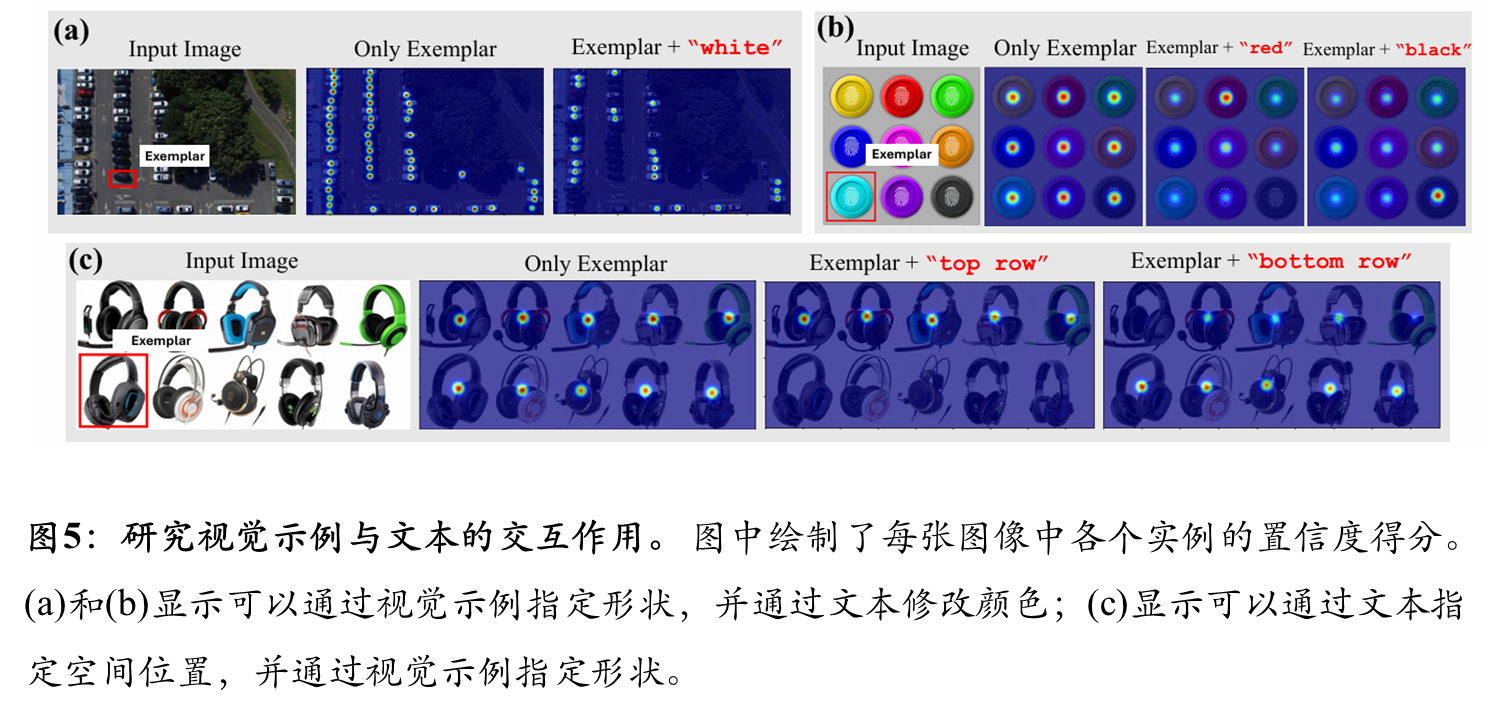
可视化结果



















 1612
1612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









