



 J-Tech Talk分享了Python装饰器的定义、特点和应用,揭示了如何使用装饰器增强函数功能,同时通过Jina AI的实际案例展示了装饰器在CLIP-as-service中的运用。参与者的GitHub可获取讲师文档和示例代码。
J-Tech Talk分享了Python装饰器的定义、特点和应用,揭示了如何使用装饰器增强函数功能,同时通过Jina AI的实际案例展示了装饰器在CLIP-as-service中的运用。参与者的GitHub可获取讲师文档和示例代码。
J-Tech Talk
由 Jina AI 社区为大家带来的技术分享
围绕 Python 的相关话题
工程师们将深入细节地讲解具体的问题
分享 Jina AI 在开发过程中所积累的经验
没来得及参与本次直播的小伙伴,可以在 JinaAI 视频号的回放栏,查看直播回放。

【Show Notes】
趣味诠释装饰器的定义和特点
装饰器可以让其他函数在不需要做任何代码变动的前提下增加额外功能
Python 装饰器的用法
工程师手写代码,带你了解装饰器的基本原理和使用 Tips
经验分享 - 装饰器在 Jina 中的应用
以 CLIP-as-service 为例,探究装饰器在工程实践中的实际用法
🌟 GitHub 获得讲师文档 + 示范代码
https://github.com/jina-ai/Events
Python 装饰器
当 Python 函数中的逻辑混杂在一起时,程序的可读性会大打折扣。这时,Python 装饰器就能大展身手了。它不仅有助于让我们的代码更简短,也会让我们的代码更加 Python 范儿~
装饰器的特点
Inputs: callable;Returns: callable
在被修饰的函数前、后进行操作
轻量、琐碎任务,使核心功能锦上添花
装饰器的用法
🔗 示范代码:https://github.com/jina-ai/Events 【点击阅读原文跳转】
装饰器在 CAS 中的应用
CLIP-as-service 是一个基于 CLIP 的图像和文本跨模态编码服务,低延迟、高可靠性的特点使其能作为微服务,轻松丝滑集成到神经搜索生态系统里。
文档:https://clip-as-service.jina.ai
链接:https://github.com/jina-ai/clip-as-service
1. 指定处理端点
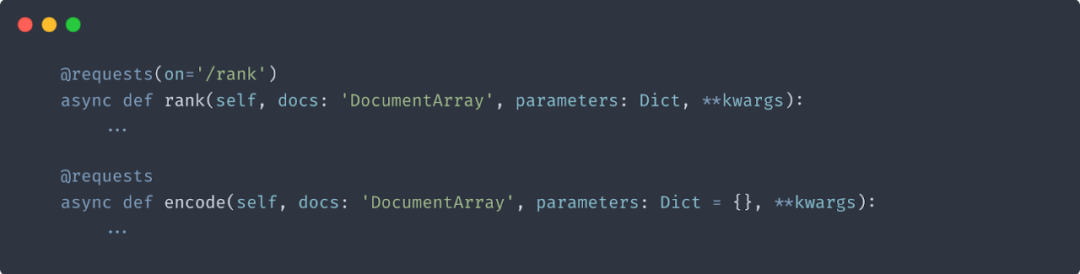
2. 函数重载
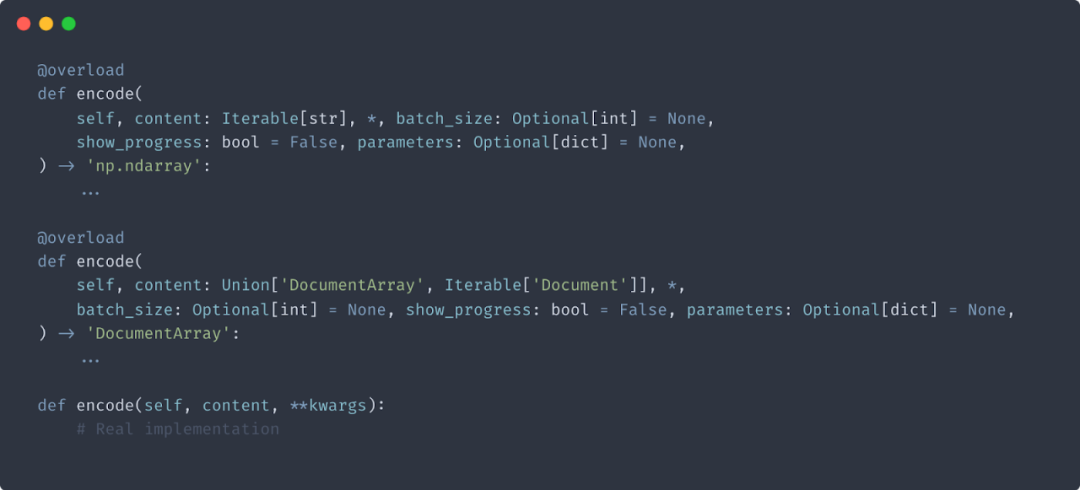
3. 启动时参数配置
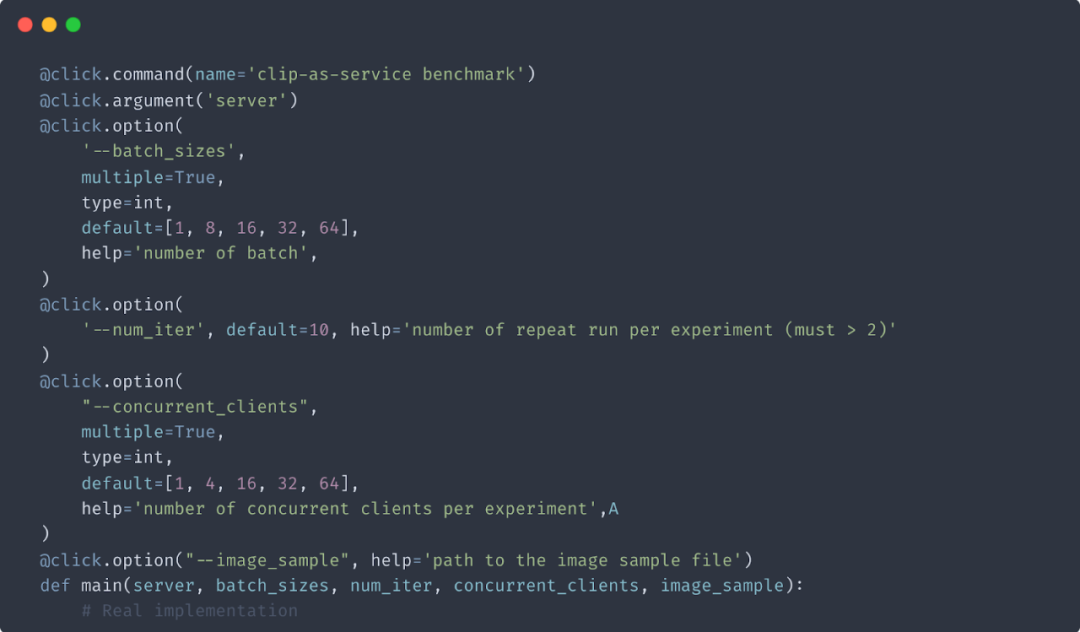
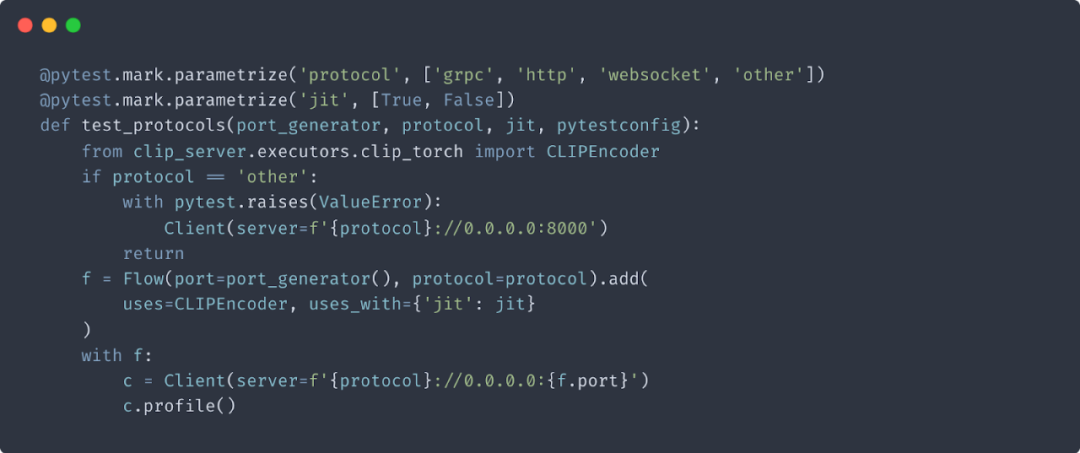
4. 单元测试参数配置

神经搜索、深度学习、推荐系统
教程、Demo、干货分享
扫码备注加入讨论组
更多精彩内容(点击图片阅读)



















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









