



分类是向量模型的常见下游应用。文本向量模型可以用来识别垃圾邮件或进行情感分析。对于多模态向量模型,比如 jina-clip-v1,可以被用于基于内容的筛选和标签标注等任务。最近,向量模型还充当了大模型路由器(LLM router)的角色,根据任务的复杂性和成本选择合适的模型:将简单的算术问题分配给小模型,将复杂的推理任务交由更强大的大模型。
今天,我们 Jina AI 搜索底座推出了一款高性能分类器:Classifier API,专为处理多模态和多语言数据而设计,支持零样本和小样本分类。
它基于我们最新的向量模型 jina-embeddings-v3 和 jina-clip-v1,并采用了在线被动攻击学习算法(Online Passive-Aggressive Learning),能够实时适应新数据,并以较少的人工干预实现高精度分类。
使用 Classifier API,用户可以首先利用零样本分类器直接启动分类任务。之后,用户可以通过提交少量新样本或在数据分布发生偏移时逐步更新分类器,以很低的成本持续提升分类性能。
此外,Classifier API 还支持用户将自己训练好的分类器设置为公开,促进分类器资源的共享和复用。随着 Jina AI 不断推出新的向量模型,比如即将推出的多语言 jina-clip-v2,我们会确保用户始终能够使用最先进的分类技术。
产品链接:https://jina.ai/classifier
零样本分类:无需训练,开箱即用
Classifier API 提供了强大的零样本分类功能,你不用提前准备任何训练数据,可以直接拿它来对文本或者图片进行分类。
每个分类器一开始都是零样本分类器,以后可以根据需要添加训练数据,变成一个小样本分类器,我们后面会详细说明。
示例 1:大模型路由器
下面这个例子展示了如何用 Classifier API 来做大模型请求的路由器:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-embeddings-v3",
"labels": [
"简单任务",
"复杂推理",
"创造性写作"
],
"input": [
"计算本金 $10,000 投资 5 年,年利率 5%,按季度复利的复利利息。",
"分析使用 CRISPR 基因编辑技术在人类胚胎中的伦理影响。考虑潜在的医疗益处和长期社会后果。",
"请写一篇以 AI 拥有自我意识的反乌托邦未来为背景的短篇小说,探索人与 AI 的关系以及意识的本质。",
"请解释归并排序和快速排序算法在时间复杂度、空间复杂度及实际性能上的区别。",
"写一首关于自然美和其对人类灵魂疗愈力量的诗。",
"将以下句子翻译成法语:The quick brown fox jumps over the lazy dog."
]
}'这个例子展示了如何用 jina-embeddings-v3 把用户的查询(包括英语、中文、日语和德语)分到三个类别里,这三个类别分别对应三种不同规模的大语言模型。
API 返回的结果格式如下:
{
"usage": {"total_tokens": 256, "prompt_tokens": 256},
"data": [
{"object": "classification", "index": 0, "prediction": "简单任务", "score": 0.35216382145881653},
{"object": "classification", "index": 1, "prediction": "复杂推理", "score": 0.34310275316238403},
{"object": "classification", "index": 2, "prediction": "创造性写作", "score": 0.3487184941768646},
{"object": "classification", "index": 3, "prediction": "复杂推理", "score": 0.35207709670066833},
{"object": "classification", "index": 4, "prediction": "创造性写作", "score": 0.3638903796672821},
{"object": "classification", "index": 5, "prediction": "简单任务", "score": 0.3561534285545349}
]
}响应包括:
usage:关于 token 使用情况的信息。data:分类结果数组,每个输入对应一个结果。每个结果包含预测的标签
prediction和scoreindex 对应于原始请求中的输入位置
示例 2:分类图像和文本
我们再来看一个多模态的例子,用的是 jina-clip-v1,这个模型可以同时处理文字和图片,很适合用来给各种媒体的内容分类。
下面是这段 API 的调用:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-clip-v1",
"labels": [
"美食与餐饮",
"科技与小工具",
"自然与户外",
"城市与建筑"
],
"input": [
{"text": "一款配有高分辨率显示屏和多摄像头的智能手机"},
{"text": "新鲜的寿司卷,配有芥末和姜,盛放在木制板上"},
{"image": "https://picsum.photos/id/11/367/267"},
{"image": "https://picsum.photos/id/22/367/267"},
{"text": "阳光穿过茂密森林的缝隙,照在鲜艳的秋叶上"},
{"image": "https://picsum.photos/id/8/367/267"}
]
}'API 返回的分类结果如下:
{
"usage": {"total_tokens": 12125, "prompt_tokens": 12125},
"data": [
{"object": "classification", "index": 0, "prediction": "科技与小工具", "score": 0.30329811573028564},
{"object": "classification", "index": 1, "prediction": "美食与餐饮", "score": 0.2765541970729828},
{"object": "classification", "index": 2, "prediction": "自然与户外", "score": 0.29503118991851807},
{"object": "classification", "index": 3, "prediction": "城市与建筑", "score": 0.2648046910762787},
{"object": "classification", "index": 4, "prediction": "自然与户外", "score": 0.3133063316345215},
{"object": "classification", "index": 5, "prediction": "科技与小工具", "score": 0.27474141120910645}
]
}示例 3:检测 Jina Reader 是否获取到真实内容
零样本分类还有一个有意思的应用,就是用 Jina Reader 来判断网站能不能正常访问。别看这个任务好像很简单,其实里面门道不少。每个网站屏蔽信息的方式都不一样,语言也不同,原因也五花八门(比如付费墙、访问频率限制、服务器故障等等)。这么多情况,很难用正则表达式或者固定的规则来全部搞定。
import requests
import json
response1 = requests.get('https://r.jina.ai/https://jina.ai')
url = 'https://api.jina.ai/v1/classify'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer $YOUR_API_KEY_HERE'
}
data = {
'model': 'jina-embeddings-v3',
'labels': ['Blocked', 'Accessible'],
'input': [{'text': response1.text[:8000]}]
}
response2 = requests.post(url, headers=headers, data=json.dumps(data))
print(response2.text)这段代码先用 r.jina.ai 获取网页内容,然后用 Classifier API 把它分成“Blocked”或者“Accessible”两类。
比如说 https://r.jina.ai/https://www.crunchbase.com/organization/jina-ai 很有可能会因为访问限制被分到“Blocked”类,而 https://r.jina.ai/https://jina.ai 应该是“Accessible”。
{"usage":{"total_tokens":185,"prompt_tokens":185},"data":[{"object":"classification","index":0,"prediction":"Blocked","score":0.5392698049545288}]}Classifier API 能有效地区分 Jina Reader 获取的真实内容和被屏蔽的结果,这对内容聚合或网页抓取系统尤为有用,尤其是在多语言环境中。
关于零样本分类的几点说明
使用语义标签
在使用零样本分类的时候,有一点非常重要:标签的语义要清晰。也就是说,你的标签最好是用一些描述性的词语,比如“科技”、“自然”、“美食”,而不是用一些抽象的符号或者数字,比如“Class1”、“Class2”、“Class3”或者“0”、“1”、“2”。
用“正面情感”比“正面”和 “True” 效果会更好,因为向量模型本身能够理解语义关系,你给它提供描述性的标签,它就能更好地利用预训练的知识,给出更准确的分类结果。
我们之前的博客里探讨了如何创建有效的语义标签以获得更好的分类结果:https://jina.ai/news/rephrased-labels-improve-zero-shot-text-classification-30
无状态的特性
零样本分类还有一个特点:无状态。只要你用的模型和输入的数据一样,不管是谁,在什么时候调用 API,得到的结果都是一样的。模型不会因为执行了分类任务就改变自己的参数,每次分类都是独立进行的。
这就意味着,你可以随时随地使用零样本分类器,不需要进行任何初始化或者训练,而且可以在不同的 API 调用之间自由地切换分类类别。
零样本分类的无状态性也跟小样本在线学习方法形成了鲜明对比。我们后面会讲到,小样本在线学习可以让模型根据新的样本进行调整,所以随着时间的推移或者用户的不同,模型给出的结果可能会有所差异。
小样本分类:快速学习,灵活调整
小样本分类提供了一种简单的方法,可以通过少量标注数据来创建和更新分类器。该方法提供了两个主要的端点:训练(train)和分类(classify)。
train 端点允许你用一小部分样本创建或者更新一个分类器。当你第一次调用训练功能的时候,它会返回一个 classifier_id,你可以把它保存下来,以后每当你有新的数据,或者发现数据分布发生了变化,或者需要添加新的分类类别的时候,都可以用这个 classifier_id 来继续训练你的分类器。这种灵活的机制,可以让你的分类器随着时间的推移不断学习新的模式和类别,而不需要每次都从头开始训练。
分类功能跟零样本分类的用法很相似,都是用来进行预测。区别在于,你需要在请求里带上你的 classifier_id,但不需要提供候选标签,因为这些标签已经包含在你训练好的模型里了。
示例:训练客服工单分配器
为了帮助大家更好地理解小样本分类的功能,我们来看一个实际的例子:客服工单的智能分配。假设你在一家快速发展的科技公司,每天都会收到大量的客户咨询,你需要把这些咨询分配给不同的团队来处理。
初始训练:
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-embeddings-v3",
"access": "private",
"input": [
{
"text": "在最新的应用更新后,我无法登录我的账户。",
"label": "team1"
},
{
"text": "由于信用卡过期,我的订阅续订失败了。",
"label": "team2"
},
{
"text": "我如何从平台中导出我的数据?",
"label": "team3"
}
],
"num_iters": 10
}'需要注意的是,在小样本学习中,我们可以直接用 team1、team2 这样的标签,即使它们本身没有什么语义含义也没关系。
API 会返回一个 classifier_id,表示你新创建的分类器。你需要记下 classifier_id,之后需要使用它来引用该分类器。
{
"classifier_id": "918c0846-d6ae-4f34-810d-c0c7a59aee14",
"num_samples": 3
}更新分类器
随着公司的发展,新的问题类型可能会出现,团队结构也可能会发生变化。小样本分类的优势在于,它可以快速适应这些变化。
你只需要用 classifier_id 和新的样本来更新这个分类器,就可以添加新的团队类别(比如 team4),或者把现有的问题类型分配给不同的团队。
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "尝试访问新的 AI 聊天机器人功能时,我收到 404 错误。",
"label": "team4"
},
{
"text": "最新的安全补丁与我的公司防火墙发生冲突。",
"label": "team1"
},
{
"text": "我需要帮助为我的企业账户设置 SSO。",
"label": "team5"
}
],
"num_iters": 10
}'使用训练好的分类器
在实际使用的时候,你只需要提供输入文本和 classifier_id,API 就会自动把你的输入映射到之前训练好的类别,并返回最合适的标签。
curl -X 'POST' \
'https://api.jina.ai/v1/classify' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "新功能导致我的仪表板加载缓慢。"
},
{
"text": "我需要更新我的账单信息以用于税务目的。"
}
]
}'参数调优,掌控学习节奏
小样本模式有两个重要的参数:num_iters 和 access。
1.num_iters 参数控制分类器学习训练样本的强度。
默认值是 10,但在实际使用中,你可以根据训练数据的质量进行调整。如果你的训练样本质量很高,对分类结果的影响很大,你可以增加 num_iters 的值,让模型更加重视这些样本。反之,如果你的训练样本质量不高,你可以减小 num_iters 的值,减少它们对分类器性能的影响。
你还可以用这个参数来实现时间感知学习,为新训练数据设置更高的 num_iters,让模型更加重视最近的样本,从而更好地适应数据分布的变化,同时保留历史知识。
2.access 参数控制谁可以使用你的分类器。
默认情况下,分类器是私有的,只有你可以使用。如果你想把你的分类器分享给其他人,可以把 access 参数设置为 “public”。 这样一来,任何拥有你的 classifier_id 的人,都可以用他们自己的 API Key 来使用你的分类器。
这种方式既方便了分类器的共享,又保护了你的隐私。其他人无法看到你的训练数据或者配置,你也无法看到他们的分类请求。需要注意的是,这个参数只对小样本分类有效,因为零样本分类器是无状态的,无论是谁使用,得到的结果都是一样的,所以也就没有必要共享了。
关于小样本学习的几个特点
Jina API 的小样本分类实现方式跟传统的机器学习模型不太一样。我们采用的是 一次性在线学习,也就是说,训练样本在更新分类器参数之后就会被丢弃,不会被保存下来。 不存储训练样本的好处是可以更好地保护用户隐私,并且节省存储空间。
虽然小样本学习很强大,但它也需要一定的热身期才能超过零样本分类的性能。根据我们的测试,通常需要 200-400 个训练样本才能看到明显的提升。 当然,你不需要一开始就为所有的类别都提供训练样本,分类器可以随着时间的推移逐渐学习新的类别。
但是,新添加的类别在积累足够样本之前,可能会经历一段时间的“冷启动”,也就是预测准确率较低的情况。另外,如果某些类别的训练样本明显少于其他类别,也可能出现“类别不平衡”问题,导致模型在预测这些类别时表现不佳。
基准测试:零样本 vs 小样本,哪个更好?
为了评估零样本和小样本分类的性能,我们使用多种数据集进行了测试,包括文本分类任务(比如情感检测和垃圾邮件检测)和图像分类任务(比如 CIFAR10)。我们采用了标准的训练-测试集划分方法,零样本分类不需要训练数据,小样本分类则使用部分训练集。我们跟踪了训练集大小和目标类别数量等关键指标,以便进行对比分析。
为了保证测试结果的可靠性,尤其是对小样本分类,我们对每个输入进行了多次训练迭代。我们还把这些新方法跟传统的基线方法(比如 Linear SVM 和 RBF SVM)进行了比较,以便更好地了解它们的性能。
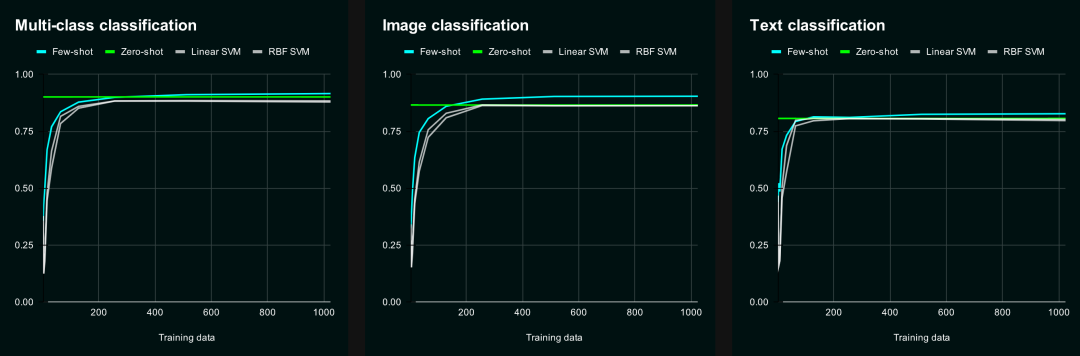
我们绘制了 F1 分数的图表,完整的基准测试设置可以参考这个 Google 电子表格:https://docs.google.com/spreadsheets/d/15vK6VPlcAM4e7lSJw6IeVtTtyariXEVQurDTFKXwwtY/edit?gid=249584681#gid=249584681
从 F1 分数的图表中,我们可以看到一些有趣的现象:
首先,零样本分类的性能从一开始就比较稳定,无论训练集大小如何都不会发生太大变化。
其次,小样本分类的学习曲线比较陡峭,一开始性能可能不如零样本分类,但随着训练数据的增加,性能会迅速提升,并且最终会超过零样本分类。当训练样本数量达到 400 个左右的时候,两种方法的性能基本持平,小样本分类略胜一筹。无论是在多类别分类还是在图像分类任务中,这种现象都比较明显。
也就是说,如果你有一些训练数据,小样本分类是一个不错的选择;如果你没有任何训练数据,零样本分类也能提供可靠的性能。
下面这个表格总结了零样本和小样本分类在 API 使用上的区别。
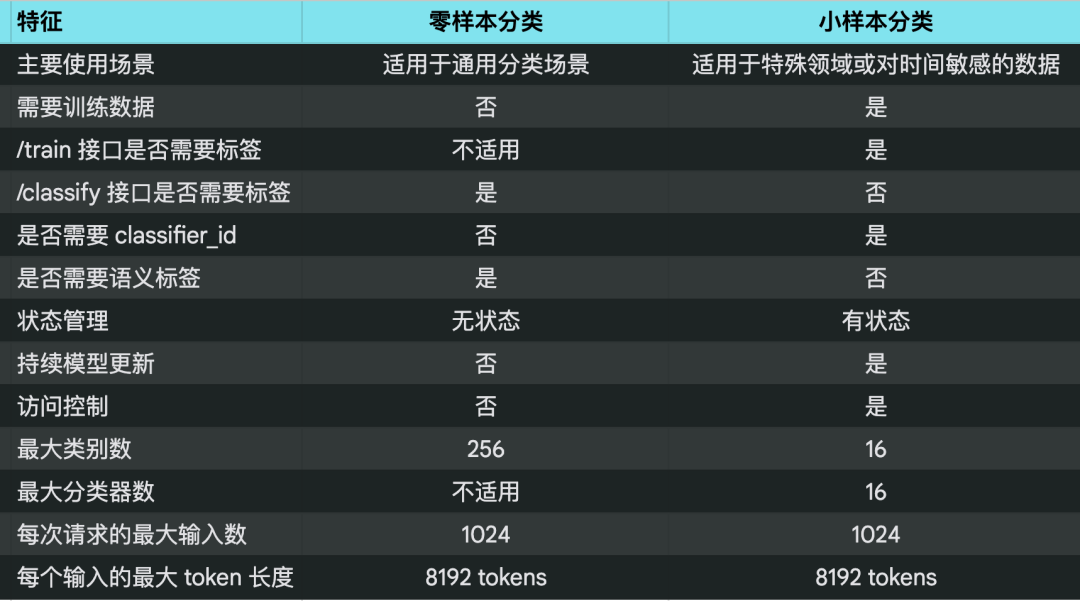
注释:
语义标签: 指的是需要能够清晰表达类别含义的标签,例如 "科技"、"自然"、"美食" 等。
状态管理: 指的是分类器是否会根据新的训练数据更新模型参数。
持续模型更新: 指的是分类器是否支持在使用过程中不断更新模型参数。
总结
Classifier API 由行业领先的向量模型(如 jina-embeddings-v3 和 jina-clip-v1)提供支持,为文本和图像内容提供了强大的零样本和小样本分类功能。
我们的基准测试表明,零样本分类无需训练数据即可提供可靠的性能,是大多数任务的理想起点,支持多达 256 个类别。虽然小样本学习可以通过训练数据获得略高的准确性,但我们建议您从零样本分类开始,因为它可以立即获得结果并具有灵活性。
API 的多功能性支持各种应用场景,从大模型路由器,检测网站可访问性,到对多语言内容进行分类。无论是从零样本开始还是过渡到用于特殊情况的小样本学习,API 都保持一致的接口,能够无缝集成到您的流程中。
我们特别期待看到各位开发者们如何在你们的应用中利用这一 API,并且也将马上推出对新的向量模型(如 jina-clip-v2)的支持。


















 1910
1910



 到【灌水乐园】发言
到【灌水乐园】发言








