




 CLIP-as-service (CAS) 提供了一个基于 CLIP 模型的低延迟、高可扩展的图像和文本编码服务,适合作为微服务集成。新升级带来了更高的稳定性和可用性,支持更多高级功能,用户可以免费注册并使用。
CLIP-as-service (CAS) 提供了一个基于 CLIP 模型的低延迟、高可扩展的图像和文本编码服务,适合作为微服务集成。新升级带来了更高的稳定性和可用性,支持更多高级功能,用户可以免费注册并使用。
CLIP 是一个强大的模型,能够很好地判别文本和图片是否相关,但将其集成到现有系统中需要大量时间精力,以及机器学习知识。
CLIP-as-service(CAS) 是一种易于使用的服务,具有低延迟和高度可扩展性,可以作为微服务轻松集成到现有解决方案中。
介绍
CLIP-as-service 是一种基于 CLIP 模型的图像和文本跨模态编码服务。它的低延迟、高可靠性的特点使其能作为微服务轻松集成到神经搜索解决方案中。
-
快速:提供 TensorRT、ONNX 和 PyTorch(无JIT)运行时高达 800QPS 的 CLIP 模型。同时拥有专为大数据和高稳定性任务设计的非阻塞请求和响应。
-
灵活:可在单块 GPU 下扩展或缩减多个 CLIP 模型,同时做到负载平衡。
-
易用:无需学习,极简的客户端和服务端设计让使用变得十分直观。
-
现代:客户端支持异步请求。在 gRPC、HTTP 和 WebSocket 协议中轻松切换。
-
集成:它能和 Jina, DocArray 等 Jina AI 生态丝滑集成,快速构建多模态、跨模态的解决方案。
长期以来,Jina AI 一直提供免费的 CAS 实例供大家试用,开发者可以通过 cURL 或 gRPC 直接访问该服务器,快速生成文本和图像 embedding,并执行许多视觉推理任务。该实例将在 2022 年 9 月 15 日停止运行。
与此同时,我们将 CAS 升级为高稳定、高可用的服务,未来还将支持模型选择、使用分析等高级功能。目前您只需要注册登录,即可免费使用。当然,您也可以继续依托开源的 CAS 部署自己的服务。
如何使用新版 CAS
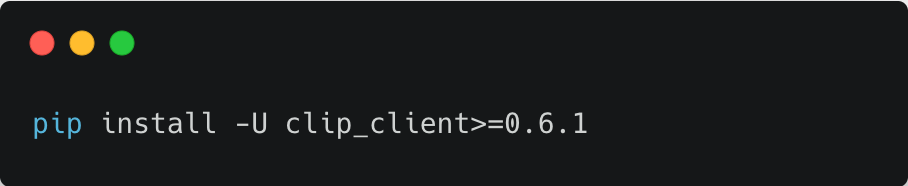
1. 安装 clip_client 0.6.1 及更高版本
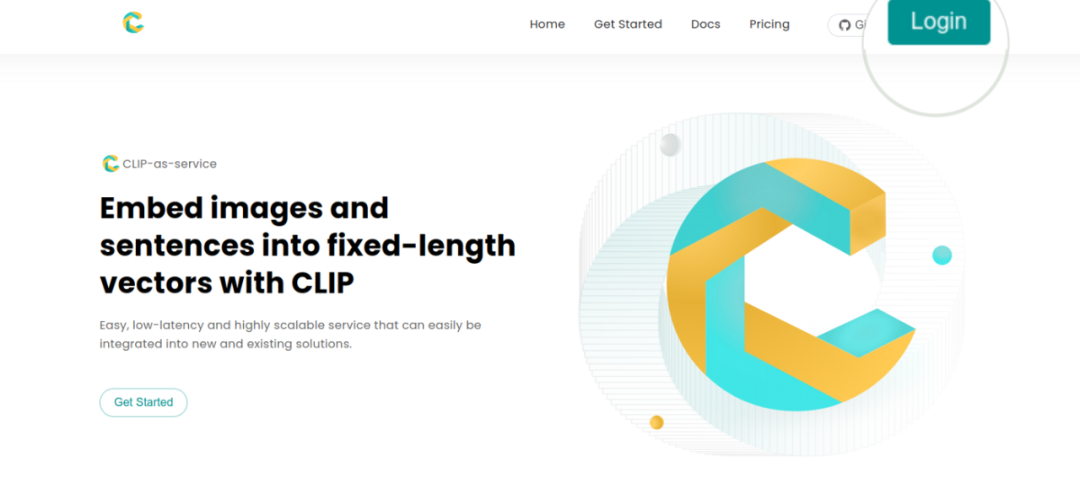
2. 在 https://console.clip.jina.ai/ 上,点击右上角,创建一个账号
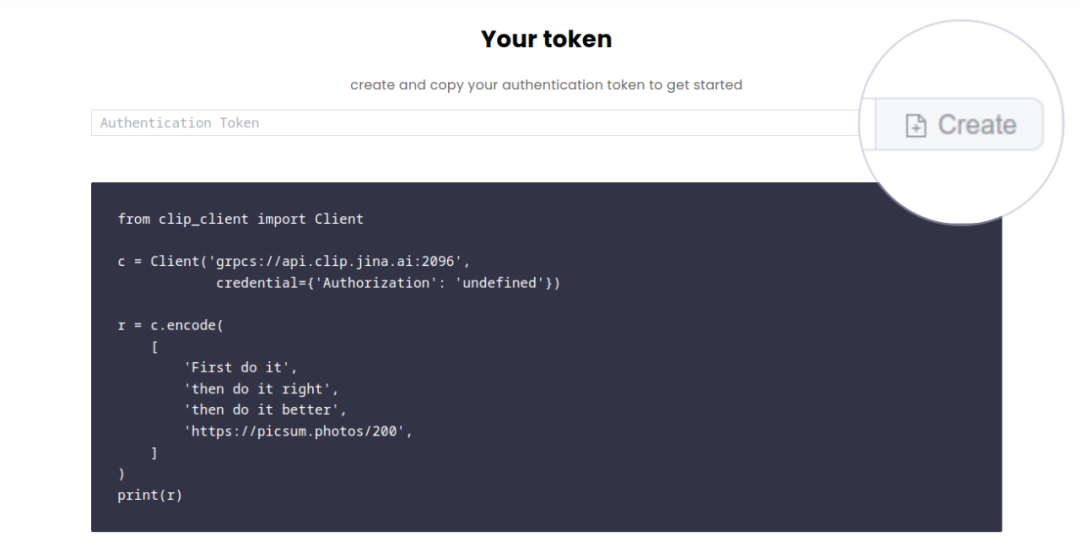
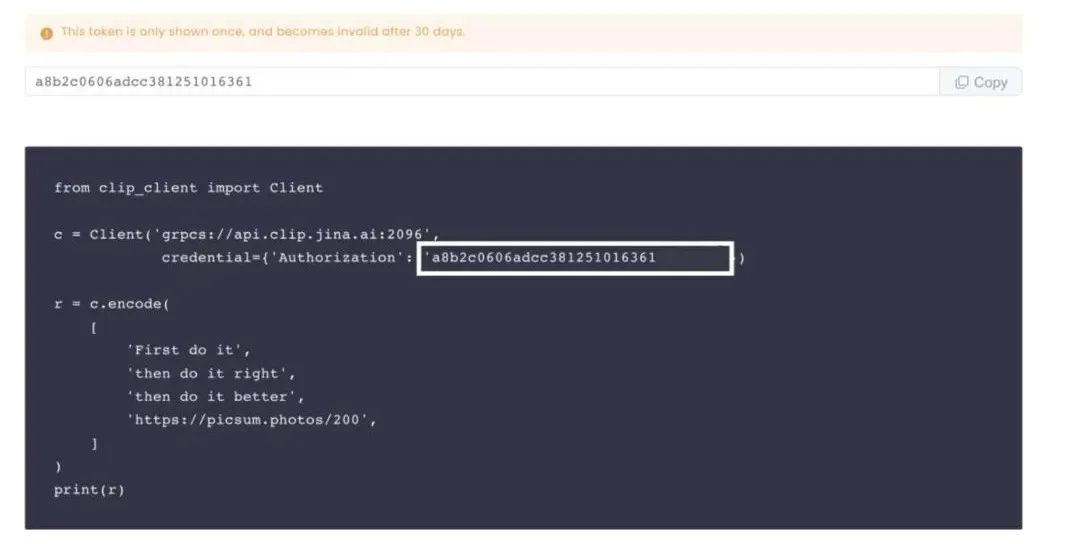
3. 生成一个 Token,复制代码并运行
4. 当您得到如下输出,则说明运行成功!


















 2652
2652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









