







前情提要本文篇幅较长,请耐心看完
自动编码器是一类无监督神经网络,可以在低维空间(也称为潜在空间)中表示数据,以学习有效的表示。应用包括压缩、降噪、特征提取和生成模型。自动编码器的训练方式是:首先将数据编码到潜在空间中,然后将它们解码回原始表示形式,也称为重建,同时最大限度地减少原始输入和重建数据之间的差异。在扩展中,变分自动编码器 (VAE) 学习潜在空间上的概率分布,这使它们能够生成全新的数据,同时牺牲了完美重建现有数据的能力。这种权衡由向量量化变分自动编码器 (DQ-VAE) 解决,它用学习到的字母或码本表示潜在空间。本博客文章将使用 CIFAR10 图像数据集迭代开发所有三个的实现。
数据和设置
本文适用于 Google Colab 中的演练。下面的代码将导入必要的库并加载数据集:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import…该代码使用 Torch 的 DataLoader 功能和 torchvision 的 transforms 库。在本例中,我们使用转换将图像转换为 torch 张量。
您可以使用 matplotlib 可视化训练数据:
# Function to display images in a grid
def display_images(images):
fig, axes = plt.subplots(3, 3, figsize=(4, 4))
for i, ax in enumerate(axes.flat):
if i < len(images):
image = images[i].permute(1, 2, 0).numpy() # Rearrange dimensions for display
ax.imshow(image)
ax.axis('off')
plt.show()
# Get the first 9 images from the train_loader
# Get the first 9 images from the train_loader
data, target = next(iter(train_loader))
images = data[:9]
# Display images using the helper function
display_images(images)请注意,train_loader 返回一个元组数据 target,其中包含图像和 target 类,格式为 0 到 9。在本文中,我们根本没有使用目标,但将训练自动编码器变体来学习有效的数据表示并生成新图像。运行上面的代码应该会产生如下结果:

自动编码器
基本的 autoencoder 由两个块组成:编码器和解码器。一起训练后,我们可以分别使用 encoder 和 decoder 来分别压缩和解压缩一张图片。对于图像,编码器通常由一系列卷积层和全连接层组成。解码器具有逆结构,从一个全连接层开始,然后是一系列卷积层。
class ConvAE(nn.Module):
def __init__(self, latent_dim=100):
super(ConvAE, self).__init__()
# Encoder: Convolutions to extract features
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1), # (B, 64, 16, 16)
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), # (B, 128, 8, 8)
nn.ReLU(),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1), # (B, 256, 4, 4)
nn.ReLU(),
)
# Latent space
self.fc = nn.Linear(256 * 4 * 4, latent_dim)
# Decoder: Transposed convolutions for upsampling
self.decoder_input = nn.Linear(latent_dim, 256 * 4 * 4)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1), # (B, 64, 8, 8)
nn.ReLU(),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), # (B, 32, 16, 16)
nn.ReLU(),
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1), # (B, 3, 32, 32)
nn.Sigmoid() # Output pixel values between 0 and 1
)
def encode(self, x):
x = self.encoder(x)
x = x.view(x.size(0), -1) # Flatten
z = self.fc(x)
return z
def decode(self, z):
x = self.decoder_input(z)
x = x.view(x.size(0), 256, 4, 4) # Reshape to feature maps
x = self.decoder(x)
return x
def forward(self, x):
z = self.encode(x)
recon_x = self.decode(z)
return recon_x在此示例中,我们使用一个 100 维潜在空间和三个卷积层,每次都将图像维度减少 2 倍。我们通过使用 4x4 内核和 2 的步幅大小来实现这一点。从 3 通道图像开始,我们使用 64 个可学习过滤器,每个过滤器的大小为 (3,4,4),即每个通道一个。然后,我们将结果传递给 128 个可学习的过滤器,每个过滤器的大小为 (64, 4, 4),最后通过 256 个维度为 (128, 4, 4) 的可学习过滤器。输出是 256 个 4x4 图像,这些图像被展平为单个矢量并通过完全连接的层。所有这些都发生在 encode() 函数中。
扩散模型一直没对手?比自回归和VAE效果更好的Diffusion Models数学原理精讲,生成模型GAN/变分自编码器/人工智能/神经网络
在 decode() 函数中,情况正好相反。我们首先使用完全连接的网络从潜在维度投影到 256x4x4 像素,然后将其重塑为 256 个 4x4 图像并通过卷积层。结果再次是 32x32 的图像。
我们可以使用
# 初始化模型和优化
器 latent_dim = 1024
model = ConvAE(latent_dim=latent_dim).to(device)
optimizer = optim.亚当(model.parameters(), lr=1 e-3)在这里,我们使用 1024 的潜在维度。
如果您认为此过程使用了相当多的参数,那是对的。我们可以使用
def get_model_size(model):
total_params = sum(p.numel() for p in model.parameters())
return total_params
model_size = get_model_size(model)
print(f"Model size: {model_size} parameters")Model size: 9711235 parameters或大约 9MB。考虑到原始 CIFAR10 数据集是 230MB 的数据,这并不多。这些参数中的大部分被 4096x1024 全连接网络用完,该网络向下投影到 1024 维潜在空间,然后从 1024 维潜在空间投影出来。
训练
在训练模型之前,我们需要定义什么是 “loss”。我们的目标是训练上面的模型,使模型的输出尽可能接近逐个像素的输入。我们可以通过对所有像素的均方误差求和来实现这一点:
def loss_function(recon_x, x):
recon_loss = F.mse_loss(recon_x, x, reduction="sum") # MSE for image reconstruction
return recon_loss我们现在可以使用这个损失函数训练模型 20 个 epoch,即整个训练集的 20 个完整表示。您可以在 Google Colab 的 T4 GPU 上在大约 4 分钟内完成此作。
# Loss function
def loss_function(recon_x, x):
recon_loss = F.mse_loss(recon_x, x, reduction="sum") # MSE for image reconstruction
return recon_loss
# Training loop for AE
epochs = 20
for epoch in range(epochs):
model.train()
total_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.to(device)
optimizer.zero_grad()
recon_data = model(data)
loss = loss_function(recon_data, data)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"====> Epoch: {epoch+1}, Average loss: {total_loss / len(train_loader.dataset):.4f}")====> Epoch: 1, Average loss: 47.8117
====> Epoch: 2, Average loss: 22.7343
====> Epoch: 3, Average loss: 16.2495
====> Epoch: 4, Average loss: 13.4375
====> Epoch: 5, Average loss: 11.6479
====> Epoch: 6, Average loss: 10.3794
====> Epoch: 7, Average loss: 9.4950
====> Epoch: 8, Average loss: 8.6848
====> Epoch: 9, Average loss: 8.0788
====> Epoch: 10, Average loss: 7.4614
====> Epoch: 11, Average loss: 6.9470
====> Epoch: 12, Average loss: 6.4711
====> Epoch: 13, Average loss: 6.1032
====> Epoch: 14, Average loss: 5.8384
====> Epoch: 15, Average loss: 5.6323
====> Epoch: 16, Average loss: 5.2493
====> Epoch: 17, Average loss: 5.0357
====> Epoch: 18, Average loss: 4.8003
====> Epoch: 19, Average loss: 4.6020
====> Epoch: 20, Average loss: 4.4080测试 Autoencoder
现在,我们可以通过并排显示图像来比较压缩前后的图像:
# Display some reconstructed images
def show_images(original, reconstructed):
fig, axes = plt.subplots(1, 2)
axes[0].imshow(original.permute(1, 2, 0).cpu().numpy()) # Convert tensor to image
axes[0].set_title("Original")
axes[1].imshow(reconstructed.permute(1, 2, 0).cpu().detach().numpy())
axes[1].set_title("Reconstructed")
plt.show()
for _ in range(3):
# Test reconstruction on a sample
test_img, _ = next(iter(train_loader))
test_img = test_img.to(device)
with torch.no_grad():
reconstructed_img = model(test_img)[0]
show_images(test_img[0], reconstructed_img)在这里,permute()作重新排列颜色通道,以便 imshow 显示正确的彩色图像。你应该得到这样的东西

事实证明,20 个 epoch 是不够的。为了实现上述结果,我又训练了 60 个 epoch,以进一步将损失从 4.4 降低到 1.8。结果相当不错。我们确实观察到一些 “压缩伪像”,例如在检查底行的蓝天时。
但是,对于不在训练集中的图像,这是如何工作的呢?自动编码器是否学习了一种可以推广到其他类似图像的压缩方案?我们可以通过加载一个完全不同的数据集来尝试这一点,即 Google 的 Street View House Numbers 数据集。
svhn_dataset = 数据集。SVHN(root=“./data”, split=“test”, transform=transform, download=True)
svhn_loader = torch.utils.data.DataLoader(svhn_dataset, batch_size=64, shuffle=True)现在,我们可以将上面脚本中的 train_loader 替换为 svhn_loader,并查看我们训练的自动编码器是否也适用于这些图像:
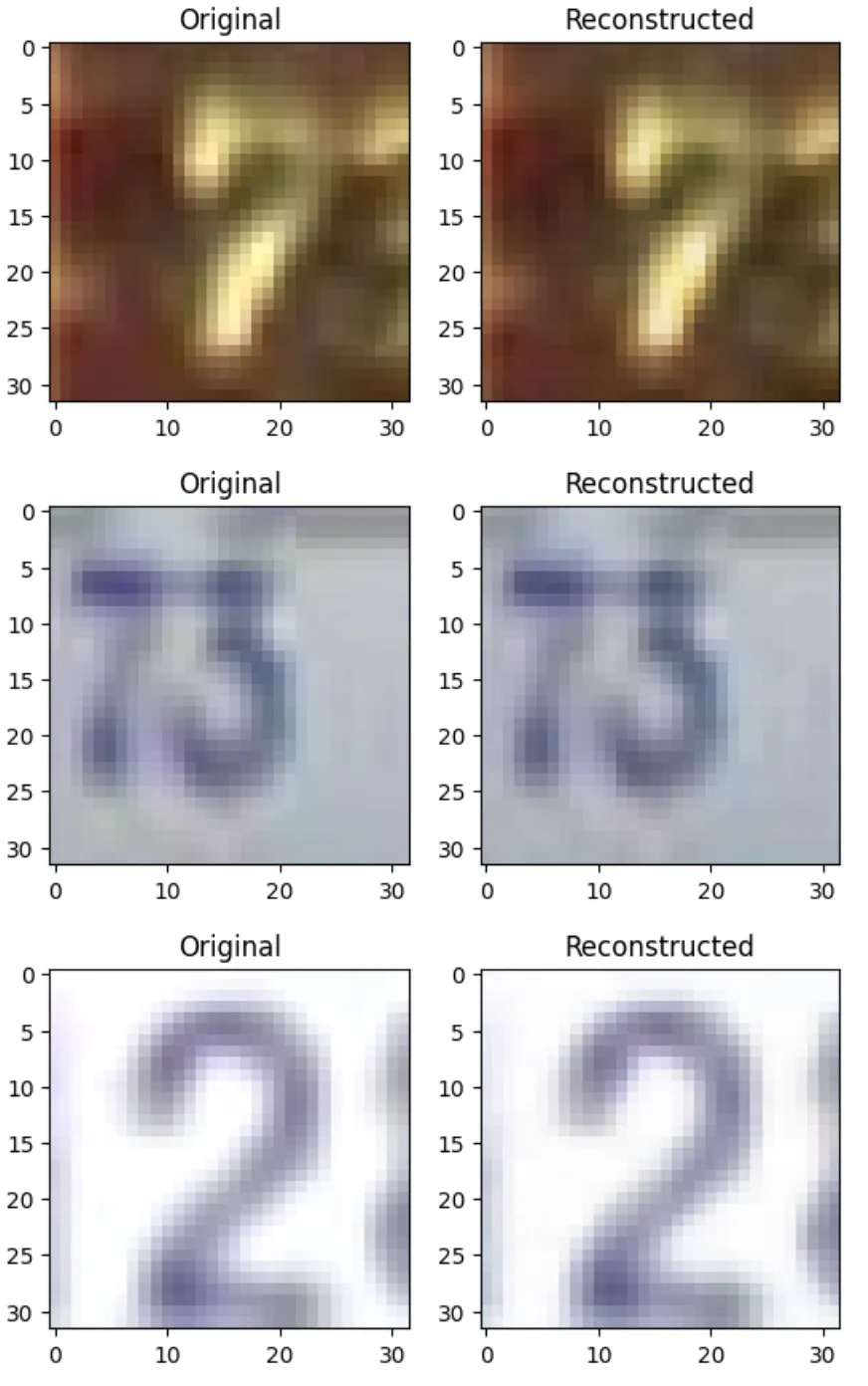
这就是为什么 autoencoders 是一个如此强大的工具。一旦训练好了,我们就可以使用它们将任意数据(只要它与我们训练自动编码器的数据类型有点相似)投影到低维空间。在这种情况下,自动编码器已经学习了在 CIFAR10 和 SVHN 之间共享的典型图像特征。
尽管进行了压缩,但这种自动编码器的其他应用是图像去噪和异常检测。如果图像包含训练图像不分布的噪声(或特征),则不太可能在重建中重现。同样,要测试图像是否与我们训练的图像“相似”,我们只需要跟踪重建损失,对于包含自动编码器在训练期间未看到的特征的图像,重建损失会更高。
变分自动编码器
虽然自动编码器在近乎完美的重建方面非常出色,但没有办法生成全新的数据。这对于生成模型(例如 DALL-E)或两个图像之间的平滑混合等应用程序来说很有趣。变分自动编码器通过概率性地处理潜在空间来解决这一应用。为此,潜在空间中的每个像素都由高斯分布的平均值 (μ) 和标准差 (σ) 表示,即 2 个值而不是一个值。然后,我们可以通过从这个分布中采样来重建图像,即
z = μ + r*σ
这里,r 是一个随机值,它服从高斯分布,均值为零,方差为 1。
如上例所示,当使用潜在维度 1024 时,潜在空间是 1024 维高斯分布。让我们看看这在代码中是什么样子的:
class ConvVAE(nn.Module):
def __init__(self, latent_dim=100):
super(ConvVAE, self).__init__()
# Encoder: Convolutions to extract features
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1), # (B, 64, 16, 16)
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), # (B, 128, 8, 8)
nn.ReLU(),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1), # (B, 256, 4, 4)
nn.ReLU(),
)
# Latent space
self.fc_mu = nn.Linear(256 * 4 * 4, latent_dim)
self.fc_logvar = nn.Linear(256 * 4 * 4, latent_dim)
# Decoder: Transposed convolutions for upsampling
self.decoder_input = nn.Linear(latent_dim, 256 * 4 * 4)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1), # (B, 64, 8, 8)
nn.ReLU(),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), # (B, 32, 16, 16)
nn.ReLU(),
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1), # (B, 3, 32, 32)
nn.Sigmoid() # Output pixel values between 0 and 1
)
def encode(self, x):
x = self.encoder(x)
x = x.view(x.size(0), -1) # Flatten
mu, logvar = self.fc_mu(x), self.fc_logvar(x)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
x = self.decoder_input(z)
x = x.view(x.size(0), 256, 4, 4) # Reshape to feature maps
x = self.decoder(x)
return x
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
recon_x = self.decode(z)
return recon_x, mu, logvar编码器和解码器使用相同的卷积,但我们使用两个全连接层来计算两个潜在空间:一个用于平均值 (mu),另一个用于方差的对数 (logvar)。表示方差的对数而不是直接表示方差的原因是我们不希望方差变为负数。相反,我们通过对标准差(方差的平方根)求冹 (std = torch.exp(0.5 * logvar)) 来确保标准差(方差的平方根)为正值。在这里,以 0.5 求幂等效于平方根运算。
然后,解码器使用表达式 randn_like() 按字面意思绘制一个随机数。由于随机数只是 mu + eps * std 中的一个因子,因此梯度计算不受影响,模型可以学习适当的参数来最小化误差。
训练变分自动编码器
如果我们用上面的均方误差损失来训练这个变分自动编码器,我们将得到与标准自动编码器完全相同的结果。事实上,训练会通过收敛到零标准差来忽略 eps*std 项。如果我们希望 VAE 导致真正的高斯分布,我们需要一个额外的损失项。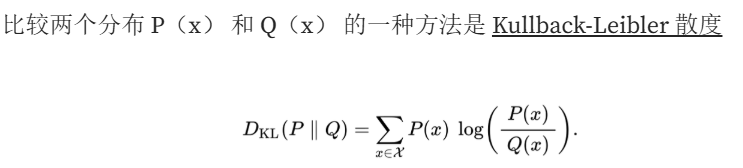
在我们的例子中,分布 Q 是一个零均值、方差为 1 的高斯分布 — 我们想要的分布 — 另一个是我们实际学习的分布。在这里,总和遍历了 x 的所有可能值(连续分布的积分)。在我们的例子中,我们想将训练分布 N(μ,σ²) 与期望的分布进行比较,例如 N(0,1)(均值为零,方差 1),这将方程简化为:
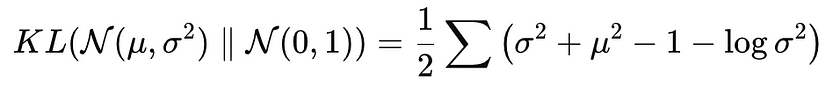
要得到上述方程,需要用实际函数代替正态分布
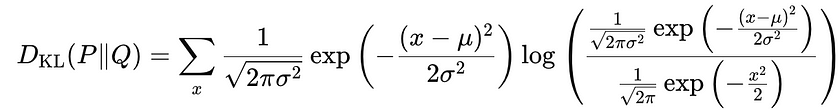
简化对数,最后对结果求和/积分。添加 KL 背离会导致以下损失
def loss_function(recon_x, x, mu, logvar):
recon_loss = F.mse_loss(recon_x, x, reduction="sum") # MSE for image reconstruction
kl_div = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()) # KL divergence
return recon_loss + 0.1*kl_div在这里,我们简单地将均方误差损失与 KL 散度相加。由于我们想要最小化,因此我们使用负 KL 背离。在此示例中,我选择了 0.1 的权重,这将使模型转向完美重建,而不是生成新图像。
我们现在可以实例化新模型
latent_dim = 1024
模型 = ConvVAE(latent_dim=latent_dim).to(device)
optimizer = optim.亚当(model.parameters(), lr=1 e-3)并对其进行训练:
epochs = 10
for epoch in range(epochs):
model.train()
total_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.to(device)
optimizer.zero_grad()
recon_data, mu, logvar = model(data)
loss = loss_function(recon_data, data, mu, logvar)
loss.backward()
optimizer.step()
total_loss += loss.item()
#if batch_idx % 100 == 0:
# print(f"Epoch [{epoch+1}/{epochs}], Step [{batch_idx}/{len(train_loader)}], Loss: {loss.item():.2f}")
print(f"====> Epoch: {epoch+1}, Average loss: {total_loss / len(train_loader.dataset):.4f}")损失在 20 个 epoch 后下降到 34 左右,在 30 个 epoch 后下降到 33 左右,在 40 个 epoch 后下降到 32,并且仅在 50 和 60 个 epoch 中非常缓慢地改善(32.13 误差)。
这个模型不仅更大(大约 13MB),而且生成随机数也使其学习速度比标准自动编码器慢一点。我们也不希望损失像自动编码器那样低,因为我们确实会生成随机图像(假设方差不为零)。事实上,生成的图像非常嘈杂:
注意:要使用上面的代码生成此输出,请将最后一行更改为
show_images(test_img[0], reconstructed_img[0])虽然这可能会随着更多的训练而改善,但当进一步减少 KL 损失项的贡献时,可以很容易地看到这里会发生什么。例如,将其设置为 0.001 将得到类似于原始自动编码器的结果,因为自动编码器没有学习分布,而只是尝试尽可能好地匹配呈现的数据。
那么,我们为什么关心变分自动编码器呢?它们允许我们生成各种图像。我们可以运行代码来显示图像,而无需实际加载新图像:
def show_images(original, reconstructed):
fig, axes = plt.subplots(1, 2)
axes[0].imshow(original.permute(1, 2, 0).cpu().numpy()) # Convert tensor to image
axes[0].set_title("Original")
axes[1].imshow(reconstructed.permute(1, 2, 0).cpu().detach().numpy())
axes[1].set_title("Reconstructed")
plt.show()
for _ in range(3):
# Test reconstruction on a sample
with torch.no_grad():
reconstructed_img = model(test_img)[0]
show_images(test_img[0], reconstructed_img[0])要获得狗的三个重建图像:

尽管有噪点,但上面的每张图片都略有不同。更重要的是,由此产生的潜在空间就是所谓的结构化空间。潜在空间中接近的表示也会生成类似的输出。当尝试混合两个不同的图像时,首先使用 VAE 对它们进行编码,然后平均它们的潜在空间,这可以从中看出:
# Function to display images in a grid
def display_images(images, titles=None):
fig, axes = plt.subplots(1, len(images), figsize=(12, 4))
for i, ax in enumerate(axes):
image = images[i].permute(1, 2, 0).cpu().detach().numpy() # Rearrange dimensions for display
ax.imshow(np.clip(image, 0, 1))
ax.axis('off')
if titles:
ax.set_title(titles[i])
plt.show()
# Function to blend latent vectors
def blend_latent_vectors(latent1, latent2, alpha=0.5):
return alpha * latent1 + (1 - alpha) * latent2
# Put images in the correct device if needed
image1 = test_img[0].to(device)
image2 = test_img[1].to(device)
# Encoder step for image1 and image2 (getting their latent vectors)
mu1, logvar1 = model.encode(image1.unsqueeze(0))
mu2, logvar2 = model.encode(image2.unsqueeze(0))
# Interpolate between the latent vectors (blend in latent space)
alpha = 0.5 # Set blending factor (0 for image1, 1 for image2, 0.5 for the blend)
blended_mu = blend_latent_vectors(mu1, mu2, alpha)
# Decode the blended latent vector back into an image
blended_image = model.decode(blended_mu)
# Display images
images = [image1, image2, blended_image[0]] # Show the first image from the batch
titles = ["Image 1", "Image 2", "Blended Image"]
display_images(images, titles)
结果并不令人兴奋(就像 DALL-E 和其他生成模型中的此类自动编码器的成熟版本所能够做到的那样),但您明白了:结果是保留了两个图像的关键特征,例如两个个体,在背景中保留了卡车的特征。
矢量量化变分自动编码器 (VQ-VAE)
变分自动编码器提供了一个结构化的潜在空间,我们可以从中 (1) 采样,并 (2) 保持潜在空间中靠近的点与结果图像之间的相似性。这两个属性对于生成模型都至关重要,在生成模型中,我们希望从训练分布中采样数据并能够混合和匹配它们的特征。VAE 的缺点是,它通过学习平均图像(由其平均值表示)而不是完美地拟合输入数据来牺牲重建性能。这就是结果看起来模糊的原因。
矢量量化变分自动编码器 (VQ-VAE) 通过使用可以学习的离散码本或字母表来应对这一挑战,潜在空间中的每个条目都有一个代码。编码后,VQ-VAE 将选择与编码具有最接近欧几里得距离的代码,从而强制嵌入到模具中。在考虑文本时,这类似于简化为字母表的子集,允许优化器选择这些字符。
在代码中,这是使用维度 embedding_dim 和长度 num_embedding的可训练嵌入来实现的,即每个维度为 embedding_dim的代码数量。通过一系列卷积生成嵌入后,我们最终得到embedding_dim 4x4 像素的图像。(这需要使用 1x1 内核进行最终的 2D 卷积,以从我们在整个通道中使用的 256 个通道移动到 embedding_dim 个通道)。这些被扁平化和重新排列,因此我们最终得到 4x4xB(其中 B 是批次数)维度 embedding_dim 的嵌入。这些是我们码本中代码的候选者。
def vector_quantize(self, z):
B, C, H, W = z.shape # (B, embedding_dim, 4, 4)
z_flattened = z.permute(0, 2, 3, 1).reshape(-1, C) # (B*16, embedding_dim)
distances = (z_flattened.unsqueeze(1) - self.embeddings.weight.unsqueeze(0)).pow(2).sum(-1)
encoding_indices = distances.argmin(1) # (B*16,)
z_q = self.embeddings(encoding_indices).view(B, H, W, C).permute(0, 3, 1, 2) # Reshape back
z_q = z_q + (z - z_q).detach() # Preserve gradients
return z_q, encoding_indices.view(B, H, W) # Output is (B, 4, 4) indices然后我们可以计算每个候选者和码本条目之间的欧几里得距离。然后,我们获取与最小距离相对应的索引,并在码本中获取相应的条目。这需要一些重要的重新排列(使用 view(B,H,W,C))来恢复原始数据,并交换条目(使用 permute())。
由于梯度不会自然地通过这种查找,因此接下来是一个称为“直通估计器”的计算技巧:
z_q = z_q + (z - z_q).detach()如果你仔细观察,你会发现这个作实际上简化为 z_q = z。当我们使用 .detach() 从减法运算中删除梯度时,z_q 的梯度将表现为来自 z 的梯度,从而使函数 vector_quantize() 可微分。
以下是 VQ-VAE 的完整型号:
class ConvDQ_VAE(nn.Module):
def __init__(self, num_embeddings=512, embedding_dim=64):
super(ConvDQ_VAE, self).__init__()
# Encoder: Convolutions to extract features
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1), # (B, 64, 16, 16)
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), # (B, 128, 8, 8)
nn.ReLU(),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1), # (B, 256, 4, 4)
nn.ReLU()
)
self.encoder_output = nn.Conv2d(256, embedding_dim, kernel_size=1)
# Latent space: VQ codebook
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.embeddings = nn.Embedding(self.num_embeddings, self.embedding_dim)
nn.init.xavier_normal_(self.embeddings.weight)
# Decoder: Transposed convolutions for upsampling
self.decoder_input = nn.Conv2d(embedding_dim, 256, kernel_size=1)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1), # (B, 64, 8, 8)
nn.ReLU(),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), # (B, 32, 16, 16)
nn.ReLU(),
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1), # (B, 3, 32, 32)
nn.Sigmoid() # Output pixel values between 0 and 1
)
def encode(self, x):
x = self.encoder(x)
z = self.encoder_output(x)
return z
def vector_quantize(self, z):
B, C, H, W = z.shape # (B, embedding_dim, 4, 4)
z_flattened = z.permute(0, 2, 3, 1).reshape(-1, C) # (B*16, embedding_dim)
distances = (z_flattened.unsqueeze(1) - self.embeddings.weight.unsqueeze(0)).pow(2).sum(-1)
encoding_indices = distances.argmin(1) # (B*16,)
z_q = self.embeddings(encoding_indices).view(B, H, W, C).permute(0, 3, 1, 2) # Reshape back
z_q = z_q + (z - z_q).detach() # Preserve gradients
return z_q, encoding_indices.view(B, H, W) # Output is (B, 4, 4) indices
def decode(self, z):
x = self.decoder_input(z)
x = self.decoder(x)
return x
def forward(self, x):
z = self.encode(x)
z_q, encoding_indices = self.vector_quantize(z)
recon_x = self.decode(z_q)
# Commitment loss: Encourages the encoder's output to be close to the codebook
commitment_loss = F.mse_loss(z, z_q.detach()) # Updates the encoder
codebook_loss = F.mse_loss(z.detach(), z_q) # Updates the codebook
loss = commitment_loss + codebook_loss
return recon_x, loss, encoding_indices除了向量量化步骤之外,该模型还返回一个额外的损失函数和实际选择的码簿索引。loss 函数负责两件事:
- Commitment Loss:编码器嵌入应尽可能接近实际的 codebook 条目。在这里,.detach() 阻止渐变进入码本,允许编码器进行调整以更接近码本中的码。
- Codebook Loss:Codebook 条目应尽可能靠近编码器嵌入。在这里,.detach() 阻止梯度流入编码器,从而允许 codebook 嵌入发生变化。
现在,我们可以将这两者相加,并选择适当的权重(这里是 1 对 1),以强调 Codebook 或 Encoder 训练。
我们可以使用
# 初始化模型和优化器
model = ConvDQ_VAE(num_embeddings=4096, embedding_dim=128).to(device)
optimizer = optim.亚当(model.parameters(), lr=1 e-3)生成一个 1.9MB 的大型模型。
VQ-VAE 培训
训练一切如常,我们只需要考虑额外的损失函数:
epochs = 30
# Training loop
for epoch in range(epochs):
model.train()
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
# Move data to GPU if available
data = data.cuda() if torch.cuda.is_available() else data
# Forward pass
recon_x, commitment_loss, encoding_indices = model(data)
# Reconstruction loss (MSE)
recon_loss = F.mse_loss(recon_x,data) # torch.mean((recon_x - data) ** 2) # Using MSE for reconstruction loss
# Total loss: reconstruction loss + commitment loss
loss = recon_loss + commitment_loss
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader.dataset)在这里,comittment 和 codebook 损失被添加到我们从以前的自动编码器中知道的重建损失中。
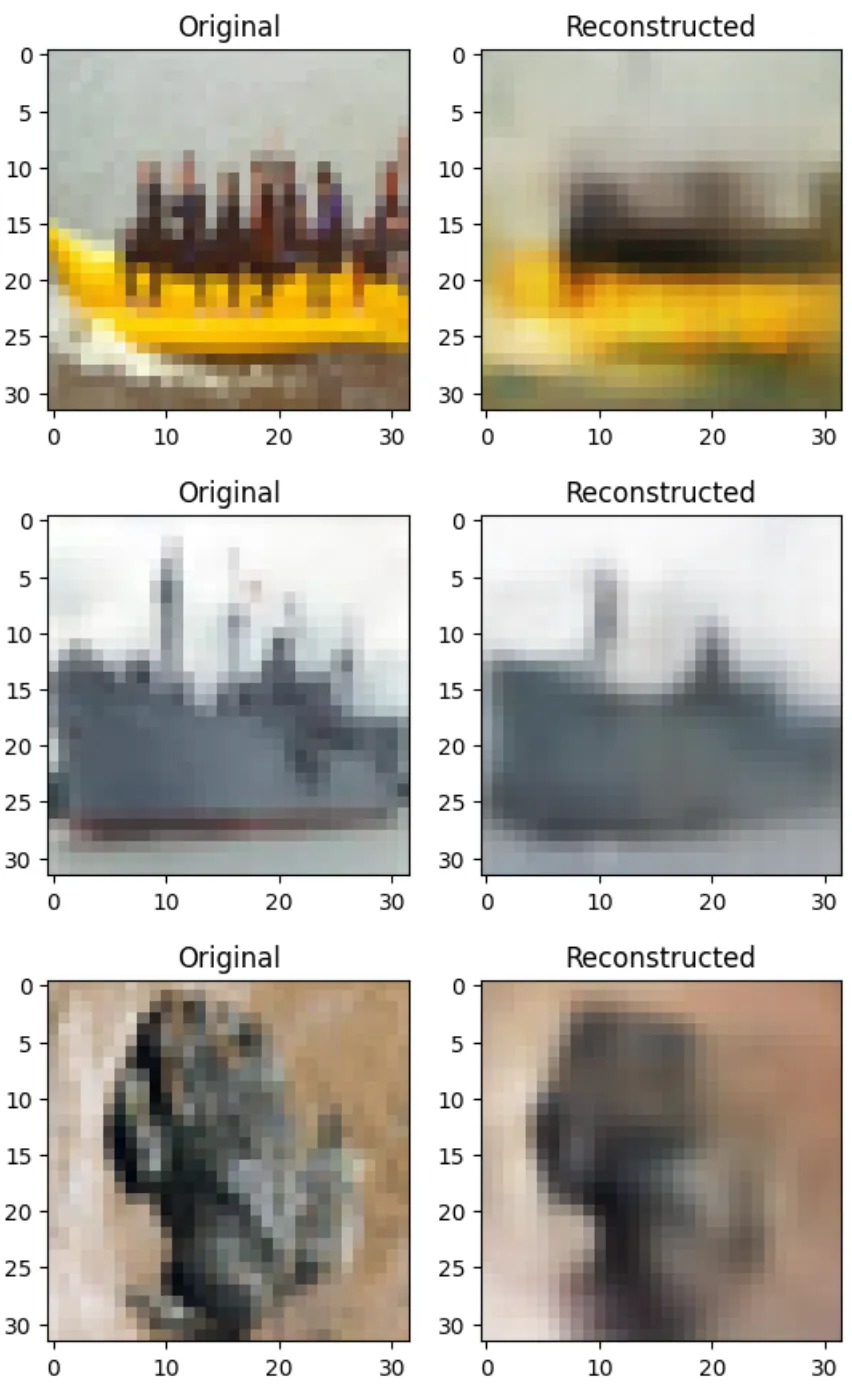
结果令人信服:重建比 VAE 的重建要模糊得多,并且仅使用 1.9MB 的可训练参数就可以获得相当好的重建。是的,结果比我们在上面使用 Autoencoder 获得的噪声要大一些,但我们能够以模型参数缩小 5 倍的大小来实现这一目标。此外,如果我们想使用 VQ-VAE 进行数据压缩,我们甚至不必提供整个潜在空间,而只需将索引放入码本中即可。这使得这种方法对 transformer 解码器等生成模型非常有吸引力,这些模型必须简单地生成一系列码本条目来生成一致的高分辨率图像。

我们还可以检查我们让模型学习的 4096 个代码中有多少实际使用了:
batch_of_images, _ = next(iter(train_loader))
batch_of_images = batch_of_images.to(device)
recon_x, loss, encoding_indices = model(batch_of_images)
encoding_indices.unique()通过上面的模型,事实证明只使用了极少数唯一的 codebook 条目。这可能是由于 encoder 本身非常丰富,使系统的行为更像一个使用单个潜在空间的标准 autoencoder。我们可以通过计算实际使用的码簿索引的概率分布,然后计算该分布的熵,来强制模型强调码簿使用的多样性:
p = encoding_indices.view(-1).bincount(minlength=self.num_embeddings).float() + 1e-6
p /= p.sum() # Normalize to a probability distribution
entropy_loss = - (p * p.log()).sum() # Encourage uniform code use
loss -= entropy_loss # Subtracting makes it a regularization term这可以在计算损失后立即添加到 forward() 函数中。尽管这有助于产生更多的码本使用,但我们似乎仍然不需要超过 32 个左右的代码。事实上,我们可以用 num_embeddings=32 训练模型,每个模型有 128 个维度。这会将参数减少到 1.4M 左右,并在训练 30 个 epoch 后产生以下结果:

我们可以看到 noise 进一步增加,但幅度不是太大。

















 2949
2949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









