







在当下,AI 大模型的热潮可谓席卷全球,从能与我们流畅对话、撰写文案的语言模型,到能根据只言片语创作出精美画作的图像生成模型,它们不断刷新着大众对人工智能的认知,也切实改变着众多行业的运作模式。
在这股大模型的旋风之中,计算机视觉技术的发展态势备受瞩目,不少人心中不禁泛起疑问:计算机视觉,这项致力于让计算机 “看懂” 世界的技术,是否已在 AI 大模型的冲击下步入瓶颈期? 事实并非如此,计算机视觉技术正凭借自身的独特优势不断创新,展现出强大的生命力与发展潜力。今天我将以下几个方面来带领大家快速了解计算机视觉这个领域。
一、计算机视觉:开启智能视觉大门
计算机视觉旨在让计算机模拟人类视觉系统,具备理解和分析视觉信息的能力。人类通过眼睛感知周围环境,大脑快速处理视觉信号,完成物体识别、距离判断和场景理解等任务。计算机视觉遵循类似的原理,利用复杂的算法和模型对图像和视频进行处理。
从工业生产线上的质量检测,到安防监控中的智能预警,再到自动驾驶汽车的核心技术,计算机视觉正以强大的实力重塑众多行业的发展格局。
二、核心概念:搭建视觉认知基石
像素与分辨率
像素是构成图像的最小单元,其数量和排列方式决定了图像的质量和细节。分辨率则指单位面积内像素的数量,分辨率越高,图像越清晰,能够呈现更多的细节。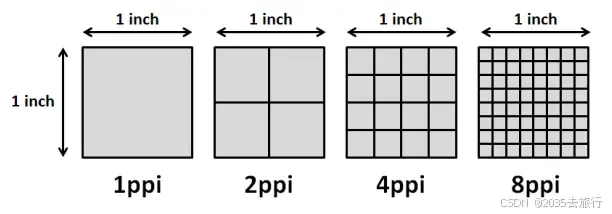
在计算机的眼里,每一个像素就是一个数字。
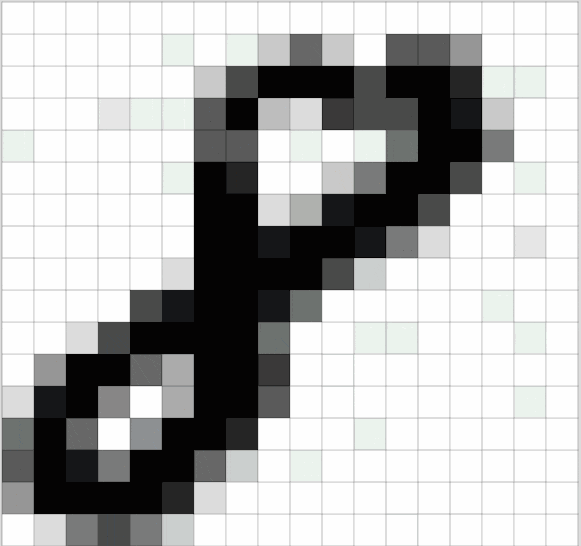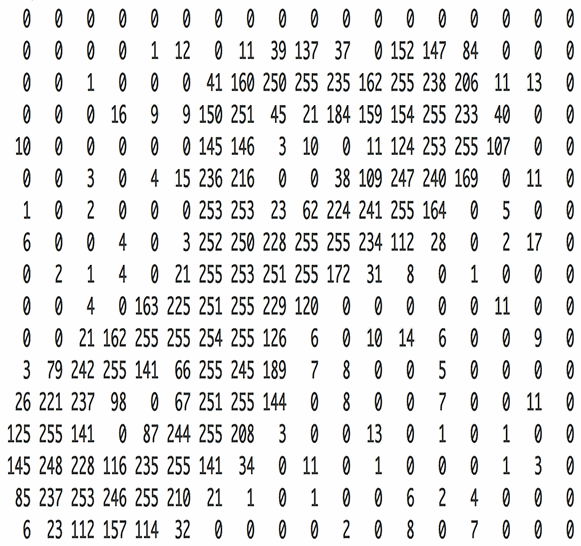
颜色模型
颜色模型是计算机用于描述和存储颜色的规则。常见的颜色模型有 RGB(红、绿、蓝)和 CMYK(青、品红、黄、黑)。
RGB颜色模型中,单个矩阵就扩展成了有序排列的三个矩阵,也可以用三维张量去理解。
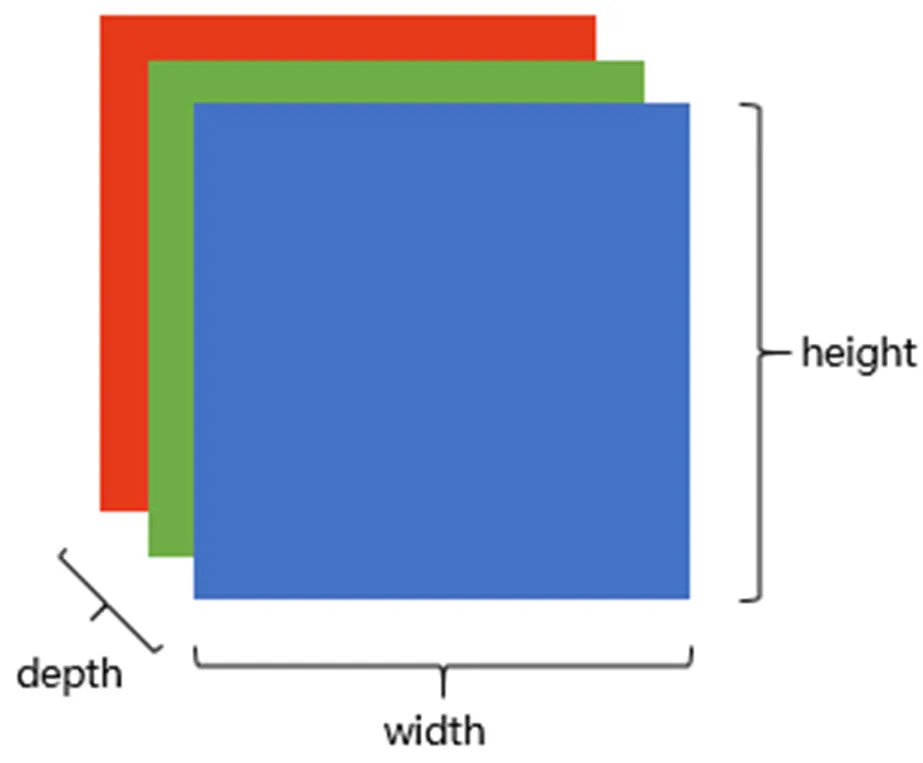
其中的每一个矩阵又叫这个图片的一个channel(通道),宽, 高, 深来描述。
边缘检测与特征提取
边缘检测
边缘检测是从图像中提取物体轮廓的关键技术。通过检测图像中像素值的突变,确定物体的边缘位置。常见的边缘检测算法有 Sobel 算子、Canny 算法等。
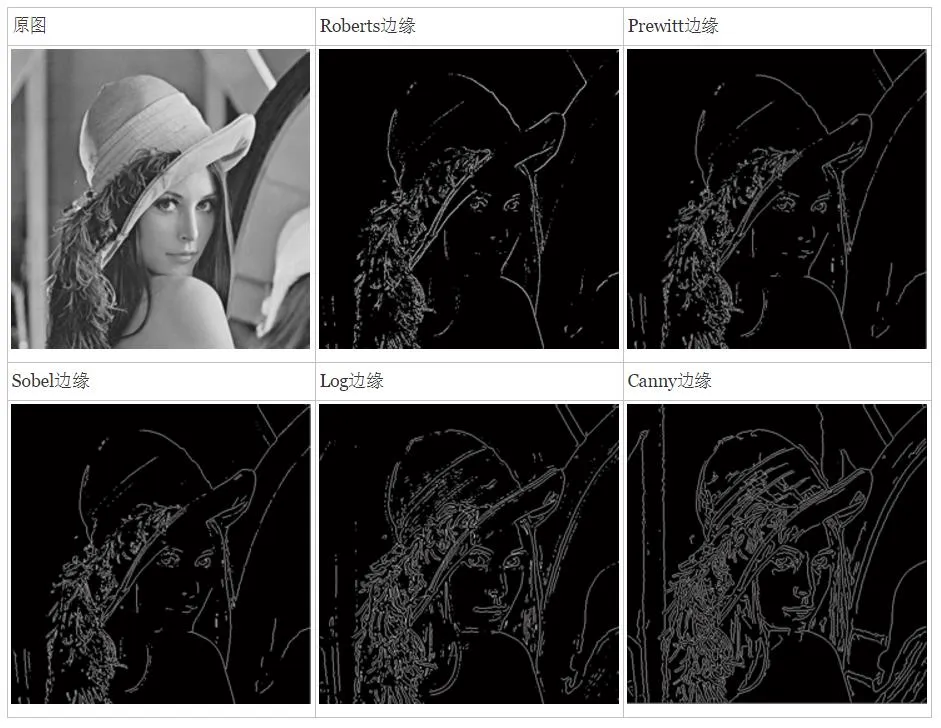
特征提取
特征提取则是从图像中提取具有代表性的特征,如物体的形状、纹理和颜色等。这些特征为后续的图像分类和识别提供了重要依据。例如,在人脸识别中,通过提取人脸的特征点,如眼睛、鼻子和嘴巴的位置和形状,来识别不同的人脸。
传统方法的特征提取

传统方法主要是手工设计特征,上面这张图展现的是Fast特征提取,从图像中选取一点P,以P为圆心画一个半径为3 pixel的圆;对圆周上的像素点进行灰度值比较,找出灰度值超过或低于给定阈值的像素;如果有连续n个像素满足条件,则认为P为特征点。一般n设置为9。
深度学习方法的特征提取
深度学习解决特征点提取的思路是利用深度神经网络提取特征点而不是手工设计特征,它的特征检测性能与训练样本、网络结构紧密相关。
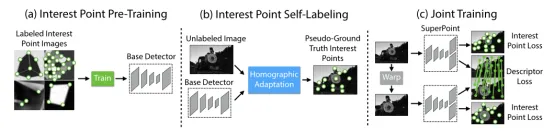
上面这张图是SuperPoint 网络结构示意图,该网络可分为三个部分,(a)是BaseDetector(特征点检测网络),(b)是真值自标定模块。(c)是SuperPoint网络,输出特征点和描述子。
绝对是2025年最强OpenCV零基础进阶教程!全景图像拼接、停车场车位识别、轮廓检测、OCR识别等计算机视觉项目统统搞定!
三、传统技术:早期探索的智慧结晶
20 世纪 50 年代,计算机能力有限,科学家就尝试让其 “看” 懂图像,聚焦边缘检测。60 - 70 年代,机器视觉兴起,霍夫变换等算法诞生,助力道路检测等。80 年代,特征提取技术大发展,SIFT 算法推动图像拼接等应用,字符识别与工业检测技术也取得显著进步 。
霍夫变换
霍夫变换是一种用于检测图像中几何形状的经典算法。它能够在图像中准确识别直线、圆等形状。
霍夫变换运用两个坐标空间之间的变换将在一个空间中具有相同形状的曲线或直线映射到另一个坐标空间的一个点上形成峰值,从而把检测任意形状的问题转化为统计峰值问题。
多说无益,直接看效果,下面是霍夫园变换的例子展示。
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('demo-circle.jpg',0)
img = cv2.medianBlur(img,5)
cimg = cv2.cvtColor(img,cv2.COLOR_GRAY2BGR)
circles = cv2.HoughCircles(img,cv2.HOUGH_GRADIENT,1,200,param1=50,param2=30,minRadius=0,maxRadius=0)
circles = np.uint16(np.around(circles))
for i in circles[0,:]:
# draw the outer circle
cv2.circle(cimg,(i[0],i[1]),i[2],(0,255,0),2)
# draw the center of the circle
cv2.circle(cimg,(i[0],i[1]),2,(0,0,255),3)
plt.subplot(121), plt.imshow(img, 'gray'), plt.title('src_img'), plt.axis('off')
plt.subplot(122), plt.imshow(cimg, 'gray'), plt.title('HoughCircles_img'), plt.axis('off')
plt.show()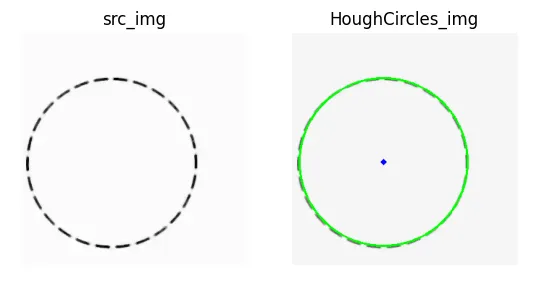
霍夫变换在实际当中的应用包括在道路检测中,检测图像中的直线来识别道路边界。

SIFT 特征匹配
SIFT(尺度不变特征变换)是一种强大的特征提取和匹配算法。它能够在不同尺度和旋转角度下提取图像的特征点,并进行匹配。
它是在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出、不会因光照、仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
SIFT特征提取步骤:
-
尺度空间的极值检测
-
关键点定位
-
方向分配
-
关键点描述子
首先是对原特征图下采样可以得到金字塔形状的多分辨率空间,作为特征金字塔,该特征金字塔可以方便提取出不同尺度的特征
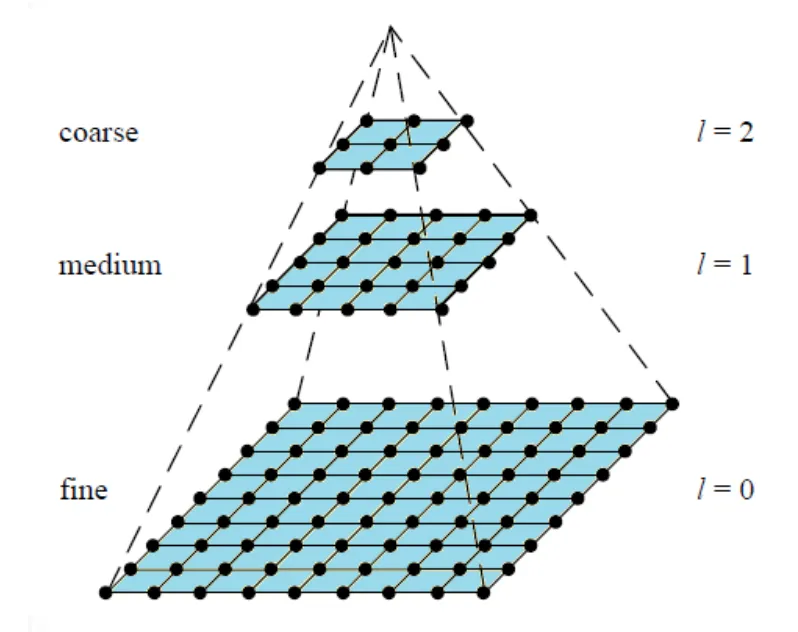
分别对每层特征金字塔中的特征图,用不同的高斯核进行卷积操作,就得到了高斯特征金字塔
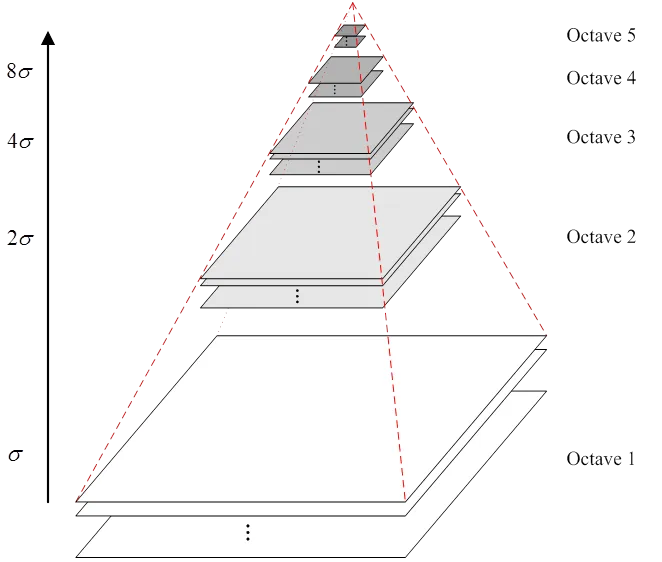
再对相邻的两层作差,进一步得到DOG

关键特征在不同的高斯模糊下更容易保留,在DOG特征图中表现为极值点。方向赋值与与关键点描述,与HOG特征类似,需要计算每个点的梯度,计算梯度直方图,最后得到的特征向量。
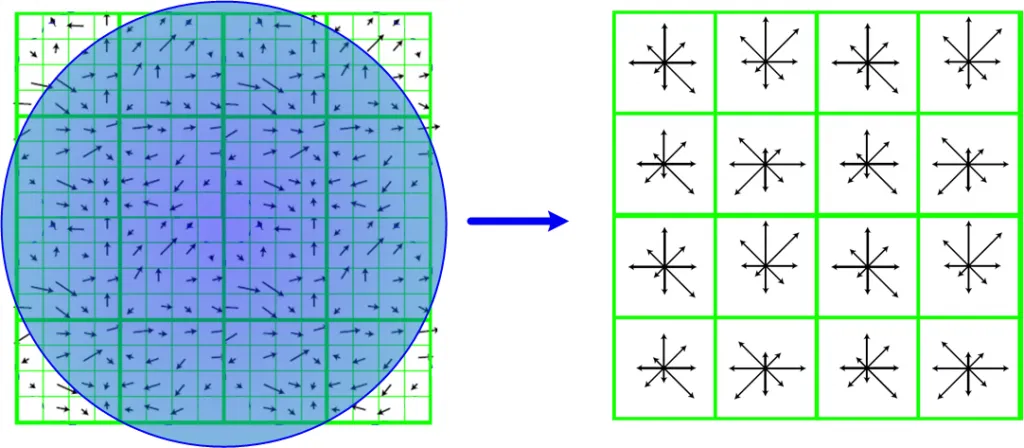
SIFT 特征匹配在图像拼接、目标识别等领域有广泛应用。下面我们来看一个SIFT算法在OpenCV中例子(一个函数直接搞定)。
img = cv2.imread('img/test.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
features2d.SIFT_create()
# SIFT检测器
sift = cv2.SIFT_create()
# 找出图像中的关键点
kp = sift.detect(gray, None)
# 在图中画出关键点
img = cv2.drawKeypoints(gray, kp, img)
# 计算关键点对应的SIFT特征向量
kp, des = sift.compute(gray, kp)
sift = cv2.SIFT_create()
kp1, des1 = sift.detectAndCompute(gray, None) # 这里还能一步到位,直接算出关键点以及关键向量
SIFT 算法还能实现实现图像的无缝拼接,感兴趣的同学可以动手实现试试。
计算机图形学与计算机视觉的关系
计算机图形学侧重于从无到有创建虚拟场景,而计算机视觉则专注于从真实图像中提取信息。两者看似不同,但在实际应用中有很多交叉。例如,渲染技术在计算机图形学中用于生成逼真的虚拟场景,在计算机视觉中则可以用于图像增强和修复,提高图像的质量。
四、应用变迁:不同时期的亮眼表现
早期应用:工业检测与字符识别
在计算机视觉发展的早期,主要应用于工业检测和字符识别领域。在工业生产中,计算机视觉系统能够快速检测产品的缺陷,提高生产效率和产品质量。
例如,在电子元件生产中,通过计算机视觉系统检测元件的尺寸、形状和表面缺陷。字符识别技术则可以将扫描的文档或图像中的文字转换为可编辑的文本,大大提高了文本处理的效率。
中期应用:人脸识别与物体跟踪
随着技术的发展,人脸识别和物体跟踪成为计算机视觉的重要应用领域。人脸识别技术广泛应用于安防、门禁和支付等场景。
例如,在机场安检中,人脸识别系统可以快速验证旅客的身份。

物体跟踪技术则可以在视频中实时跟踪目标物体的位置和运动轨迹,在智能交通和视频监控中有广泛应用。

近期应用:自动驾驶与智能医疗影像
近年来,自动驾驶和智能医疗影像分析成为计算机视觉的热门应用领域。自动驾驶汽车通过摄像头、雷达等传感器获取周围环境的信息,利用计算机视觉技术识别道路、车辆和行人,实现自动驾驶。

在医疗领域,计算机视觉技术可以帮助医生分析医学影像,如 X 光、CT 和 MRI 图像,辅助诊断疾病,提高诊断的准确性和效率。
五、深度学习:卷积神经网络引领变革
深度学习对计算机视觉产生了极为深刻的影响,它革新了模型训练模式,卷积神经网络(CNN)取代传统人工设计特征提取算法,提升训练效率与泛化能力;大幅提升算法性能,像 Faster R - CNN 等基于深度学习的算法在目标检测中更精准快速;极大拓展应用边界,还推动技术持续演进,优化 CNN 架构并促进多模态融合。
卷积神经网络(CNN)原理
卷积神经网络是深度学习在计算机视觉领域的核心技术。它通过卷积层、池化层和全连接层等结构,自动从大量图像数据中学习特征。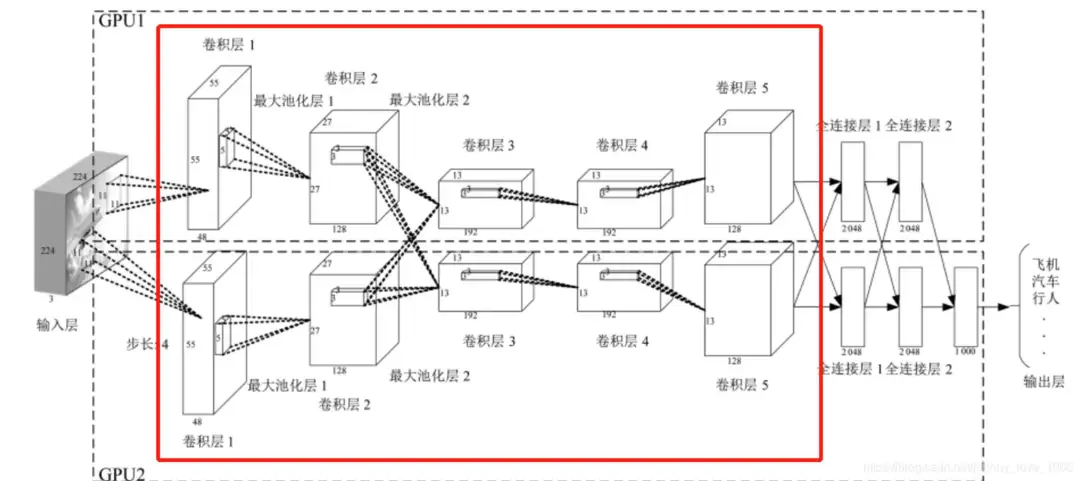
卷积层
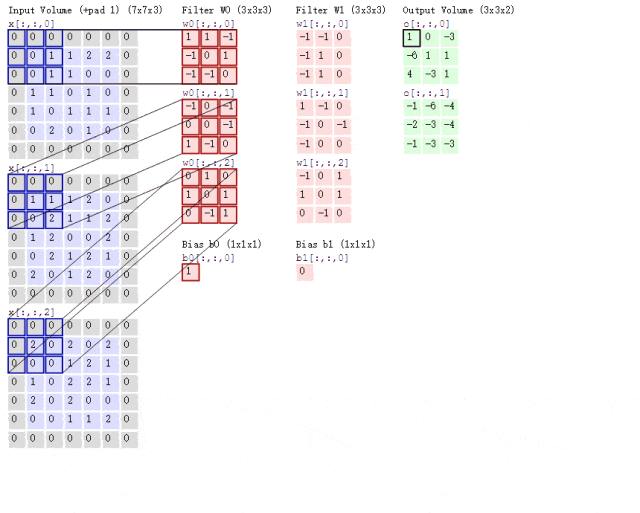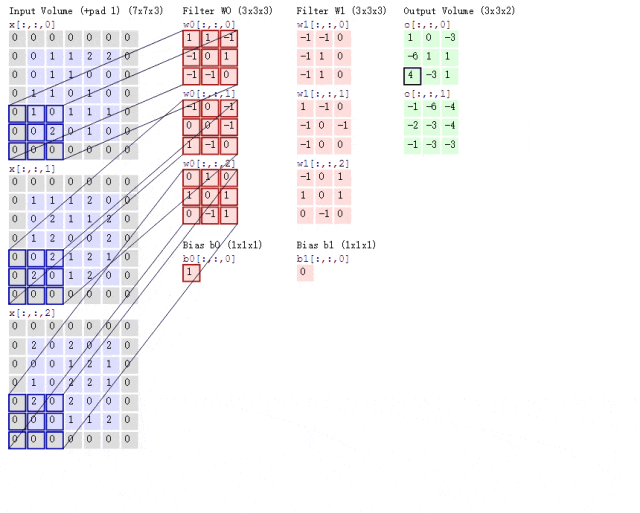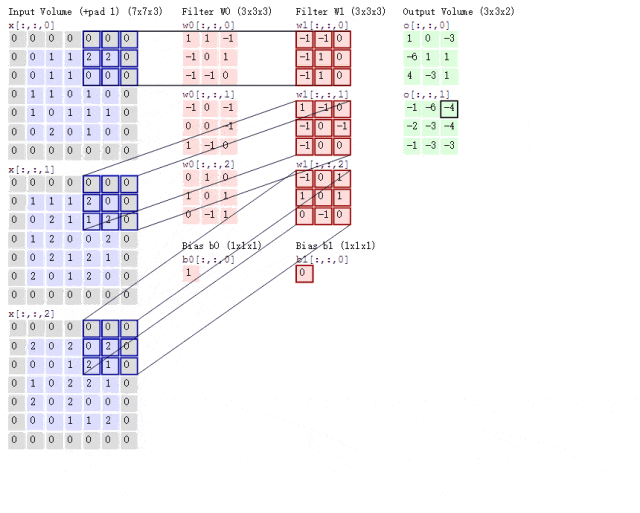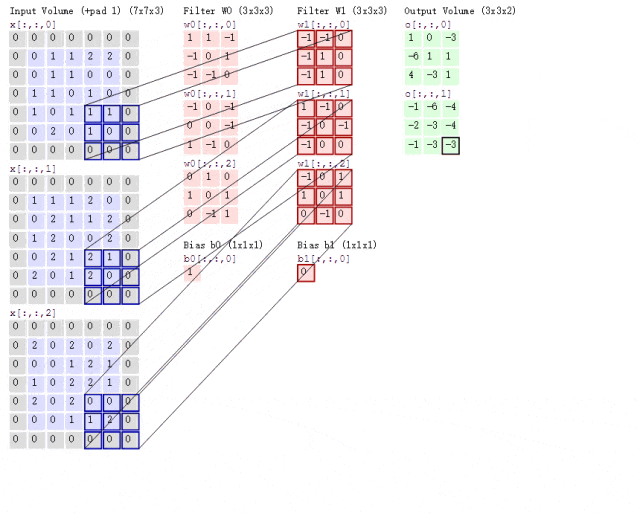
通过卷积核在图像上滑动,提取图像的局部特征
之前我们介绍过,彩色图片都是三个通道,也就是说一个彩色图片会有三个二维矩阵。此时我们使用两组卷积核,每组卷积核都用来提取自己通道的二维矩阵的特征,所以说我们只需要用两组卷积核的第一个卷积核来计算得到特征图就可以了,那么这个过程可见下图
池化层
用于降低特征图的维度,减少计算量
有几个卷积核就有多少个特征图,现实中情况肯定更为复杂,也就会有更多的卷积核,那么就会有更多的特征图,但是这么多特征并不都是我们所需要的。而这些多余的特征通常会给我们带来过拟合以及维度过高的问题。
为了解决这个问题,我们可以利用池化层。池化层就是当我们进行卷积操作后,再将得到的特征图进行特征提取,将其中最具有代表性的特征提取出来,可以起到减小过拟合和降低维度的作用,这个过程如下所示:
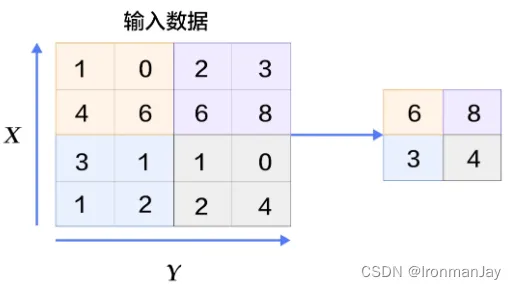
全连接层
将提取的特征进行分类
比如说我们现在在识别一张人脸图,现在我们已经通过卷积和池化提取到了这个人的眼睛、鼻子和嘴的特征,如果我想利用这些特征来识别这个图片是否是人的脑袋该怎么办呢?此时我们只需要将提取到的所有特征图进行“展平”,将其维度变为1 × N,这个过程就是全连接的过程,也就是说,此步我们将所有的特征都展开并进行运算,最后会得到一个概率值,这个概率值就是输入图片是否是人的概率,这个过程如下所示:
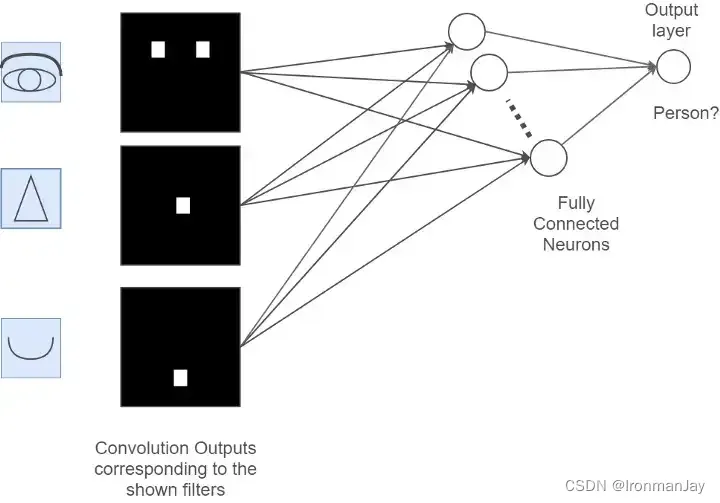
更多专业知识辛苦关助我了解后续计算机视觉知识! 

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









